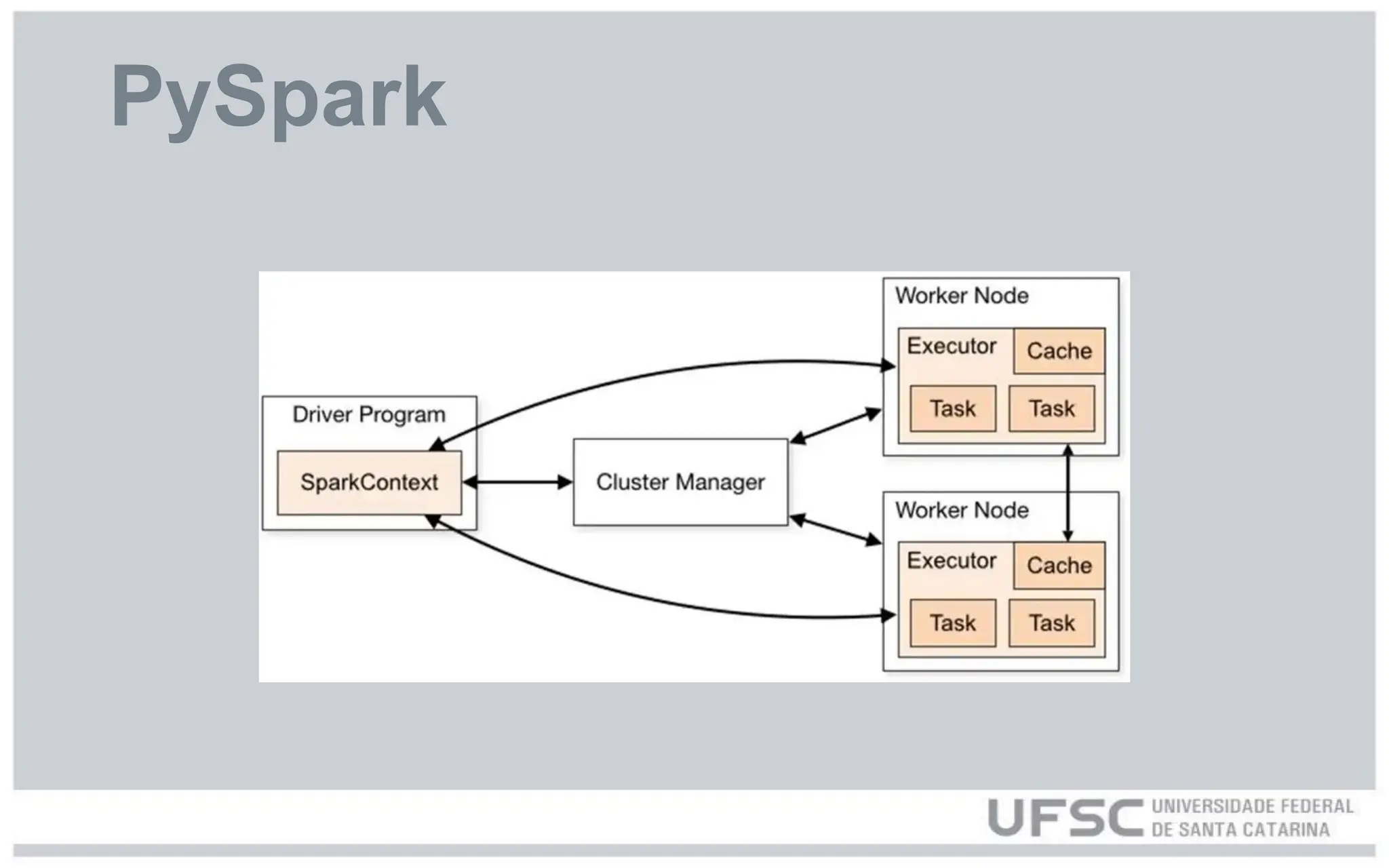
● PySpark éa API em Python do Apache Spark, uma plataforma de
processamento distribuído usada para manipular grandes volumes de
dados com alta performance.
● Permite trabalhar com DataFrames e RDDs de forma paralela em clusters,
suportando operações como filtragem, agregação, joins e transformação de
dados.
