Visão Geral -Frameworks de Big Data
O Desafio do Big Data
• Volume, Velocidade e Variedade (Os 3 Vs): Os dados atuais são
maciços, chegam rapidamente e vêm em muitos formatos
(estruturado, semi-estruturado, não-estruturado).
• Sistemas tradicionais não conseguem armazenar e processar essa
escala de forma eficiente.
O Que São Frameworks de Big Data?
• Conjuntos de ferramentas e tecnologias projetadas para
armazenar, processar e analisar grandes volumes de dados de
forma distribuída e tolerante a falhas.
• Eles permitem que o trabalho seja dividido em vários
computadores (um cluster), processando os dados em paralelo.
3.
Framework Foco PrincipalVantagens Chave
Apache Hadoop
Armazenamento (HDFS) e
Processamento Batch
(MapReduce)
Tolerância a falhas, custo-
benefício.
Apache Spark
Processamento em memória,
Batch, Stream, SQL, ML
Velocidade (muito mais
rápido que Hadoop
MapReduce), versatilidade.
Apache Flink
Processamento de Stream
(Tempo Real)
Baixa latência, estado
gerenciado.
Principais Frameworks (Os Gigantes)
4.
Exemplo de Código1 - Contagem de Palavras com
PySpark
Apache Spark: O "Canivete Suíço" do Big Data
O Apache Spark é o framework mais popular hoje. Ele é
rápido porque processa dados em memória e é muito
versátil.
Caso de Uso: Contagem de Palavras (Word Count)
Um clássico do Big Data para ilustrar o processamento
distribuído. Queremos contar a frequência de cada
palavra em um grande arquivo de texto.
6.
Exemplo deCódigo 2 - Análise Estruturada com Spark SQL
Spark SQL e DataFrames
Para dados mais estruturados (como CSV, JSON, Bancos de Dados),
o Spark introduziu os DataFrames, que são coleções de dados
organizadas em colunas. Eles permitem usar comandos SQL e são
muito mais otimizados.
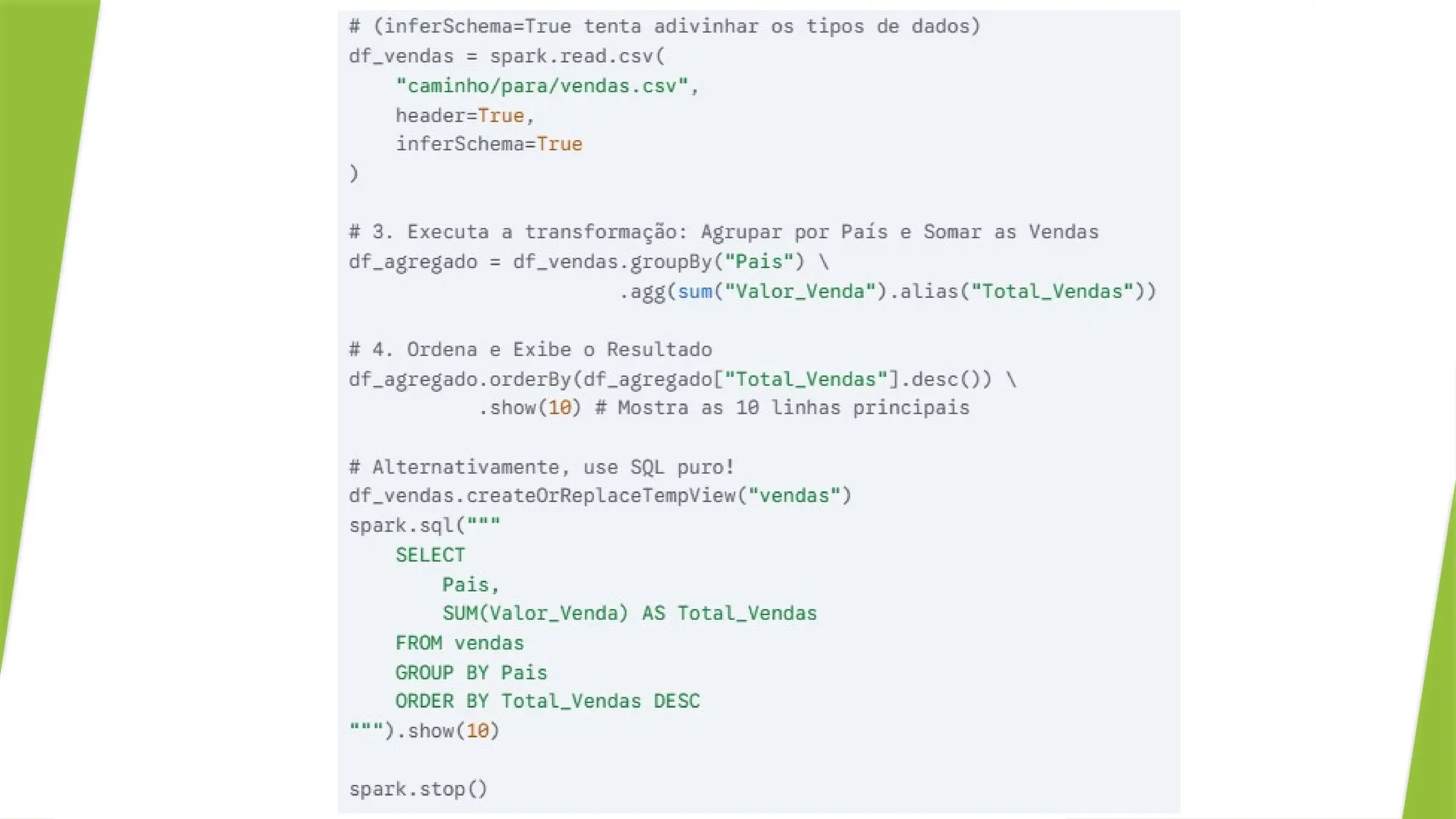
Caso de Uso: Filtragem e Agregação em Dados de Vendas
