Transferir como PDF, PPTX






















![Map
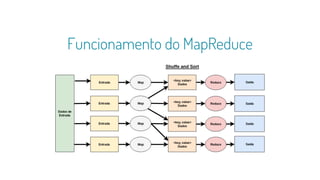
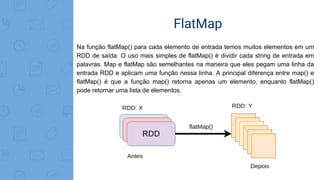
A função de map é repetida em todas as linhas do RDD e gera um novo RDD como
saída. Usando a transformação map(), utilizamos qualquer função, e essa função é
aplicada a todos os elementos do RDD. Por exemplo, temos um RDD [1, 2, 3, 4, 5]
se aplicarmos “rdd.map(x => x + 2)”, será obtido o resultado (3, 4, 5, 6, 7).](https://image.slidesharecdn.com/caipyra2018-180608211412/85/Desenvolvendo-Aplicacoes-baseadas-em-Big-Data-com-PySpark-29-320.jpg)
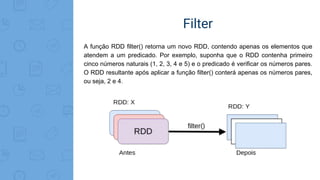
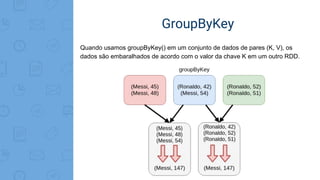
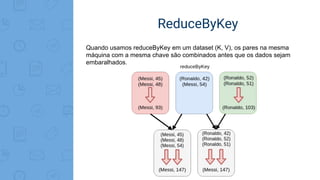
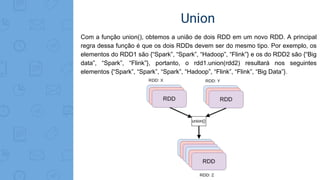
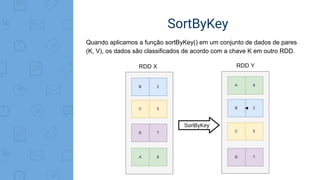

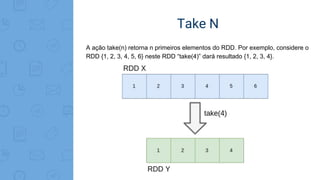
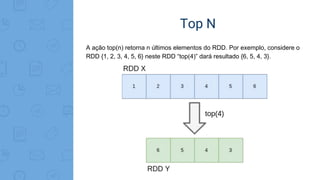
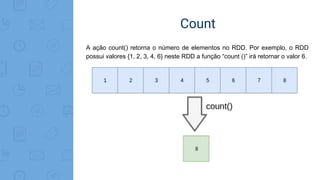
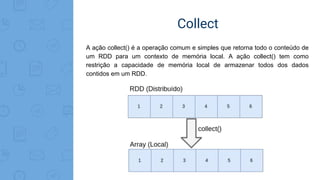
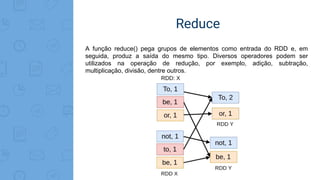


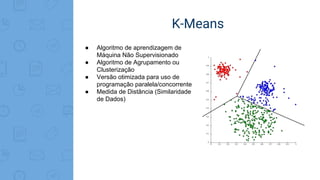



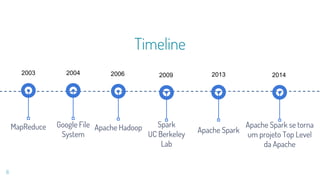
Este documento fornece uma introdução ao processamento de Big Data com PySpark. Resume os principais conceitos como MapReduce, Apache Spark, Resilient Distributed Dataset (RDD), e demonstra exemplos práticos de transformações e ações com RDD usando PySpark.
















![DeNAゲーム事業におけるデータエンジニアの貢献 [DeNA TechCon 2019]](https://cdn.slidesharecdn.com/ss_thumbnails/techcon2019dataengineer-190218065927-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)











