O documento apresenta o serviço Amazon Redshift da AWS, descrevendo suas principais características como armazenamento de dados colunar, compressão, zone maps, desempenho de consultas paralelas e elasticidade.
Eric Ferreira |ericfe@amazon.com | @ericnf
Senior Database Engineer
Amazon Redshift
2.
Vários Tutoriais ,treinamentos e mentoria em
português
Inscreva-se agora !!
http://awshub.com.br
3.
Data Warehousing dojeito AWS
Pague pelo uso
Alta performance a um preço baixo
Suporte a ferramentas padrão (SQL)
Fácil de provisionar
4.
Nosso objetivo foicriar…
Um serviço de DW simples, rápido e escalável. O resultado foi
~ 10x mais rápido
~ 10x menos custo
fácil de usar
Amazon Redshift
5.
Alguns resultados dosClientes Redshift
Consultas 5x – 20x mais rápidas;
Redução de 4x no custo comparado a HIVE
Redução de 20x – 40x tempo de consulta
Redução de 50% em custo,
Consultas 2x mais rápidas
6.
Amazon Redshift reduzI/O
• Compressão de dados
• “Zone maps”
• Disco local
• Blocos de dados grande
ID Age State Amount
123 20 CA 500
345 25 WA 250
678 40 FL 125
957 37 WA 375
• Não precisa acessar ou retornar
todas as colunas para calcular a
soma de “Amount”
7.
Amazon Redshift reduzI/O
• Banco de dados colunar
• Compressão de dados
• “Zone maps”
• Disco local
• Blocos de dados grande
• Compressão por coluna reduz o uso
de espaço e acelera leitura
• Amazon Redshift pode fazer a
escolha para você,
automaticamente
analyze compression listing;
Table | Column | Encoding
---------+----------------+----------
listing | listid | delta
listing | sellerid | delta32k
listing | eventid | delta32k
listing | dateid | bytedict
listing | numtickets | bytedict
listing | priceperticket | delta32k
listing | totalprice | mostly32
listing | listtime | raw
8.
Amazon Redshift reduzI/O
• Banco de dados colunar
• Compressão de dados
• “Zone maps”
• Disco local
• Blocos de dados grande
• Cada bloco registra o valor
mínimo/máximo, em memória.
• Blocos que não vão satisfazer o
filtro, não são lidos.
• O I/O mais rápido é aquele que
não precisa ser feito.
9.
Amazon Redshift reduzI/O
• Banco de dados colunar
• Compressão de dados
• “Zone maps”
• Disco local
• Blocos de dados grande
• Disco local maximiza a taxa de
transferência
• Hardware otimizado para
processamento de informação
• Bloco grande aproveita cada
acesso
• Amazon Redshift garante a
durabilidade dos dados
10.
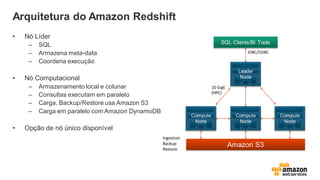
Arquitetura do AmazonRedshift
• Nó Líder
– SQL
– Armazena meta-data
– Coordena execução
• Nó Computacional
– Armazenamento local e colunar
– Consultas executam em paralelo
– Carga, Backup/Restore usa Amazon S3
– Carga em paralelo com Amazon DynamoDB
• Opção de nó único disponível
10 GigE
(HPC)
Ingestion
Backup
Restore
JDBC/ODBC
11.
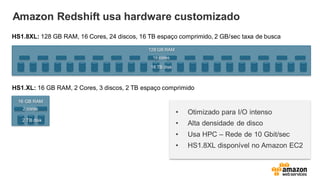
Amazon Redshift usahardware customizado
HS1.8XL: 128 GB RAM, 16 Cores, 24 discos, 16 TB espaço comprimido, 2 GB/sec taxa de busca
HS1.XL: 16 GB RAM, 2 Cores, 3 discos, 2 TB espaço comprimido
• Otimizado para I/O intenso
• Alta densidade de disco
• Usa HPC – Rede de 10 Gbit/sec
• HS1.8XL disponível no Amazon EC2
12.
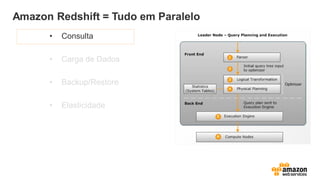
Amazon Redshift =Tudo em Paralelo
• Consulta
• Carga de Dados
• Backup/Restore
• Elasticidade
13.
Amazon Redshift =Tudo em Paralelo
• Consulta
• Carga de Dados
• Backup/Restore
• Elasticidade • Carga em paralelo do S3 ou
DynamoDB
• Dados automaticamente distribuídos
e ordenados de acordo com o DDL
• Escala linearmente com o número de
nós.
14.
Amazon Redshift =Tudo em Paralelo
• Consulta
• Carga de Dados
• Backup/Restore
• Elasticidade
• Backups para S3 é automático,
continuo e incremental
• Período de retenção configurável
• Copias manuais usando API e
console web
• “Streaming restores” possibilitam
estar on-line mais rápido.
15.