● Integra-se facilmente com Jupyter, Google Colab e ambientes como
Databricks, sendo ideal para análise de dados, machine learning e ETL em
larga escala.
● Funciona localmente ou em clusters (YARN, Kubernetes, EMR) e pode
ler/gravar dados em diversos formatos: CSV, JSON, Parquet, Delta Lake,
entre outros.
PySpark
Transformações e actions- Lazy
evaluation
● Podemos encadear transformações, sem que o Spark tenha que
executá-las
● O Spark pode otimizar a execução inteira com base no plano
completo.
● É possível evitar leituras e cálculos desnecessários.
● Ele permite executar apenas o necessário, mesmo com datasets
enormes.
14.
Transformações - Map
●Map - Aplica uma transformação linha a linha.
from pyspark.sql.functions import col
df.select((col("valor") * 2).alias("valor_dobrado")).show()
15.
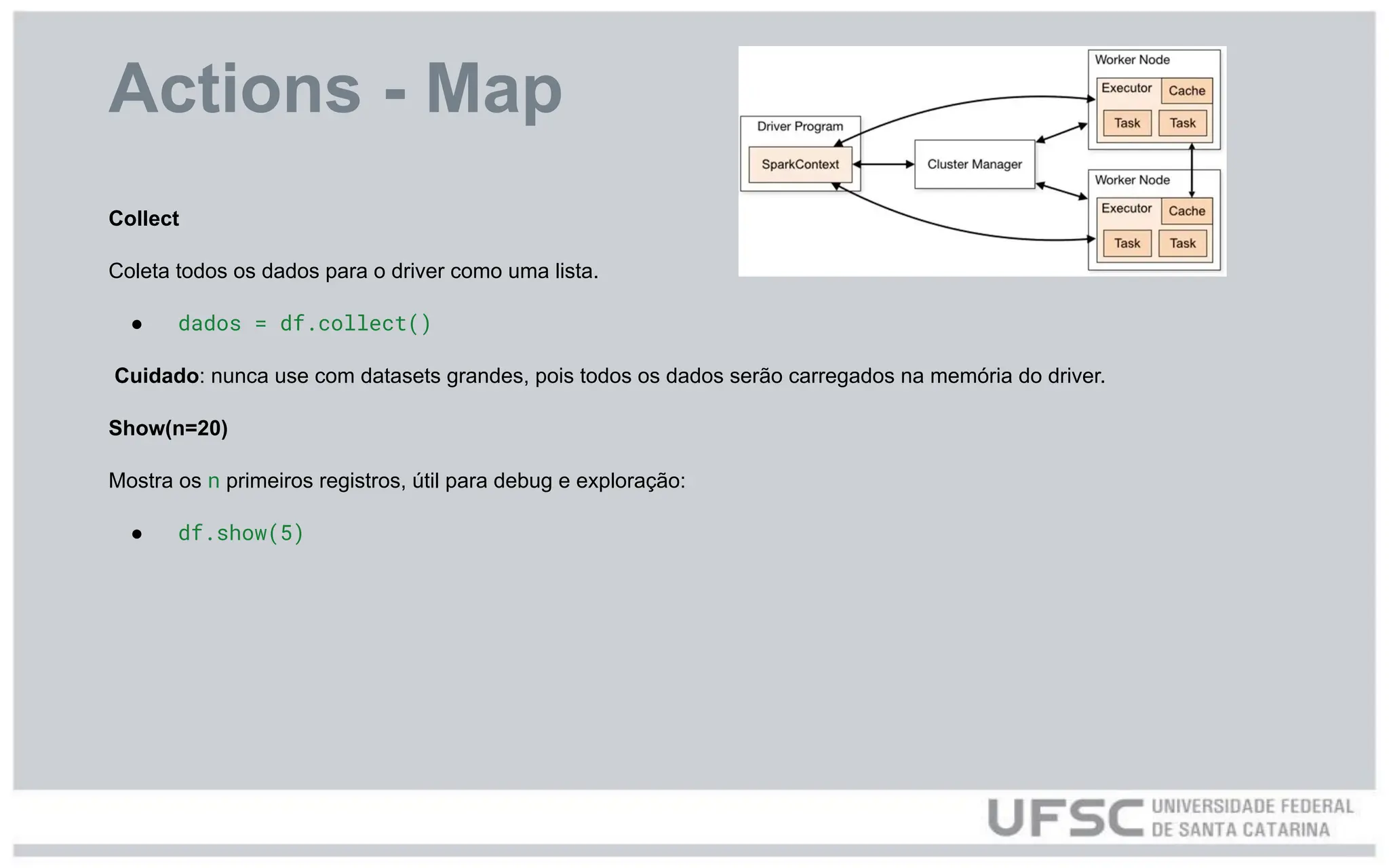
Actions - Map
Collect
Coletatodos os dados para o driver como uma lista.