Queremos encontrar a soma total de vendas por país a partir de
um arquivo CSV.
8.
Visão Geral- Stream de Dados: Definição e Fontes
O Paradigma de Processamento de Dados
Tradicionalmente, os dados eram processados em lotes (Batch Processing):
acumular, processar e obter resultados (Ex: Relatório mensal de vendas).
O Stream de Dados (Data Streaming) inverte esse modelo: os dados são
processados à medida que são gerados, em tempo real ou quase real.
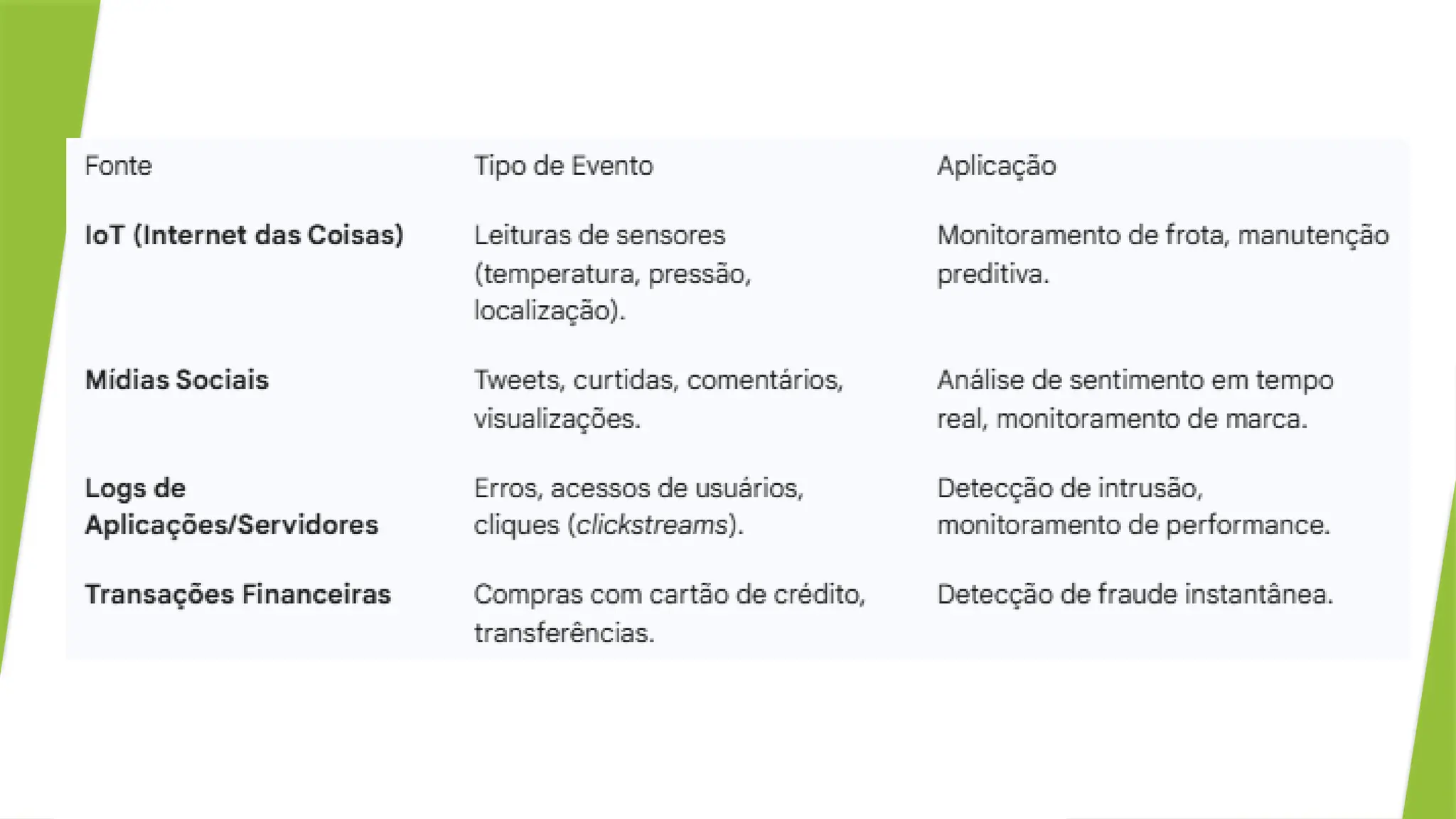
Definição de Stream de Dados
Um stream de dados é uma sequência contínua e infinita de eventos,
gerada por uma fonte em alta velocidade.
Cada evento (ou registro) é pequeno e é tratado individualmente (Ex:
"Transação X ocorreu agora", "Sensor Y leu 25°C agora").
O foco é em baixa latência: o tempo entre a geração do dado e a
obtenção de um insight deve ser mínimo.
10.
