Baixar para ler offline








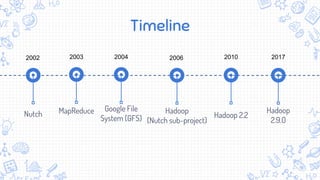




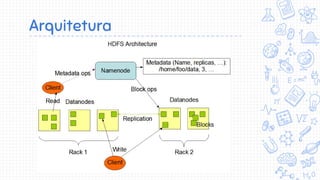
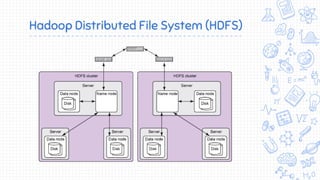
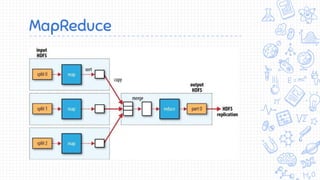
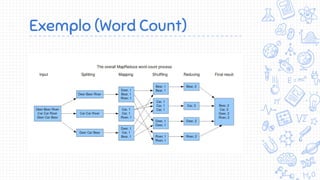





O documento apresenta uma introdução ao Apache Hadoop, um framework de código aberto para processamento e armazenamento distribuídos de grandes volumes de dados. Apresenta o contexto de big data, Internet das Coisas e MapReduce, e define Hadoop como uma implementação do modelo MapReduce que permite processamento escalável e tolerante a falhas em clusters distribuídos.










































