Baixado 21 vezes









![Algo como:Mas a derivada é sempre zero ou infinita (?)ClassificaçãoPerceptrão [McCullogh & Pitts 43]Regra Delta (delta-rule)](https://image.slidesharecdn.com/aamdulo6-aprendizagemsupervisionadaii20102011verso2-101018095752-phpapp01/85/Aprendizagem-Supervisionada-II-9-320.jpg)

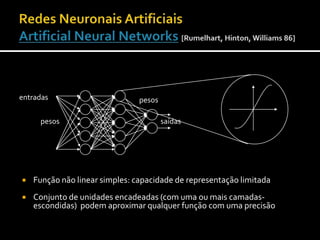
![Função não linear simples: capacidade de representação limitadaConjunto de unidades encadeadas (com uma ou mais camadas-escondidas) podem aproximar qualquer função com uma precisão arbitrária (desde que … )Redes Neuronais ArtificiaisArtificial Neural Networks[Rumelhart, Hinton, Williams 86] entradaspesospesossaídas](https://image.slidesharecdn.com/aamdulo6-aprendizagemsupervisionadaii20102011verso2-101018095752-phpapp01/85/Aprendizagem-Supervisionada-II-11-320.jpg)













![[Rumelhart, Hinton, Williams 86] D.E.Rumelhart, G.E.Hinton and R.J.Williams, "Learning internal representa-tions by error propagation", In David E. Rumelhart and James A. McClelland, volume 1. The MIT Press, 1986.[Rumelhart, Widrow, Lehr] David E. Rumelhart, Bernard Widrow, Michael A. Lehr, The basic ideas in neural networks, Communications of the ACM archive, Volume 37 , Issue 3 (March 1994) table of contents, pp 87 – 92, 1994, ISSN:0001-0782 , Publisher ACM Press New York, NY, USA F. M. Silva and L. B. Almeida, "Acceleration Techniques for the Backpropagation Algorithm", in L. B. Almeida and C. J. Wellekens (eds.), Neural Networks, Springer-Verlag, 1990.OutrasReferências:[McCullough & Pitts 43] W. S. McCullough, W. Pitts, LogicalCalculusoftheideasimmanentinnervousactivity, Contemp. Math, 113, pp. 189-219[Minsky & Papert 69] Minsky M L and Papert S A 1969 Perceptrons (Cambridge, MA: MIT Press) Referências-base28AA/ML, Luís Nunes, DCTI/ISCTE](https://image.slidesharecdn.com/aamdulo6-aprendizagemsupervisionadaii20102011verso2-101018095752-phpapp01/85/Aprendizagem-Supervisionada-II-29-320.jpg)

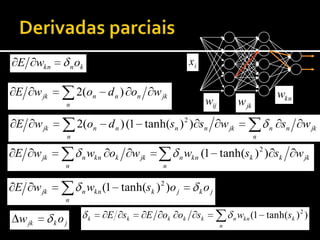
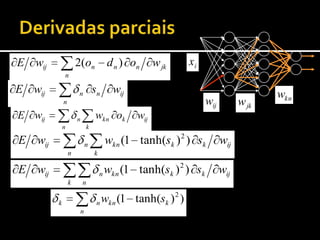




1) O documento discute técnicas de aprendizagem automática supervisionada como regressão, classificação e redes neurais artificiais. 2) A retropropagação é descrita como um método para treinar redes neurais através da propagação de erros e atualização dos pesos para minimizar o erro. 3) Várias técnicas são discutidas para acelerar a convergência da retropropagação incluindo taxas de aprendizagem adaptativas e momento.







![[José Ahirton Lopes] Support Vector Machines](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopes-apresentacaosupportvectormachines-180326014519-thumbnail.jpg?width=640&height=640&fit=bounds)





![[José Ahirton Lopes] Treinamento - Árvores de Decisão, SVM e Naive Bayes](https://cdn.slidesharecdn.com/ss_thumbnails/treinamentodeveloperssp-180611021639-thumbnail.jpg?width=640&height=640&fit=bounds)

































