Baixar para ler offline










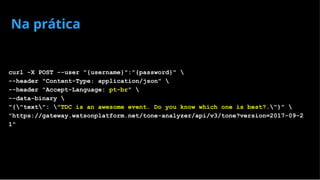



![Na prática: Spark Context
val sc = new SparkContext("local[*]", "My App")
library(SparkR, lib.loc = c(file.path(Sys.getenv("SPARK_HOME"), "R", "lib")))
sparkR.session(master = "local[*]", sparkConfig = list(spark.driver.memory = "20g"))
# my_script.py
sc = SparkContext("local", "My App")](https://image.slidesharecdn.com/tdc2018bigdata-180418173353/85/IBM-Watson-Apache-Spark-ou-TensorFlow-25-320.jpg)
![Na prática: Contagem de palavras
package com.tdc.spark
import org.apache.spark._
import org.apache.spark.SparkContext._
import org.apache.log4j._
object WordCountTDC{
def main(args: Array[String]) {
val sc = new SparkContext("local", "WordCountTDC")
val input = sc.textFile("../someBook.txt")
val words = input.flatMap(x => x.split("W+"))
val lowerWords = words.map(x => x.toLowerCase())
val wordCount = lowerWords.map(x => (x, 1)).reduceByKey( (x,y) => x + y )
val wordCountSorted = wordCount.map( x => (x._2, x._1) ).sortByKey()
wordCountSorted.foreach(println)
}
}](https://image.slidesharecdn.com/tdc2018bigdata-180418173353/85/IBM-Watson-Apache-Spark-ou-TensorFlow-26-320.jpg)

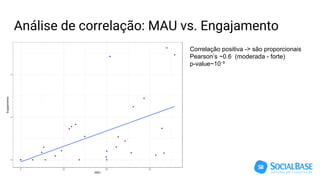
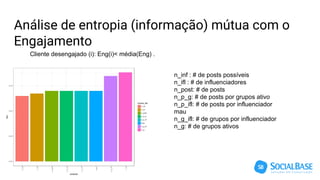
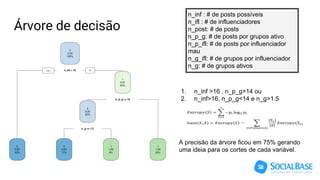

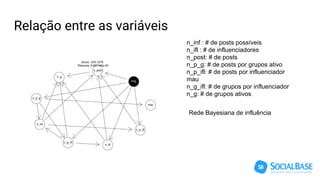
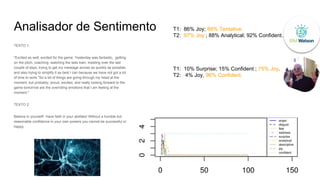

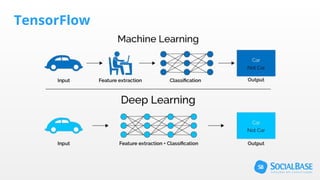
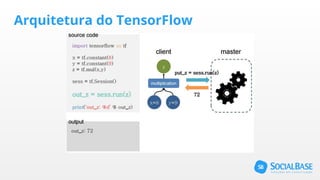
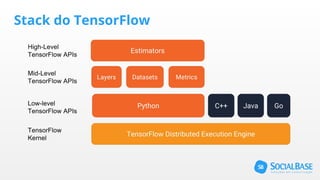
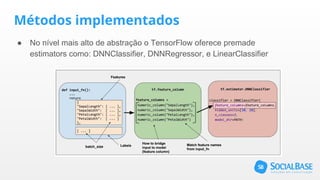
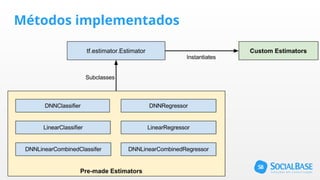

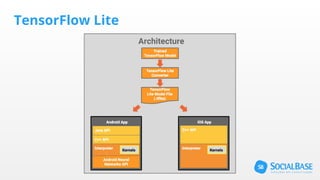


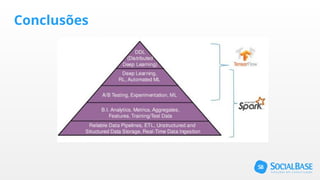




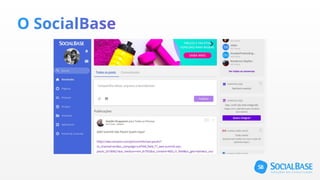
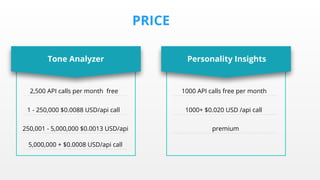
O documento discute o uso de ferramentas de big data e machine learning na SocialBase. Apresenta o IBM Watson, Apache Spark e TensorFlow, comparando suas funcionalidades e preços. Conclui que o Spark é melhor para prototipagem e produção devido ao seu baixo custo e escalabilidade, enquanto o Watson facilita protótipos mas tem alto custo para produção.

![[DTC21] Raphael Castilho - Começando com Inteligência Artificial e Machine Le...](https://cdn.slidesharecdn.com/ss_thumbnails/iaemachine-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)













