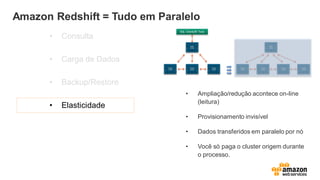
Amazon Redshift =Tudo em Paralelo
• Consulta
• Carga de Dados
• Backup/Restore
• Elasticidade
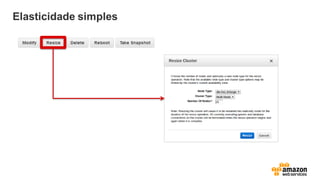
• Ampliação/redução acontece on-line
(leitura)
• Provisionamento invisível
• Dados transferidos em paralelo por nó
• Você só paga o cluster origem durante
o processo.
16.
Amazon Redshift =Tudo em Paralelo
• Consulta
• Carga de Dados
• Backup/Restore
• Elasticidade
• DNS é atualizado automaticamente
• Cluster original é descartado
• Operação simples usando AWS
Console ou API
17.
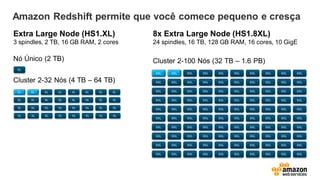
Amazon Redshift permiteque você comece pequeno e cresça
Extra Large Node (HS1.XL)
3 spindles, 2 TB, 16 GB RAM, 2 cores
Nó Único (2 TB)
Cluster 2-32 Nós (4 TB – 64 TB)
8x Extra Large Node (HS1.8XL)
24 spindles, 16 TB, 128 GB RAM, 16 cores, 10 GigE
Cluster 2-100 Nós (32 TB – 1.6 PB)
18.
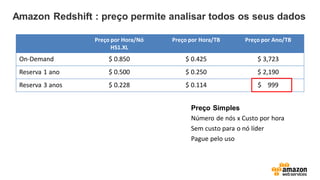
Amazon Redshift :preço permite analisar todos os seus dados
Preço por Hora/Nó
HS1.XL
Preço por Hora/TB Preço por Ano/TB
On-Demand $ 0.850 $ 0.425 $ 3,723
Reserva 1 ano $ 0.500 $ 0.250 $ 2,190
Reserva 3 anos $ 0.228 $ 0.114 $ 999
Preço Simples
Número de nós x Custo por hora
Sem custo para o nó líder
Pague pelo uso
19.
Amazon Redshift éfácil de usar
• Provisionamento em Minutos
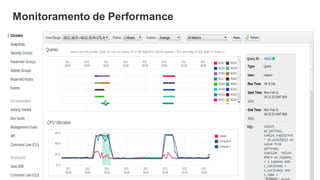
• Monitoramento de Performance
• Elasticidade simples
• Segurança embutida
• Backups automáticos
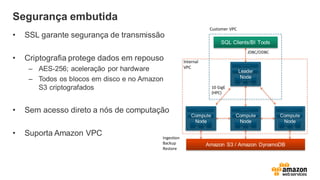
Segurança embutida
• SSLgarante segurança de transmissão
• Criptografia protege dados em repouso
– AES-256; aceleração por hardware
– Todos os blocos em disco e no Amazon
S3 criptografados
• Sem acesso direto a nós de computação
• Suporta Amazon VPC
10 GigE
(HPC)
Ingestion
Backup
Restore
Customer VPC
Internal
VPC
JDBC/ODBC
24.
Amazon Redshift: OperaçãoSimples
• Replicação de dados em múltiplos nos e copia para S3 garante durabilidade.
• Backups para Amazon S3 contínuo, automático e incremental.
– Projetado para 11 noves de durabilidade
• Monitoramento contínuo e recuperação automática de falhas de drives e nós
• Capaz de restaurar para qualquer zona de disponibilidade (AZ) dentro de uma região
25.
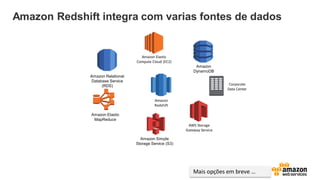
Amazon Redshift integracom varias fontes de dados
Amazon
DynamoDB
Amazon Elastic
MapReduce
Amazon Simple
Storage Service (S3)
Amazon Elastic
Compute Cloud (EC2)
AWS Storage
Gateway Service
Corporate
Data Center
Amazon Relational
Database Service
(RDS)
Amazon
Redshift
Mais opções em breve …
26.
Amazon Redshift váriasopções de carga de dados
• Amazon S3
• AWS Direct Connect
• AWS Import/Export
• Parceiros
Mais opções em breve …
Data Integration Systems Integrators
Dicas Práticas paracomeçar com Redshift
• Prepare-se para adaptar seu processo ETL/ELT para tirar vantagem das
características da Amazon Cloud
• Reserve tempo para testar configurações diferentes
– Distkey, sortkey, ,compressão
– Número de nós e filas (WLM)
• Use S3/Glacier para arquivamento de dados (UNLOAD)
• Simule partições cronológicas com tabelas separadas e visões
• Considere Carga -> Duplicação -> Consultas para situações apropriadas
• De-normalize apenas para evitar JOIN onde distkey das tabelas não casa