● dados = df.collect()
Cuidado: nunca use com datasets grandes, pois todos os dados serão carregados na memória do driver.
Show(n=20)
Mostra os n primeiros registros, útil para debug e exploração:
● df.show(5)
SQL
O Spark suportaSQL ANSI:
df = spark.read.option("header", "true").csv("dados/clientes.csv")
df.createOrReplaceTempView("clientes")
spark.sql("""
SELECT cidade, COUNT(*) as total
FROM clientes
GROUP BY cidade
ORDER BY total DESC
""").show()
18.
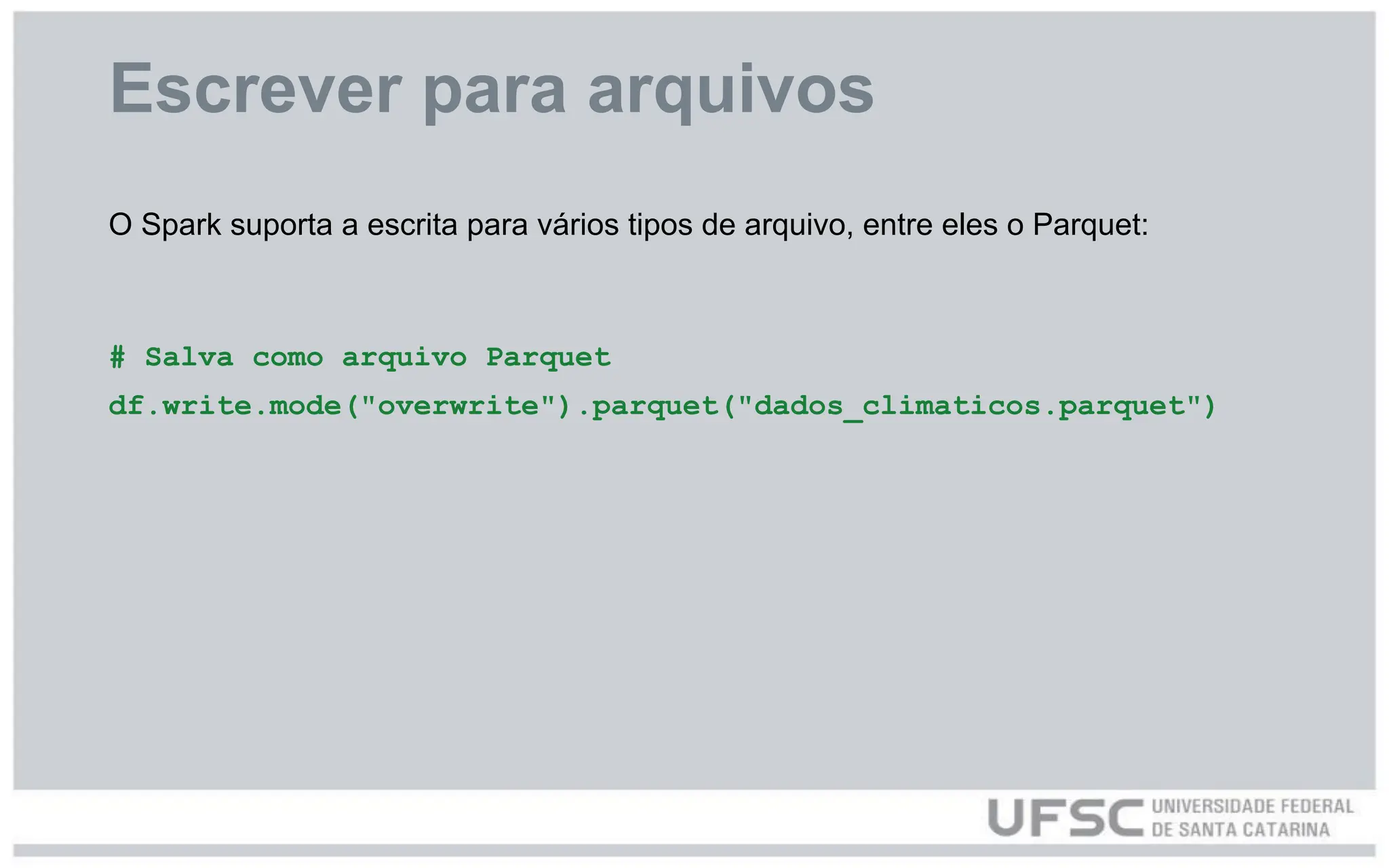
Escrever para arquivos
OSpark suporta a escrita para vários tipos de arquivo, entre eles o Parquet:
# Salva como arquivo Parquet
df.write.mode("overwrite").parquet("dados_climaticos.parquet")
19.
