Baixar para ler offline








































![Busca - bool, boost e agregações
GET /erbd/tweet,comment
/_search
{
"sort": [
{
"author": {
"order": "desc"
}
}
],
"size": 100,
"query": {
"bool": {
"should": [{
"match": {
"author": "anônimo"
}}, {
"match": {
"local": "Florianópolis"
}
}
]
} ,
"aggs" : {
"hashtags" : {
"terms" : { "field" : "author.raw"
}
}
https://gist.github.com/lhzsantana/f552751d
a153741657
83](https://image.slidesharecdn.com/erbd-180412124024/75/Uma-visao-sobre-Fast-Data-Spark-VoltDB-e-Elasticsearch-83-2048.jpg)




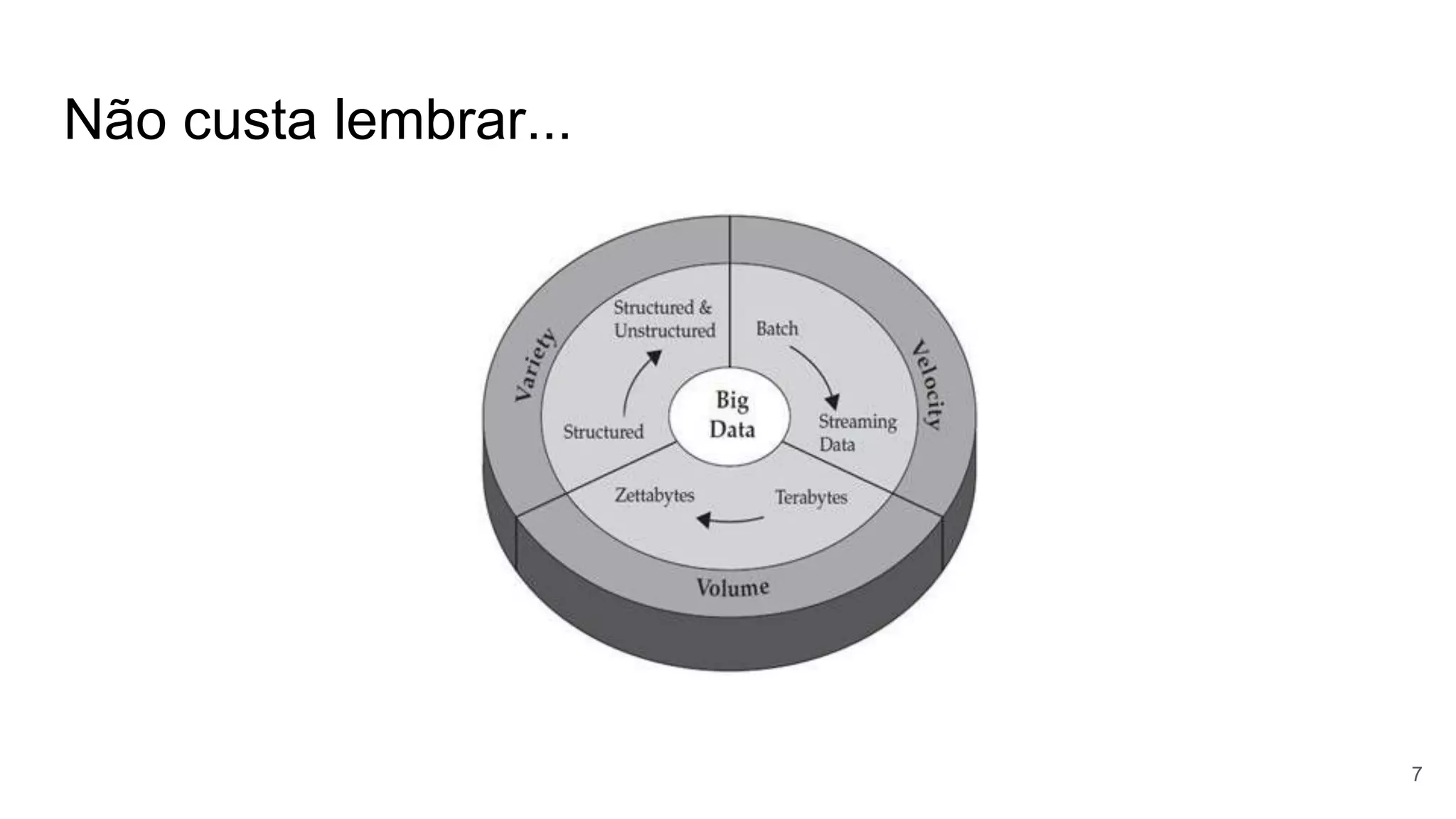
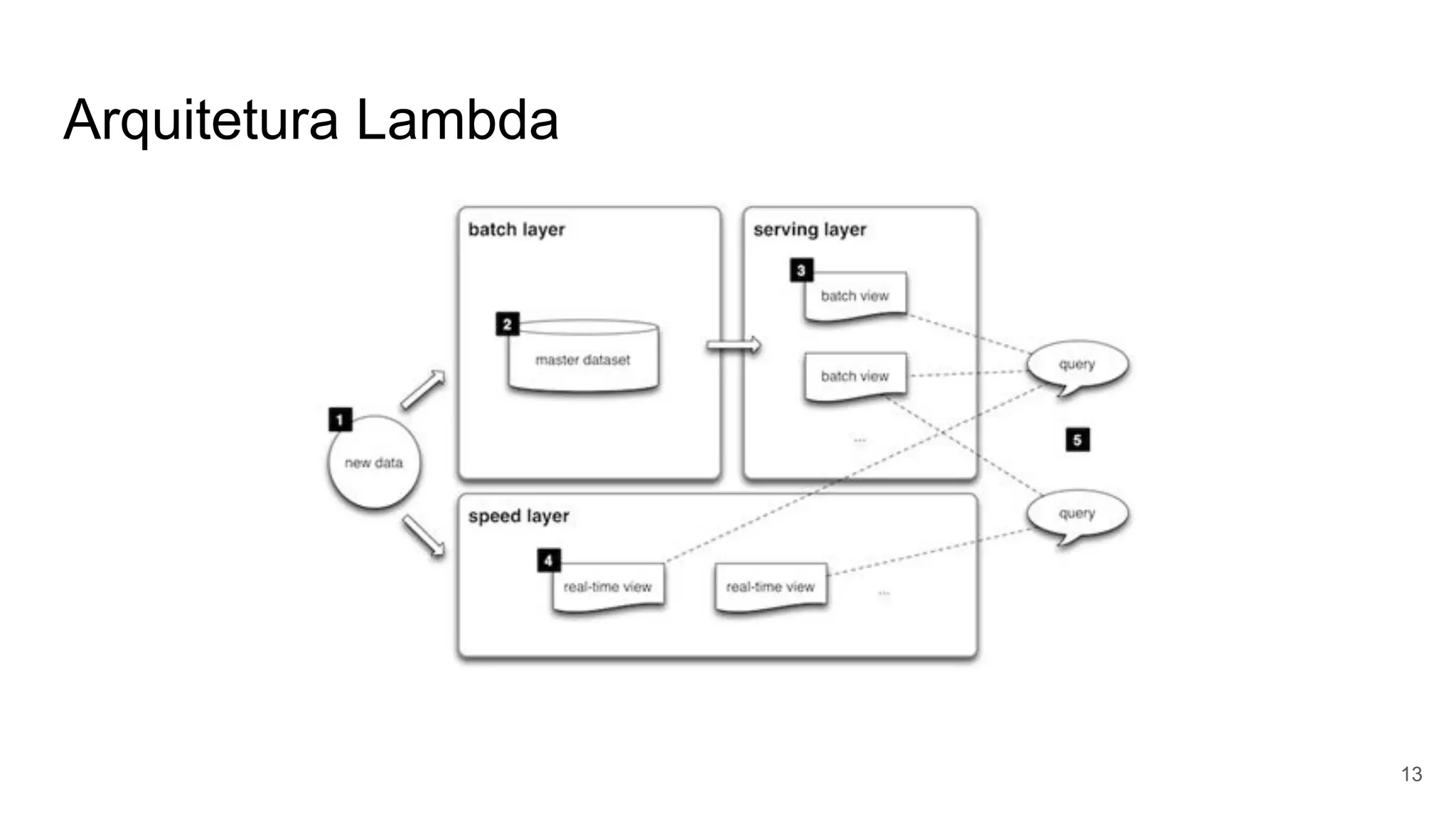
O documento apresenta uma visão abrangente sobre fast-data, abordando o processamento com Apache Spark, armazenamento com VoltDB e análises utilizando Elasticsearch. Inclui discussões sobre arquitetura, problemas enfrentados pelos bancos de dados tradicionais e exercícios práticos para aplicar os conceitos de big data. As conclusões destacam a importância da eficiência em tempo real e da flexibilidade nas soluções de armazenamento e análise de dados.















































