




![Internet of Things (IoT)
DEFINIÇÃO
A Internet das Coisas, refere-se à uma nova abordagem sobre a
interconexão de coisas, tecnologias e objetos, através da Internet. Essa
abordagem proporcionou ao longo do tempo a criação da rede global de
dispositivos [8].
Alguns exemplos de aplicações que
utilizam IoT:
Smart Farms: Agricultura de Precisão
e Controle Ambiental;
Smart Cities: Controle do Trânsito e
Monitoramento do Clima; e
Smart Homes: Agilidade nas
atividades do dia a dia das pessoas.
SSC5795 Vinícius Aires Barros Novembro 2016 8 / 48](https://image.slidesharecdn.com/apresentacaops-170225023730/85/Apresentacao-Programacao-Concorrente-USP-8-320.jpg)
![Big Data
DEFINIÇÃO
Big Data é definido como um conjunto de dados estruturados ou não estruturados que
não puderam ser percebidos, adquiridos, gerenciados e processados pelos modelos
tradicionais de hardware e software [3].
Alguns exemplos de aplicações de Big
Data:
Processamento e análise das
preferências dos usuário de um
sistema;
Detecção de fraudes em licitações; e
Auxiliar na tomada de decisão de
diferentes cenários.
SSC5795 Vinícius Aires Barros Novembro 2016 9 / 48](https://image.slidesharecdn.com/apresentacaops-170225023730/85/Apresentacao-Programacao-Concorrente-USP-9-320.jpg)
![Otimização Multiobjetivo
DEFINIÇÃO
A otimização multiobjetivo é uma parte integrante das atividades de
otimização que apresenta uma enorme importância prática, uma vez que
quase todos os problemas de otimização do mundo real são ideais que
sejam modelados utilizando múltiplos objetivos conflitantes [4].
Alguns exemplos práticos da aplicação de
modelos de otimização multiobjetivo:
Problemas de engenharia;
Indústria; e
Ciência da Computação.
SSC5795 Vinícius Aires Barros Novembro 2016 10 / 48](https://image.slidesharecdn.com/apresentacaops-170225023730/85/Apresentacao-Programacao-Concorrente-USP-10-320.jpg)
![Fronteira de Pareto
DEFINIÇÃO
Relações denominadas fronteira de pareto são utilizadas para comparar
soluções, onde o conjunto de soluções ótimas de um problema é dado o
nome de soluções de pareto ótimas ou soluções não dominadas [7].
C
Pareto
A
B
f2(A) < f2(B)
f1
f2
f1(A) > f1(B)
Conjunto das melhores soluções dado
um conjunto de critérios;
Soluções dominadas e não
dominadas; e
Níveis de soluções separadas em
camadas.
SSC5795 Vinícius Aires Barros Novembro 2016 11 / 48](https://image.slidesharecdn.com/apresentacaops-170225023730/85/Apresentacao-Programacao-Concorrente-USP-11-320.jpg)
![Relação de Dominância
DEFINIÇÃO
Uma solução xT é dita não dominada quando não existe nenhum x ∈ S tal
que fi (x) ≤ fi (xT ) para pelo menos um dos objetivos analisados [1]. A
imagem do conjunto de soluções ótimas é chamada de fronteira de pareto ou
curva de pareto. O formato da fronteira de pareto indica a natureza do
trade-off entre diferentes funções objetivo [2].
Não é Reflexiva
A relação de dominância não é reflexiva uma vez que qualquer solução x não se auto
domina (por definição de dominância).
Não é Simétrica
A relação de dominância não é simétrica, por exemplo x y não implica que y x.
Mas o contrário y x é verdade.
Não é Anti Simétrica
Como a relação de dominância não é simétrica, ela também não pode ser Anti
simétrica.
É Transitiva
A relação de dominância é transitiva. Se x y e y z, logo x z.
SSC5795 Vinícius Aires Barros Novembro 2016 12 / 48](https://image.slidesharecdn.com/apresentacaops-170225023730/85/Apresentacao-Programacao-Concorrente-USP-12-320.jpg)
![Relação de Não Dominância
DEFINIÇÃO
Entre um conjunto de soluções P, o conjunto não dominado de soluções P
são aqueles que não são dominados por qualquer membro do conjunto P [7].
Para um determinado conjunto de solução, podemos realizar todas as
comparações possíveis par a par e encontrar qual solução domina quais e quais
soluções não são dominadas umas em relação às outras; e
Este conjunto tem a propriedade de dominar todas as soluções que pertencem ao
conjunto.
SSC5795 Vinícius Aires Barros Novembro 2016 13 / 48](https://image.slidesharecdn.com/apresentacaops-170225023730/85/Apresentacao-Programacao-Concorrente-USP-13-320.jpg)


