Baixado 84 vezes









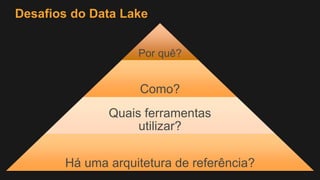
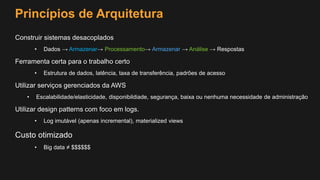
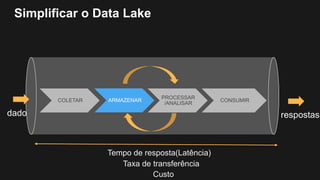
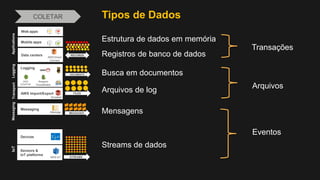

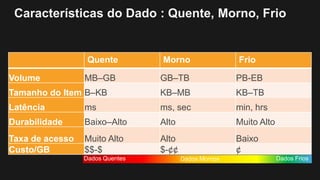
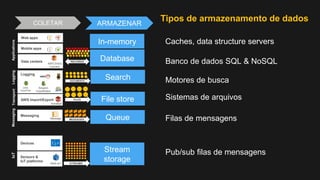
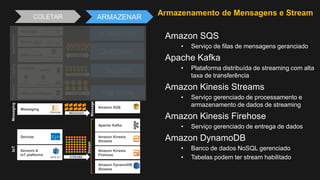
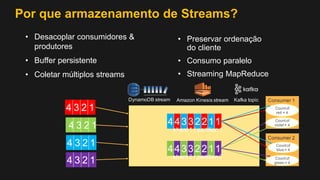
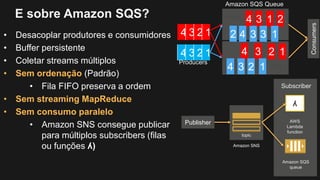
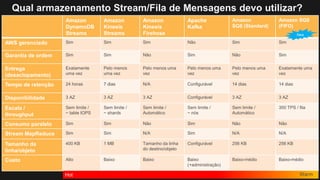
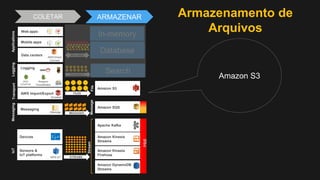


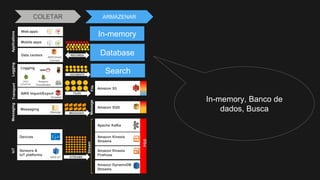
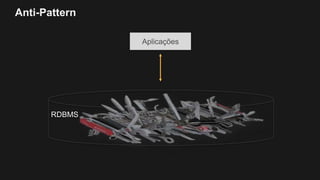
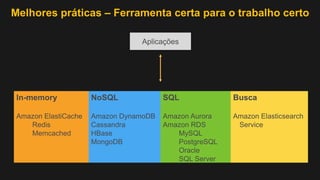
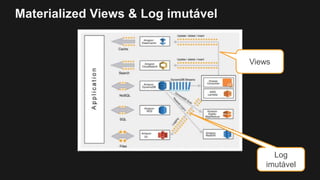
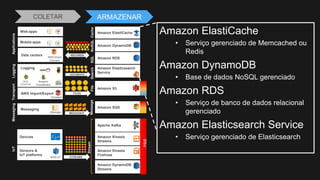
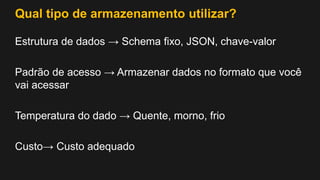

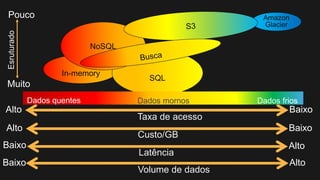



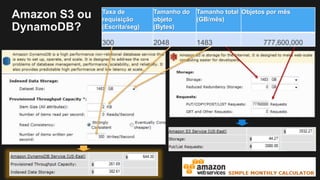
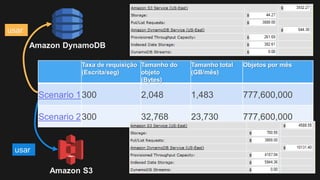




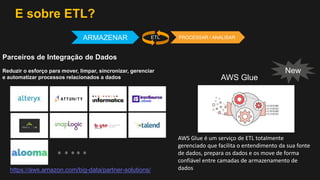

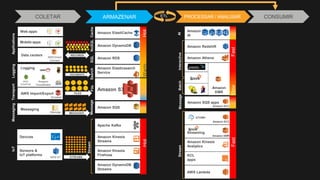
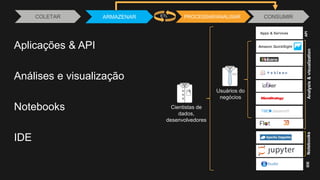

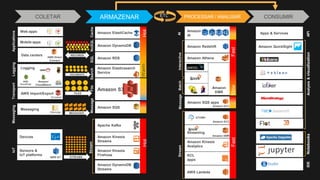


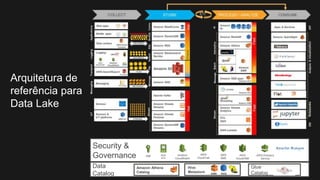
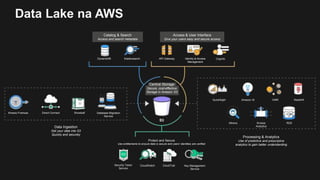

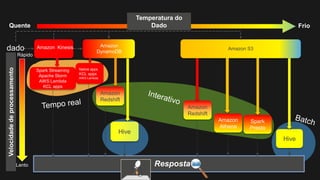
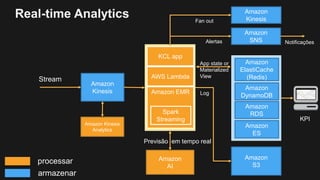
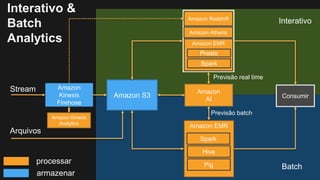
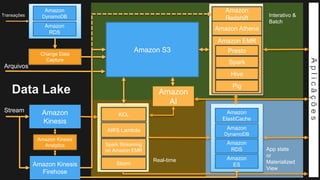




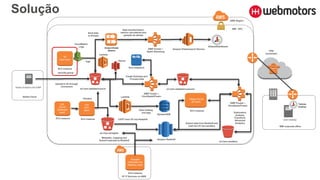


1) O documento discute como construir um Data Lake na AWS utilizando várias tecnologias da AWS. 2) É apresentada uma agenda com conceitos de Data Lake, simplificando o Data Lake e quais tecnologias utilizar. 3) Uma arquitetura de referência e design patterns são discutidos.













































![[Webinar] AWS Storage Day - Português](https://cdn.slidesharecdn.com/ss_thumbnails/storageday-15052018pt-180518151634-thumbnail.jpg?width=640&height=640&fit=bounds)





