Exemplo deCódigo 1 - Arquitetura de Streams (Kafka + Spark)
O Ecossistema Típico de Streaming
Para lidar com streams, precisamos de duas peças-chave:
Broker/Fila de Mensagens: Gerencia a ingestão, a persistência e a
distribuição dos eventos. O Apache Kafka é o líder de mercado.
Motor de Processamento de Streams: Processa os dados de forma
contínua. O Apache Spark Streaming (ou Structured Streaming) é
um motor popular.
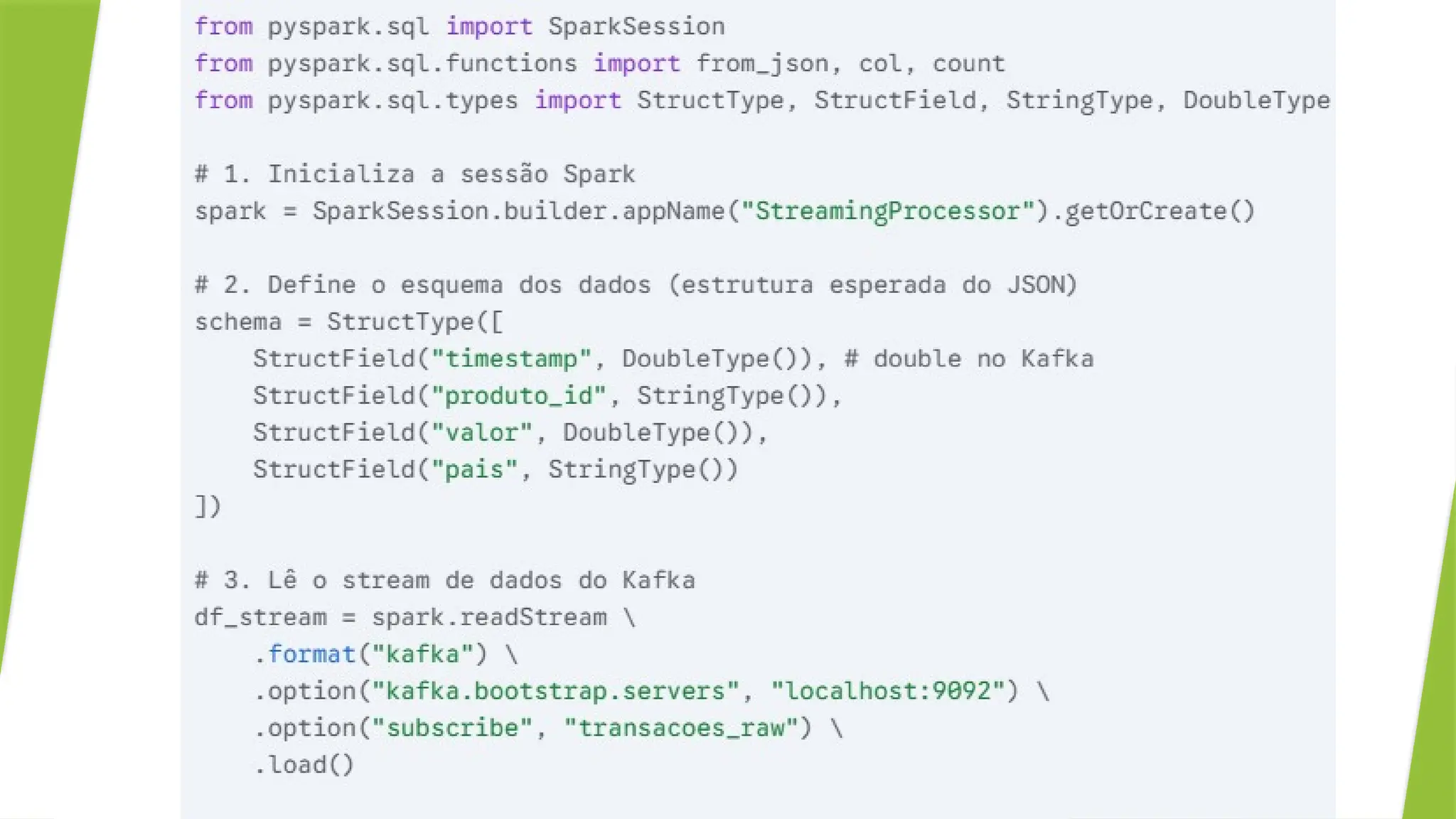
Exemplo de Produtor em Python (Publicando no Kafka)
Este código simula uma fonte, enviando mensagens de "transações"
para um tópico do Kafka.
12.
Exemplo deCódigo 2 - Processamento de Streams com PySpark
Structured Streaming
Apache Spark Structured Streaming
É uma API de alto nível no Spark que trata um stream de dados como uma
tabela que é continuamente anexada. Isso permite usar as mesmas operações
de DataFrames (SQL) para processamento em tempo real.