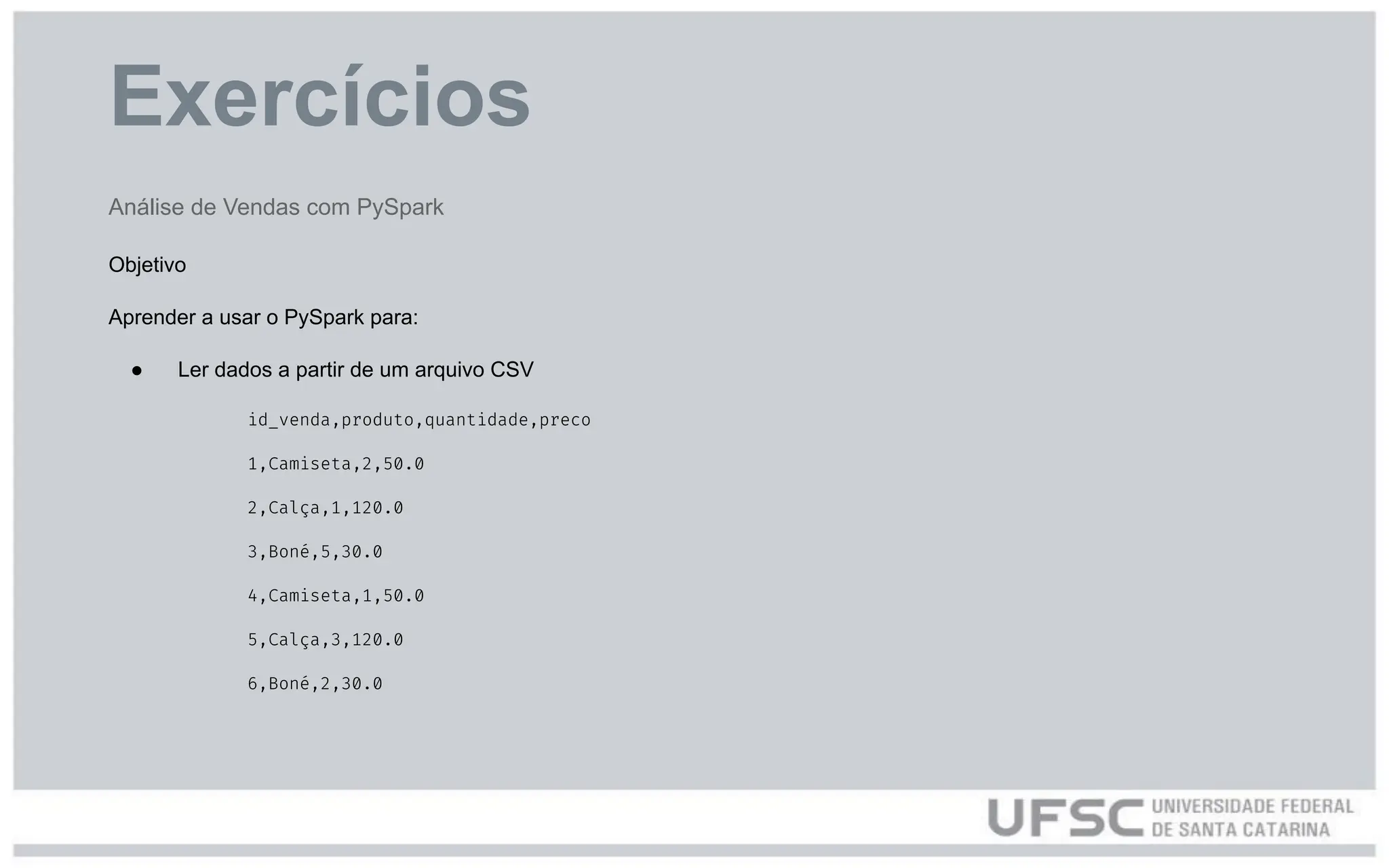
Exercícios
Análise de Vendascom PySpark
Objetivo
Aprender a usar o PySpark para:
● Ler dados a partir de um arquivo CSV
id_venda,produto,quantidade,preco
1,Camiseta,2,50.0
2,Calça,1,120.0
3,Boné,5,30.0
4,Camiseta,1,50.0
5,Calça,3,120.0
6,Boné,2,30.0
20.
Exercícios
● Explorar evisualizar os dados com .show() e .printSchema()
● Filtrar e selecionar colunas
● Realizar uma agregação simples com groupBy




![PySpark
● Localmente vamos usar:
○ spark = SparkSession.builder
○ .appName("ClimaAleatorio")
○ .master("local[*]")
○ .getOrCreate()
● Exemplo completo:
https://colab.research.google.com/drive/1lQOnm_wYH3kXmADx3fjgNt3Ws
1RcxclL?usp=sharing](https://image.slidesharecdn.com/ufsc-pyspark2-250527222129-3c97c8b8/75/Federal-University-of-Santa-Catarina-UFSC-PySpark-Tutorial-8-2048.jpg)
