Baixado 95 vezes





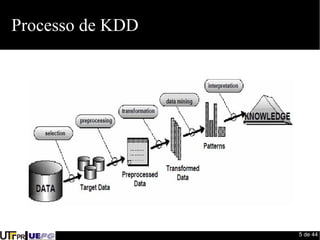





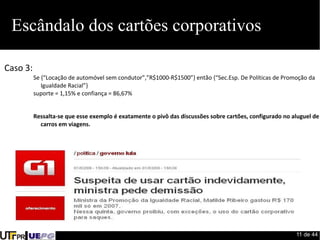

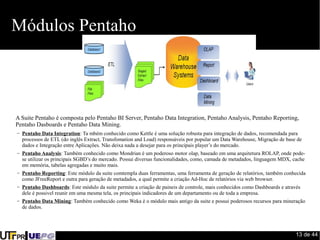







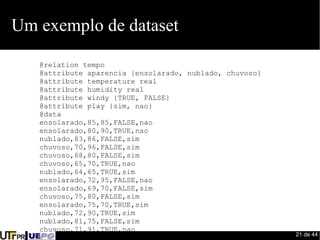


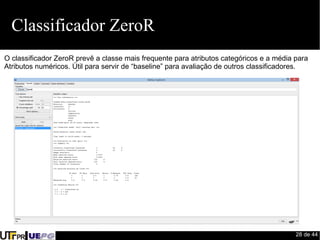
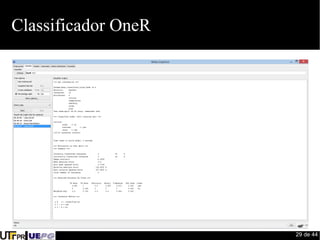

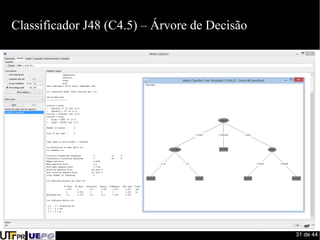
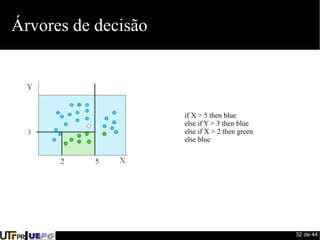












Este documento fornece uma introdução ao processo de construção de classificadores para mineração de dados. Discute conceitos como classificação, regressão, agrupamento e detecção de desvios. Apresenta ferramentas como Weka e Pentaho para desenvolvimento de modelos preditivos e avaliação de algoritmos de aprendizado de máquina.






























