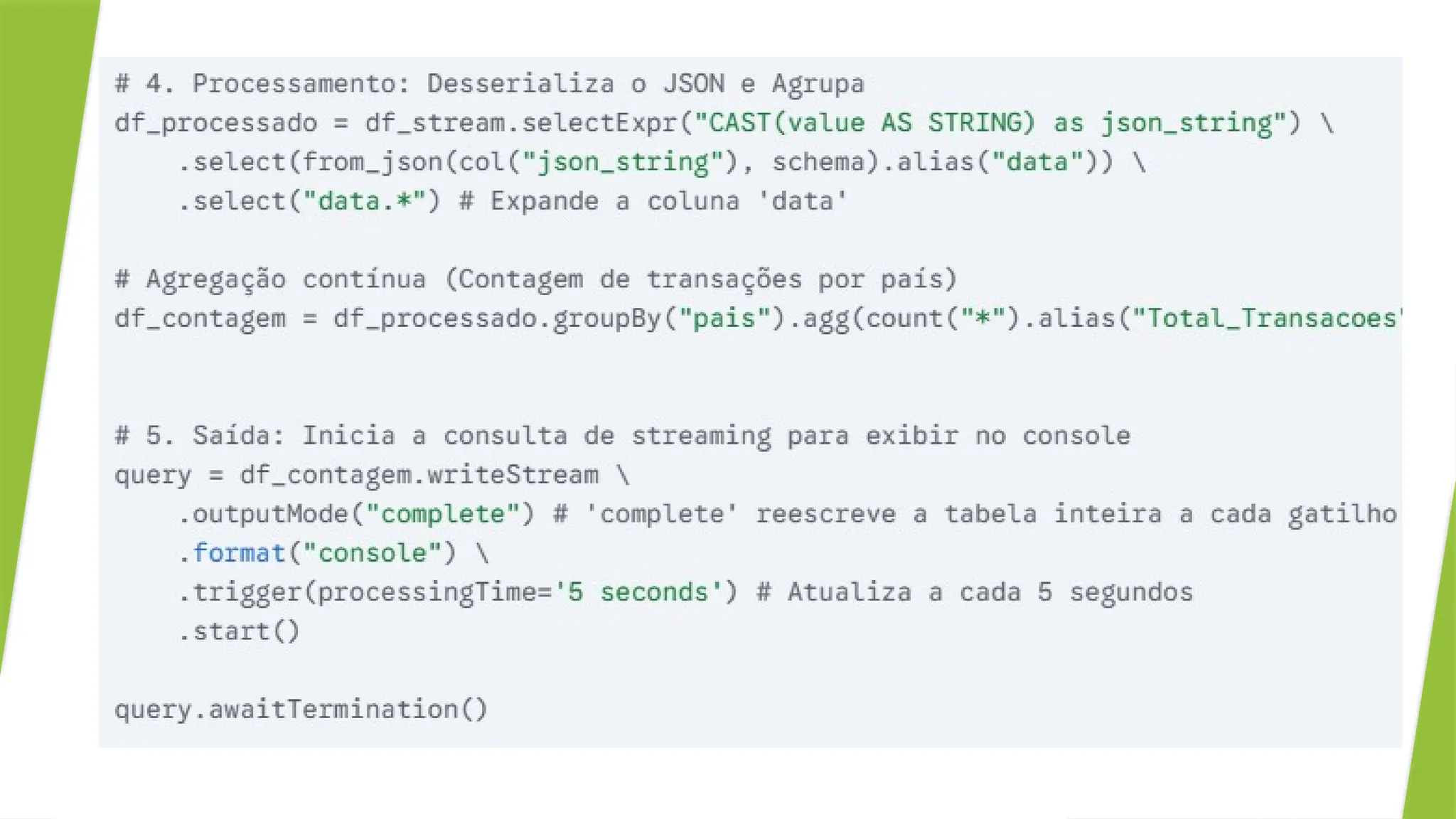
Caso de Uso: Contagem Contínua de Transações por País
Queremos manter uma contagem atualizada do número de transações
recebidas, agrupadas por país.
15.
Overview -Frameworks de Stream de Big Data
O Desafio do Big Data em Tempo Real
Processar streams de Big Data (alta velocidade, alto volume) exige mais do
que um simples consumidor de fila. Requer frameworks especializados que
garantam:
Tolerância a Falhas (Fault Tolerance): Processamento não pode parar se
um nó falhar.
Semântica de Processamento: Garantia de que cada evento é
processado exatamente uma vez (exactly-once).
Gerenciamento de Estado (State Management): Capacidade de lembrar
informações passadas (ex: o total de vendas nos últimos 5 minutos).
Tempo de Evento (Event Time): Processar os dados na ordem em que
ocorreram, e não na ordem em que chegaram.













![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Datafest 2018] Apache Spark Structured Stream - Moedor de dados em tempo qua...](https://cdn.slidesharecdn.com/ss_thumbnails/datafest2018-apachesparkstructuredstreammoedordedadosemtempoquasereal-181101180406-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[DEVFEST] Apache Spark Casos de Uso e Escalabilidade](https://cdn.slidesharecdn.com/ss_thumbnails/apachespark-casosdeusoeescalabilidade-171106111137-thumbnail.jpg?width=640&height=640&fit=bounds)










