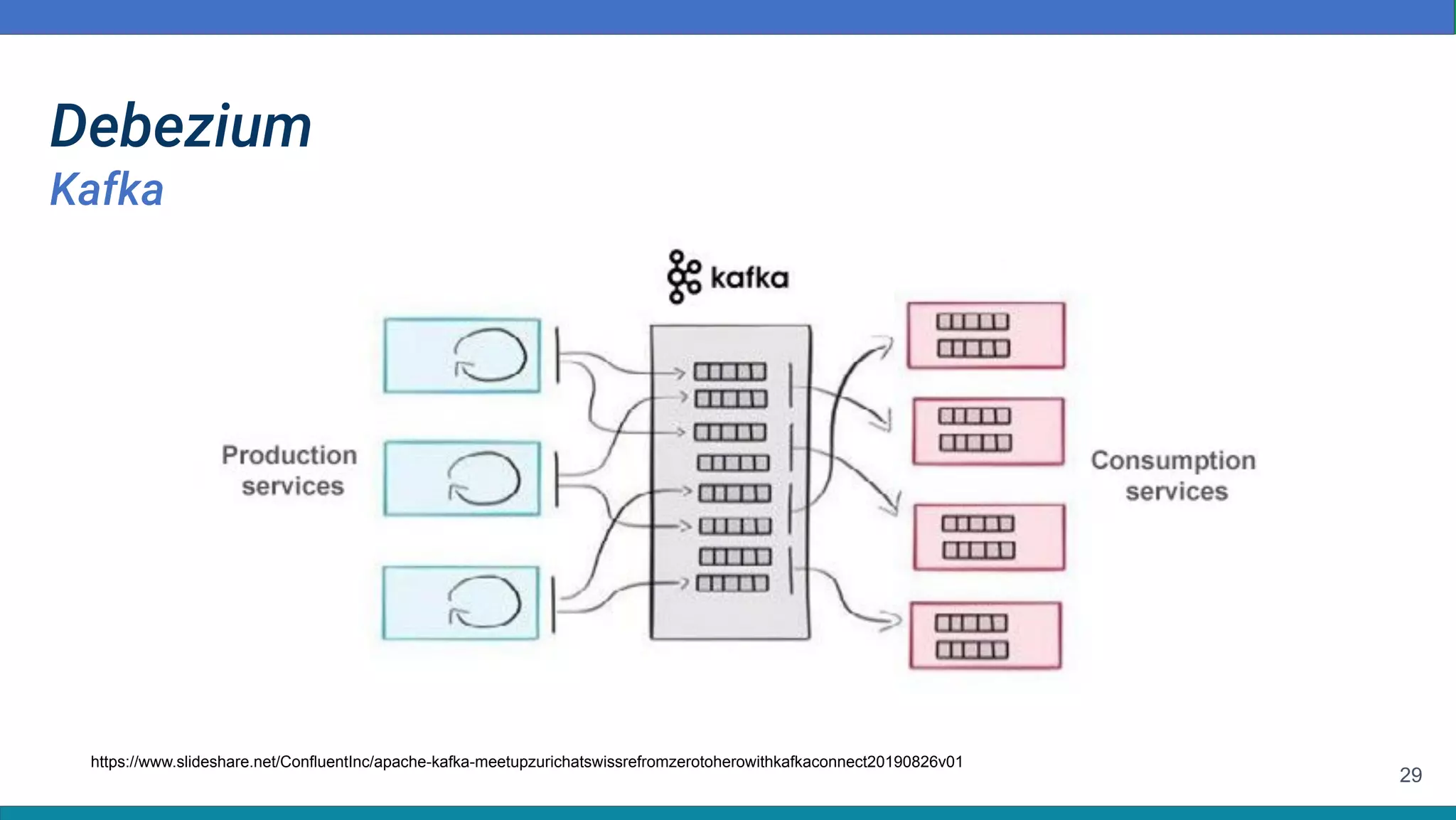
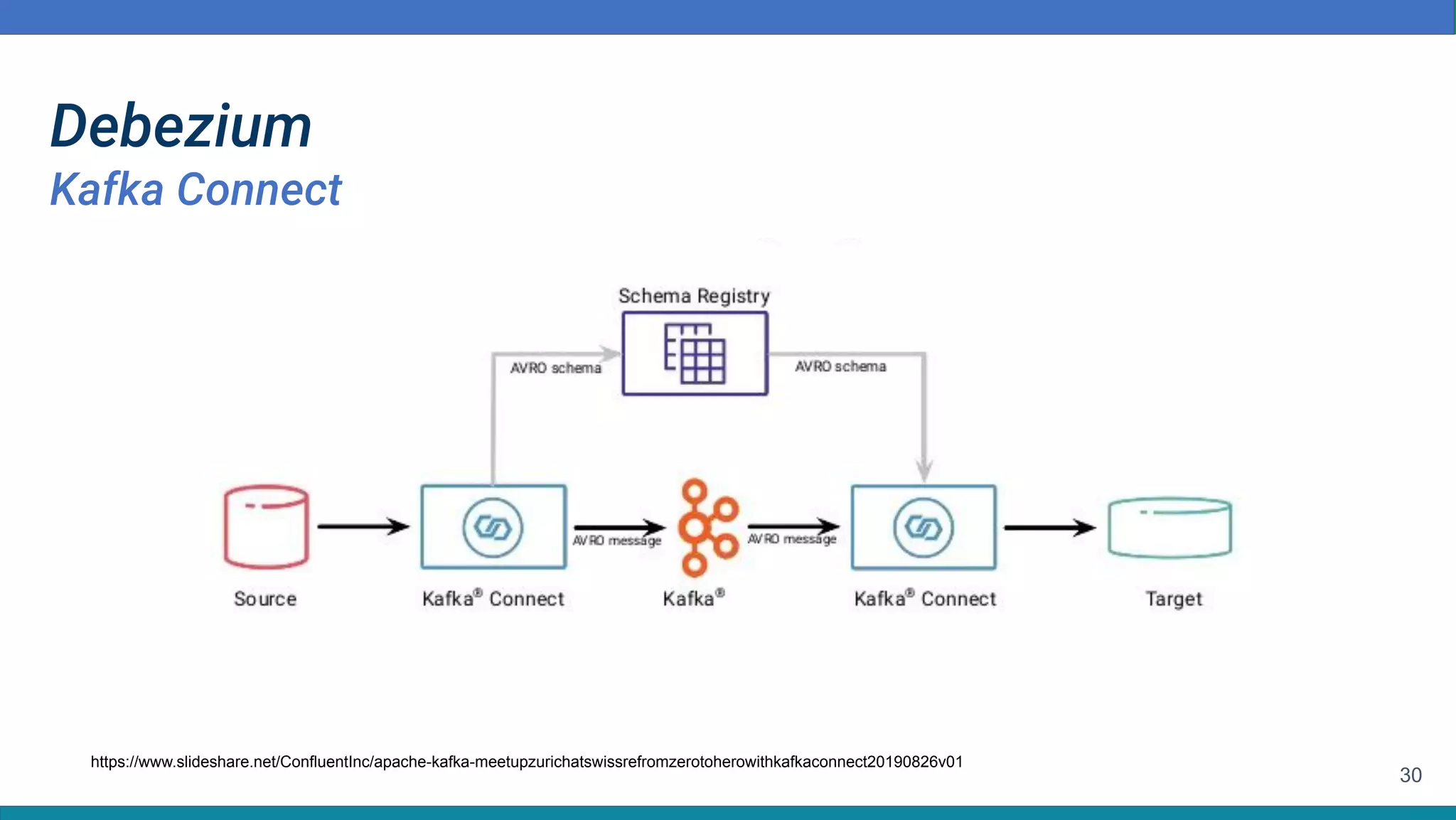
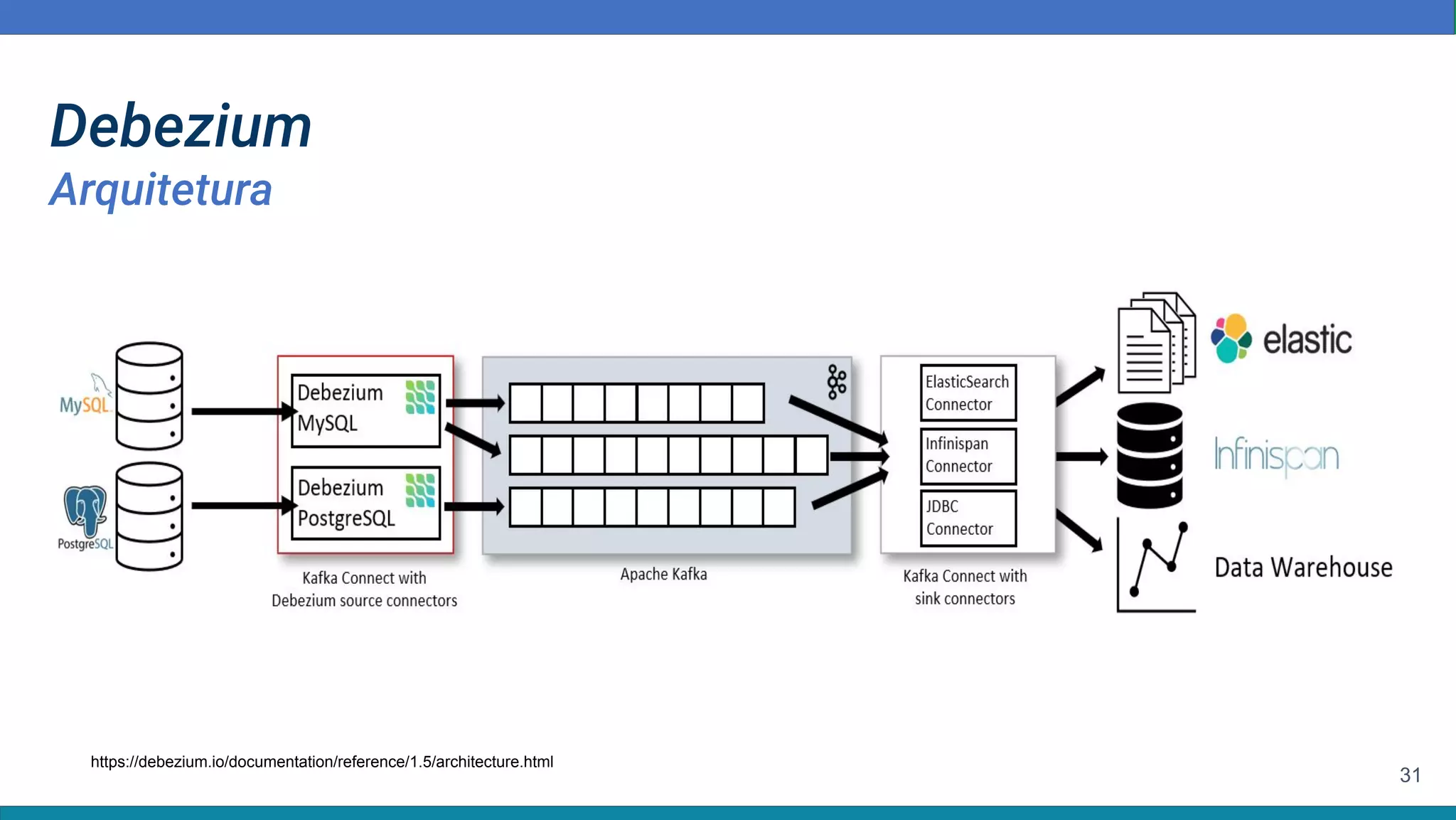
Baixar para ler offline























O documento discute vários tópicos relacionados a Big Data e Machine Learning, incluindo: 1) pontos atribuídos a diferentes tópicos; 2) definição de Data Lake; 3) batch e streaming de dados; 4) evolução do Big Data; 5) definição de Machine Learning.





































![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)

































