Baixado 62 vezes






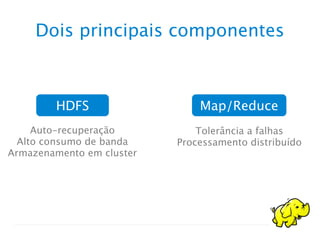






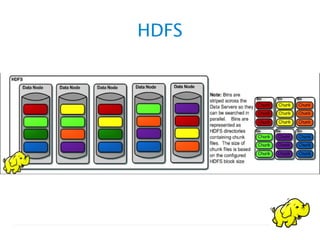







O documento discute vários tópicos relacionados a bancos de dados não-relacionais e Hadoop. Ele explica que Hadoop é uma plataforma de código aberto para processamento de grandes volumes de dados distribuídos em clusters, que usa HDFS para armazenamento e MapReduce para processamento paralelo tolerante a falhas. Também descreve o que é NoSQL, Hive e como o modelo MapReduce funciona no Hadoop.














