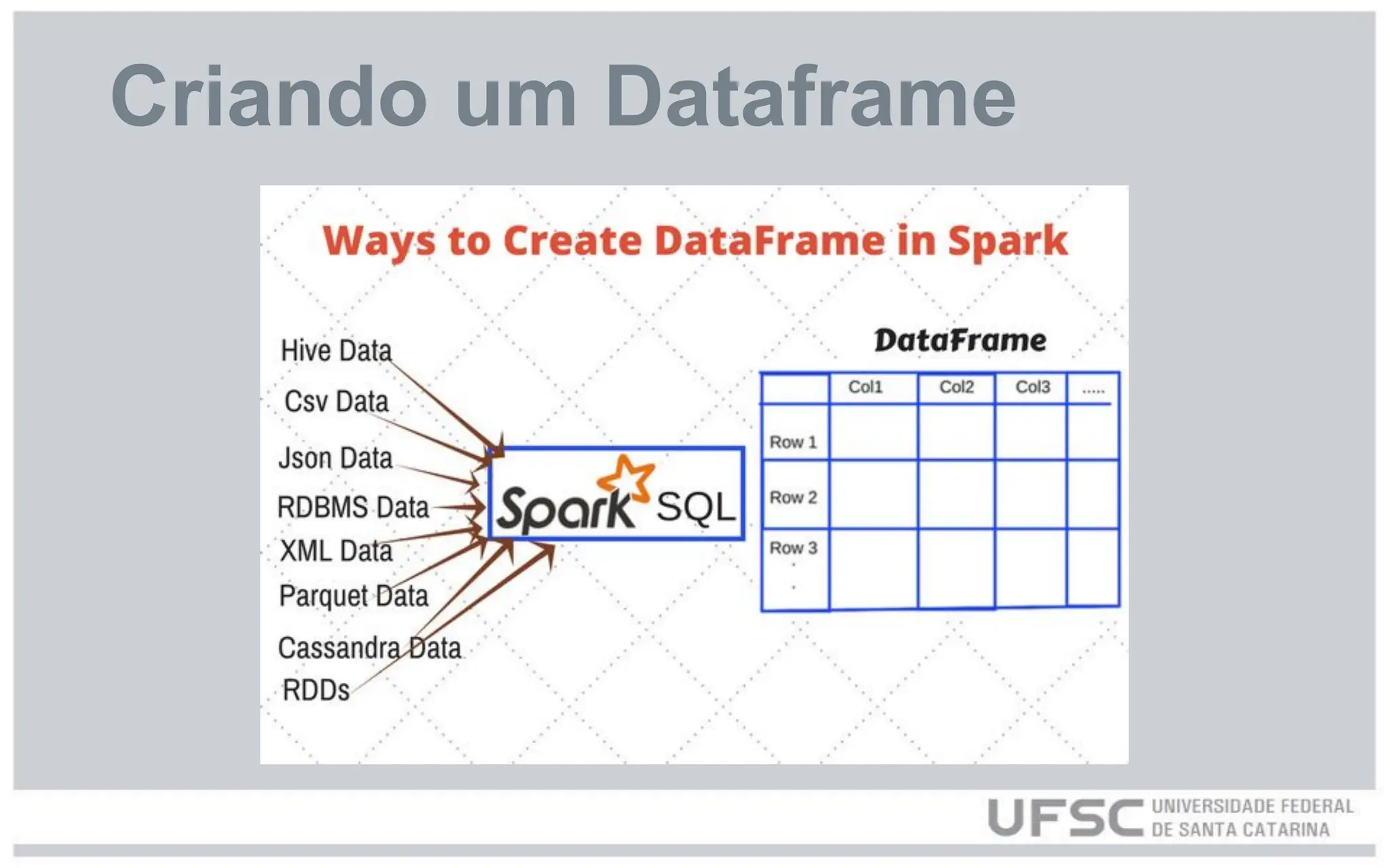
![Criando um Dataframe a partir de
dados da memória do Python
○ dados = []
○ schema = StructType([
○ StructField("cidade", StringType(), True),
StructField("temperatura_c", DoubleType(), True),
○ StructField("umidade_percent", IntegerType(), True),
○ StructField("condicao", StringType(), True) ])
○ df = spark.createDataFrame(dados, schema=schema)](https://image.slidesharecdn.com/ufsc-pyspark2-250527222129-3c97c8b8/75/Federal-University-of-Santa-Catarina-UFSC-PySpark-Tutorial-10-2048.jpg)




![Joins
● Os elementos de dataframes podem ser combinados usando joins:
clientes = spark.createDataFrame([
(1, "Alice"),
(2, "Bruno"),
(3, "Carlos")
], ["id", "nome"])
