Baixado 14 vezes









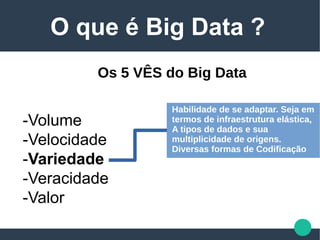















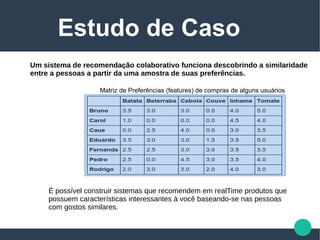

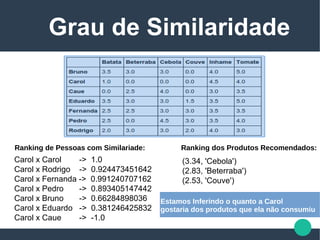





A palestra apresenta uma visão geral sobre big data, destacando suas características principais, que incluem volume, velocidade, variedade, veracidade e valor. Enfatiza a importância da cultura organizacional na extração de informações e na criação de projetos valiosos, além de discutir o perfil do profissional de big data e suas habilidades necessárias. O documento também menciona o uso de métodos científicos para lidar com dados em diversas formas e origens, propondo uma análise que vai além do mero armazenamento e processamento.
























































