Baixado 28 vezes























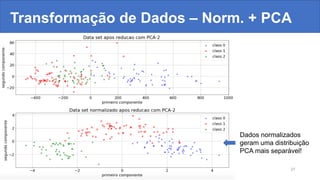


![Glucose ≤ 127.5
gini = 0.454
samples = 768
value = [500, 268]
class = ~diabetes
Age ≤ 28.5
gini = 0.313
samples = 485
value = [391, 94]
class = ~diabetes
True
BMI ≤ 30.2
gini = 0.474
samples = 283
value = [109, 174]
class = diabetes
False
BMI ≤ 30.95
gini = 0.155
samples = 271
value = [248, 23]
class = ~diabetes
Glucose ≤ 103.5
gini = 0.443
samples = 214
value = [143, 71]
class = ~diabetes
gini = 0.026
samples = 151
value = [149, 2]
class = ~diabetes
gini = 0.289
samples = 120
value = [99, 21]
class = ~diabetes
gini = 0.32
samples = 90
value = [72, 18]
class = ~diabetes
gini = 0.489
samples = 124
value = [71, 53]
class = ~diabetes
gini = 0.452
samples = 81
value = [53, 28]
class = ~diabetes
Glucose ≤ 157.5
gini = 0.401
samples = 202
value = [56, 146]
class = diabetes
gini = 0.476
samples = 113
value = [44, 69]
class = diabetes
gini = 0.233
samples = 89
value = [12, 77]
class = diabetes
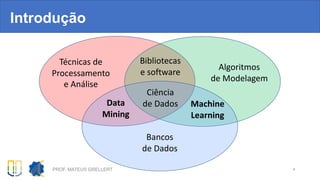
4 – Treinamento – Árvores de Decisão
Árvore obtida com o data set “Pima Indians Diabetes”
PROF. MATEUS GRELLERT 32
Atributo mais importante fica na raiz
da árvore
As decisões ficam sempre nas folhas.
A árvore é percorrida de acordo com
os testes lógicos feitos em cada nó.](https://image.slidesharecdn.com/palestradataminingmachinelearninggrellert-180922013722/85/Data-Mining-e-Machine-Learning-com-Python-Mateus-Grellert-Tchelinux-Pelotas-2018-32-320.jpg)




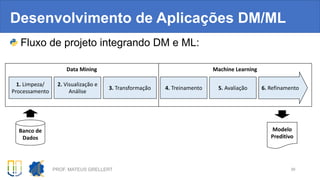


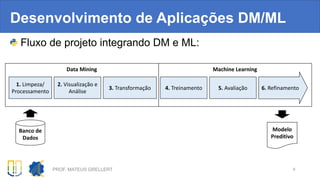
![Sumarizando
Tarefa Método Lib
Abrir banco em CSV dataset = read_csv( path, sep = “t” ) Pandas
Detectar dados inválidos dataset.isnull( ).any( ) Pandas
Imputar dados inválidos dataset.fillna( valor ) Pandas
Computar correlação entre
colunas
df_correlacao = dataset.corr() Pandas
Plotar correlação heatmap(df_correlacao) Seaborn
Plotar histograma da coluna
atributo
dataset[atributo].plot.hist( ) Pandas
Agrupado por desfecho dataset.groupby("Outcome")[atributo].plot.hist( ) Pandas
Normalizar dados de X StandardScaler().fit_transform(X) Scikit-learn
PROF. MATEUS GRELLERT 43](https://image.slidesharecdn.com/palestradataminingmachinelearninggrellert-180922013722/85/Data-Mining-e-Machine-Learning-com-Python-Mateus-Grellert-Tchelinux-Pelotas-2018-43-320.jpg)
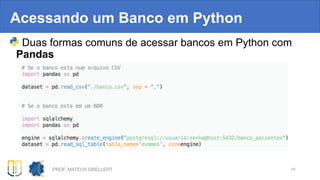
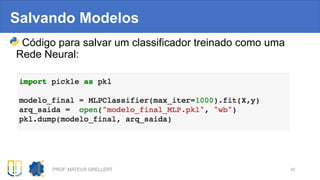
![Sumarizando
Tarefa Método Lib
PCA de 3 componentes Xt = PCA(n_components=3).fit_transform(X) Scikit-learn
Selecionar K melhores
atributos
best = SelectKBest( k = K ).fit( X, y ) Scikit-learn
Treinar Dec. Tree clf = DecisionTreeClassifier().fit( X, y ) Scikit-learn
Obter resultado de CV com
5 subpartições
scores = cross_val_score(clf, X, y, cv=5) Scikit-learn
Concatenar objetos scikit-
learn
pipe = Pipeline( [ ( 'scaling', StandardScaler() ),
('clf', DecisionTreeClassifier()) ] )
Scikit-learn
Testar combinações de
parâmetros com CV-5
gs_clf = GridSearchCV(pipe, params, cv = 5) Scikit-learn
Salvar modelo final dump(objeto, arquivo_binario) Pandas
Ler o modelo modelo = load(arquivo_binario) Pandas
PROF. MATEUS GRELLERT 44](https://image.slidesharecdn.com/palestradataminingmachinelearninggrellert-180922013722/85/Data-Mining-e-Machine-Learning-com-Python-Mateus-Grellert-Tchelinux-Pelotas-2018-44-320.jpg)


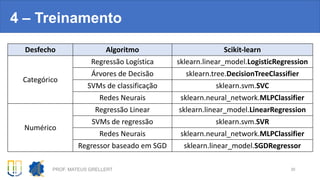
Este documento apresenta um resumo sobre data mining e machine learning com Python. Ele introduz os conceitos de ciência de dados, data mining e machine learning, discute exemplos de aplicações e fontes de dados. Também aborda ferramentas em Python como pandas e scikit-learn, e o fluxo de projeto que inclui limpeza, visualização, transformação, treinamento e avaliação de modelos preditivos.




![[José Ahirton Lopes] Support Vector Machines](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopes-apresentacaosupportvectormachines-180326014519-thumbnail.jpg?width=640&height=640&fit=bounds)

![[José Ahirton Lopes] Treinamento - Árvores de Decisão, SVM e Naive Bayes](https://cdn.slidesharecdn.com/ss_thumbnails/treinamentodeveloperssp-180611021639-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[DTC21] Raphael Castilho - Começando com Inteligência Artificial e Machine Le...](https://cdn.slidesharecdn.com/ss_thumbnails/iaemachine-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)























