Transferir como PDF, PPTX







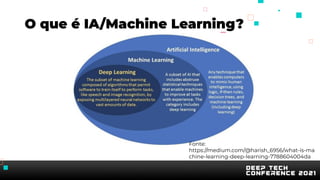


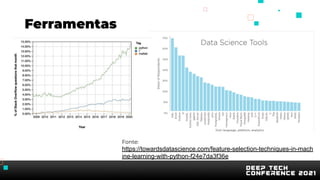


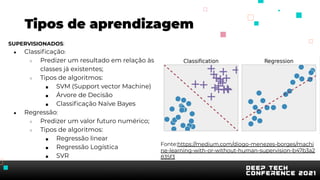



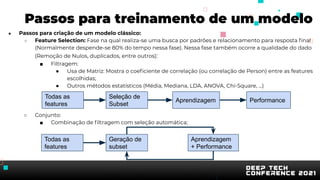

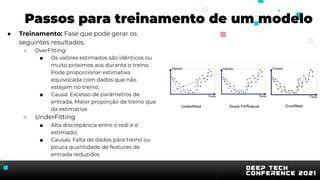

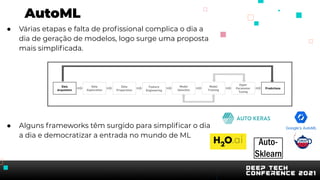






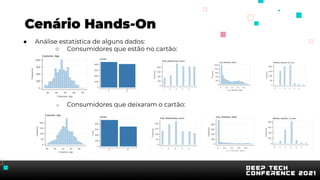
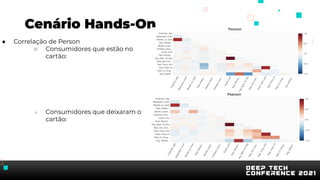

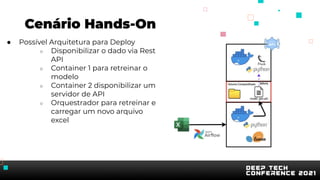



O documento apresenta uma introdução sobre inteligência artificial e machine learning. A agenda inclui tópicos como o mercado atual, definição de IA/ML, conhecimentos recomendados, tipos de aprendizagem, passos para treinamento de modelos, AutoML, problemas comuns e implementação de modelos. O palestrante também apresenta uma demonstração prática usando um conjunto de dados sobre clientes de cartão de crédito.
![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DTC21] André Marques - Jornada do Engenheiro de Dados](https://cdn.slidesharecdn.com/ss_thumbnails/jornadadoengenheirodedados-210317153718-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DTC21] Thiago Lima - Do Zero ao 100 no Mundo de Microservices](https://cdn.slidesharecdn.com/ss_thumbnails/0a100microservies-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)












