![Speedup
Speedup
O speedup diz respeito ao ganho de desempenho obtido em comparação
com a versão sequencial do algoritmo [9].
Sp =
Ts
Tp
(1)
SSC5795 Vinícius Aires Barros Novembro 2016 16 / 48](https://image.slidesharecdn.com/apresentacaops-170225023730/85/Apresentacao-Programacao-Concorrente-USP-16-320.jpg)
![Eficiência
Eficiência
A eficiência de um algoritmo paralelo está relacionada ao tempo em que os
processos de fato estão executando o problema. Esta métrica tem como
objetivo indicar os possíveis tempos de ociosidades ou alto custo de
comunicação de sistemas concorrentes [9].
E =
Sp
p
(2)
SSC5795 Vinícius Aires Barros Novembro 2016 17 / 48](https://image.slidesharecdn.com/apresentacaops-170225023730/85/Apresentacao-Programacao-Concorrente-USP-17-320.jpg)
![Trabalhos Relacionados
A fast and elitist multiobjective genetic algorithm: NSGA-II [5];
An efficient approach to nondominated sorting for evolutionary multiobjective
optimization [12];
Very Fast Non-Dominated Sorting [11]; e
GPU based Non-dominated Sorting Genetic Algorithm-II for multi-objective traffic
light signaling optimization with agent based modeling [10].
SSC5795 Vinícius Aires Barros Novembro 2016 18 / 48](https://image.slidesharecdn.com/apresentacaops-170225023730/85/Apresentacao-Programacao-Concorrente-USP-18-320.jpg)
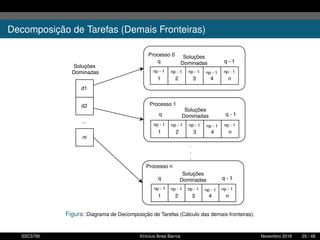
![Mapeamento e decomposição de tarefas
Metodologia PCAM de Ian Foster [6]:
1 Particionamento
Divisão do espaço busca e
combinações;
2 Comunicação
Passagem de mensagem (send e
receive);
3 Aglomeração
Junção de operações;
4 Mapeamento
Divisão de tarefas em processos;
5 Decomposição do problema
SSC5795 Vinícius Aires Barros Novembro 2016 20 / 48](https://image.slidesharecdn.com/apresentacaops-170225023730/85/Apresentacao-Programacao-Concorrente-USP-20-320.jpg)
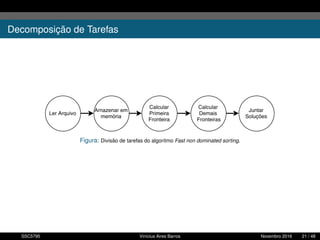
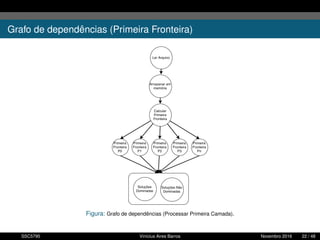
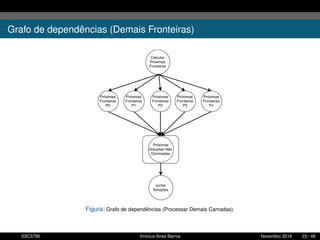
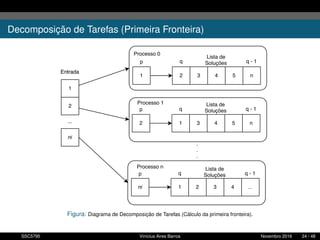


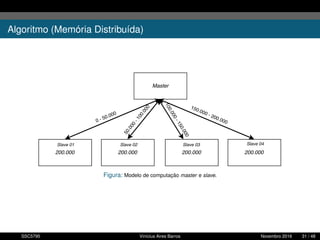
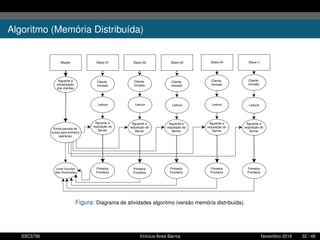
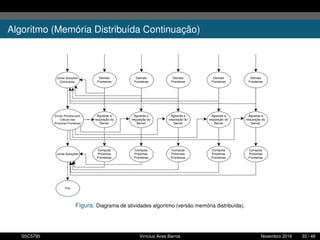


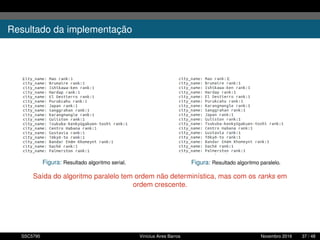
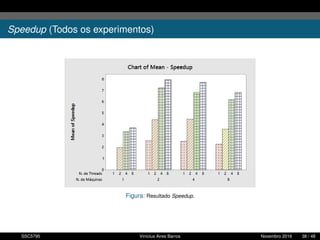
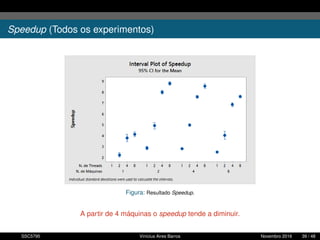
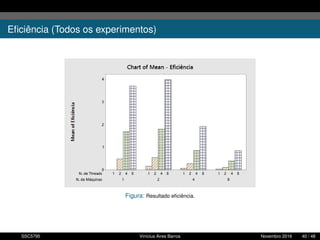
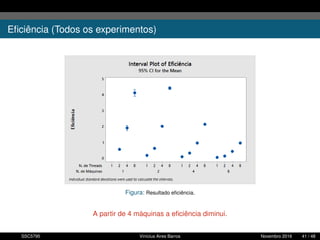
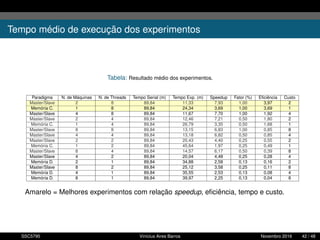






1. O documento descreve uma proposta para paralelizar o algoritmo Fast non Dominated Sorting para classificar cidades de acordo com informações climáticas. 2. O objetivo é aplicar o algoritmo para selecionar cidades considerando múltiplos critérios climáticos e paralelizar o algoritmo para reduzir o tempo de execução. 3. A metodologia inclui desenvolver versões sequencial e paralela do algoritmo, testar em diferentes configurações e ambientes de computação distribuída, e avaliar o ganho de desempenho.



























