Transferir como PDF, PPTX




















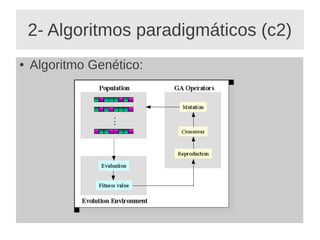







O documento apresenta um minicurso sobre mineração de dados, abordando sua definição, utilidade, histórico, tipos de aprendizado de máquina e algoritmos relevantes. Discute também as etapas fundamentais do processo de mineração de dados e as aplicações práticas em várias áreas. Conclui com uma reflexão sobre a recente popularidade da mineração de dados e sua interrelação com aprendizado de máquina e inteligência artificial.



