pedidos = spark.createDataFrame([
(1, "livro"),
(2, "caneta"),
(4, "mochila")
], ["cliente_id", "produto"])
clientes.join(pedid
os, clientes.id ==
pedidos.cliente_id,
"inner").show()](https://image.slidesharecdn.com/ufsc-pyspark2-250527222129-3c97c8b8/75/Federal-University-of-Santa-Catarina-UFSC-PySpark-Tutorial-16-2048.jpg)


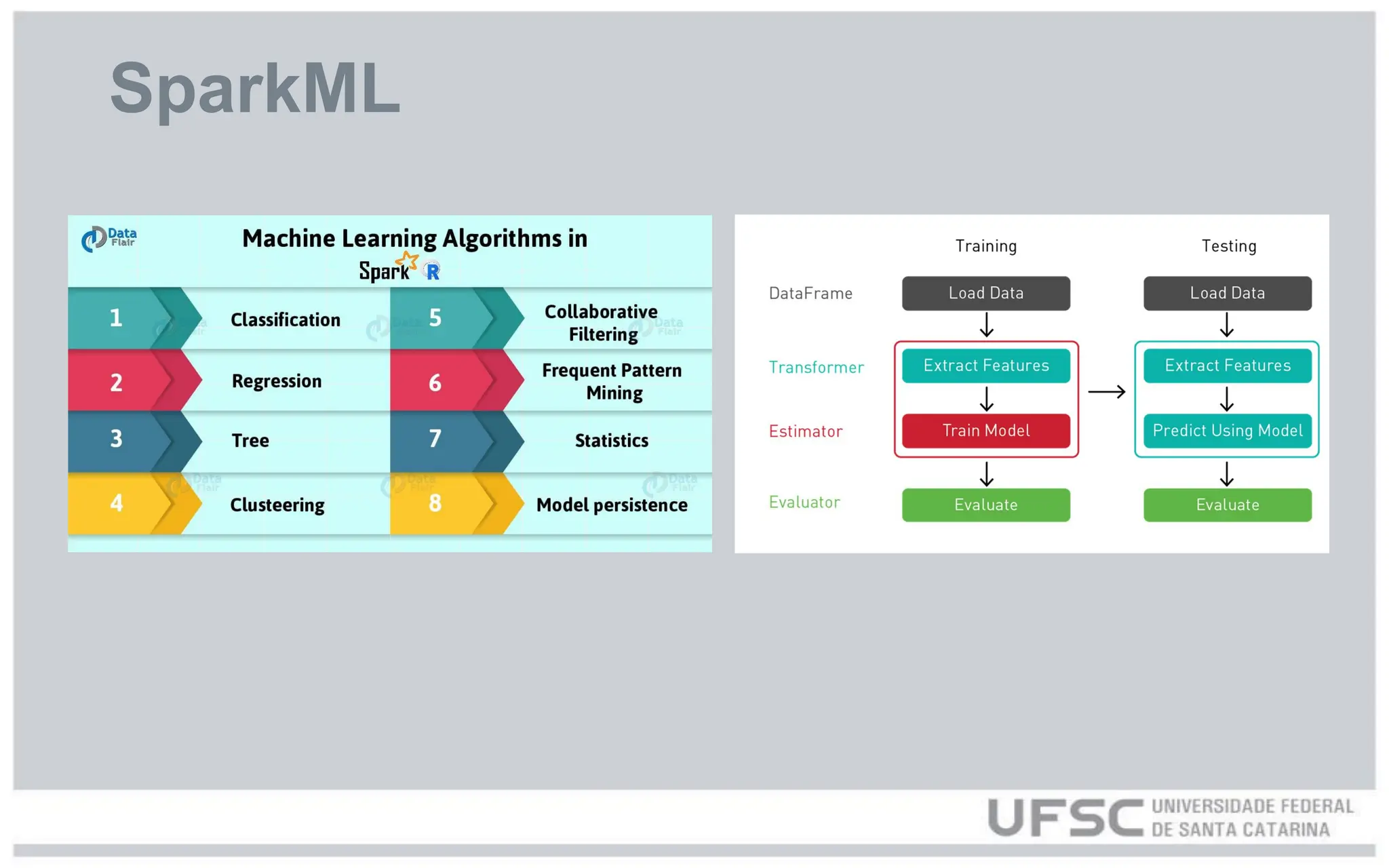
![SparkML
assembler = VectorAssembler(inputCols=["quantidade", "preco"], outputCol="features")
data = assembler.transform(data)
scaler = StandardScaler(inputCol="features", outputCol="scaled_features")
scaler_model = scaler.fit(data)
data = scaler_model.transform(data)
train_data, test_data = data.randomSplit([0.7, 0.3], seed=123)
svm = LinearSVC(featuresCol="scaled_features", labelCol="label")
svm_model = svm.fit(train_data)
predictions = svm_model.transform(test_data)
predictions.select("quantidade", "preco", "label", "prediction").show()
evaluator = BinaryClassificationEvaluator(labelCol="label", rawPredictionCol="prediction")
auc = evaluator.evaluate(predictions)
print(f"AUC (Área Sob a Curva): {auc}")
spark.stop()](https://image.slidesharecdn.com/ufsc-pyspark2-250527222129-3c97c8b8/75/Federal-University-of-Santa-Catarina-UFSC-PySpark-Tutorial-23-2048.jpg)








![[Datafest 2018] Apache Spark Structured Stream - Moedor de dados em tempo qua...](https://cdn.slidesharecdn.com/ss_thumbnails/datafest2018-apachesparkstructuredstreammoedordedadosemtempoquasereal-181101180406-thumbnail.jpg?width=640&height=640&fit=bounds)











































