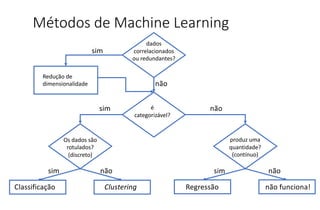
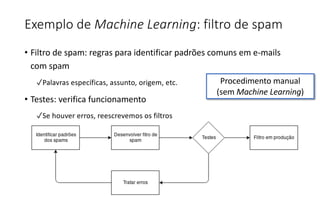
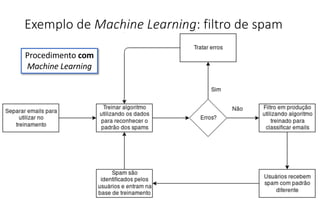
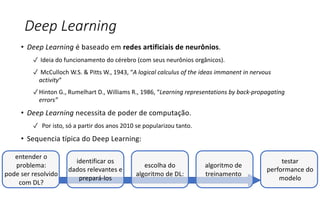
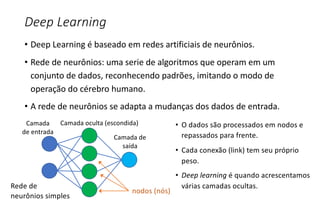
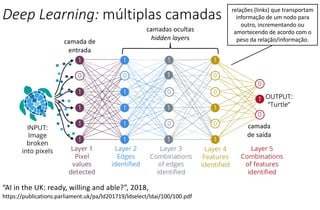
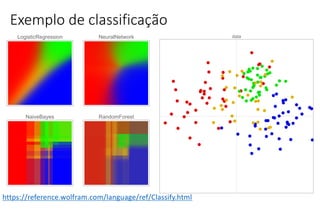
O documento apresenta uma introdução ao machine learning, destacando que se trata de um campo da ciência da computação onde sistemas aprendem a interpretar dados sem programação explícita. Explica os principais métodos, como aprendizado supervisionado e não supervisionado, e oferece exemplos aplicáveis, como filtros de spam e deep learning. A profundidade do aprendizado é associada a redes de neurônios artificiais, refletindo o funcionamento do cérebro humano.















![[DTC21] Raphael Castilho - Começando com Inteligência Artificial e Machine Le...](https://cdn.slidesharecdn.com/ss_thumbnails/iaemachine-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)






















