Baixar para ler offline












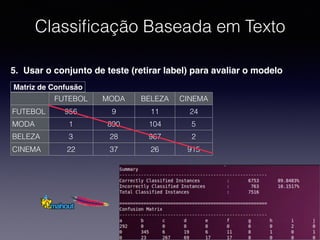


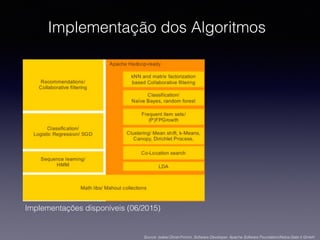


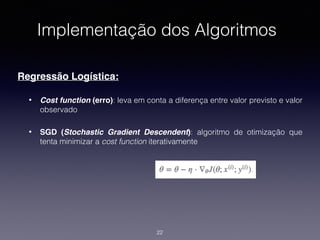

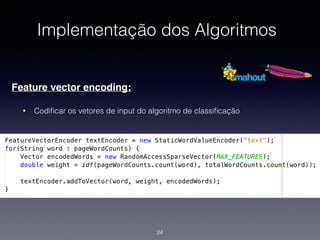
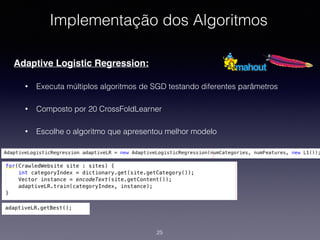


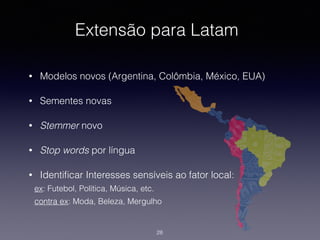
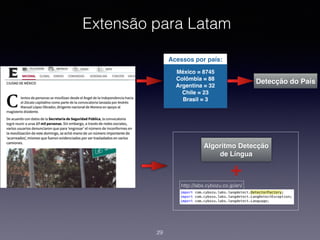
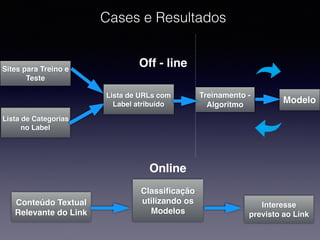





1) O documento discute a classificação de conteúdo de páginas web usando machine learning e Java. 2) Inclui detalhes sobre como preparar os dados, treinar modelos de classificação e avaliar os resultados. 3) Também aborda implementações práticas usando a biblioteca Apache Mahout e casos reais de classificação de conteúdo web.





![[DTC21] Raphael Castilho - Começando com Inteligência Artificial e Machine Le...](https://cdn.slidesharecdn.com/ss_thumbnails/iaemachine-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)



























