Baixado 32 vezes


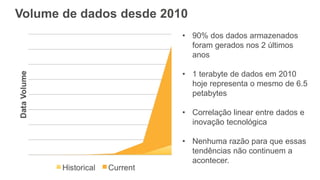
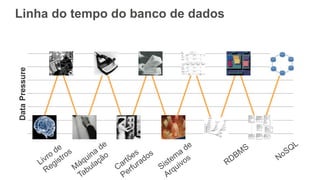
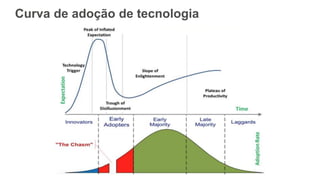

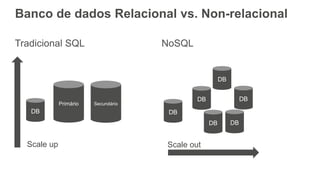



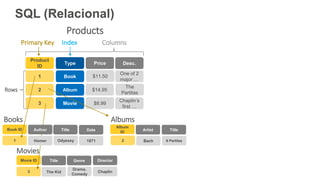
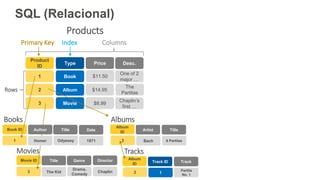
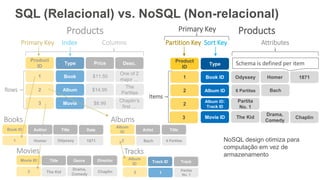
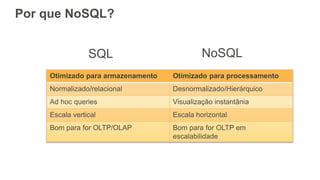
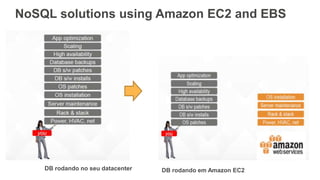


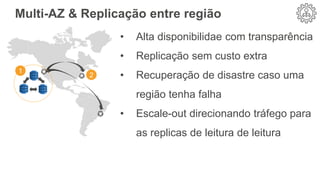

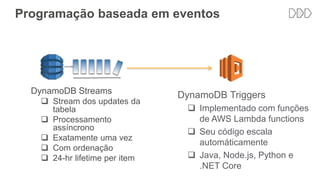
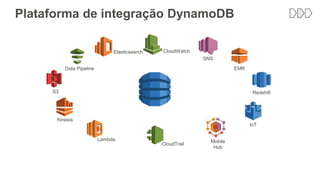
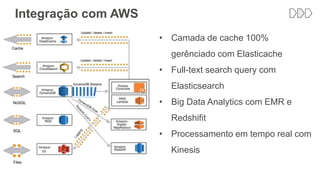

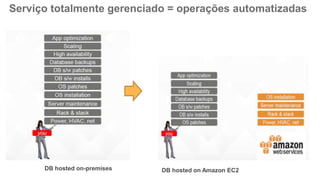
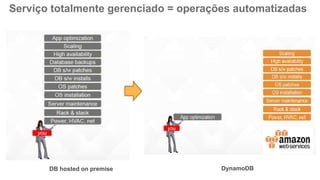
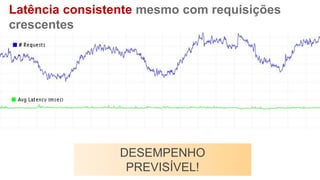
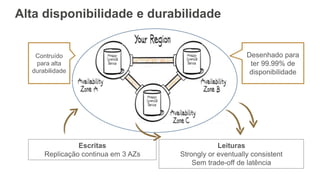





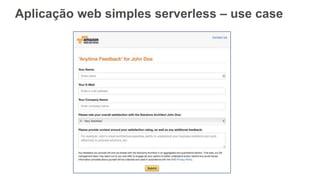
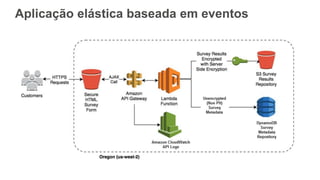
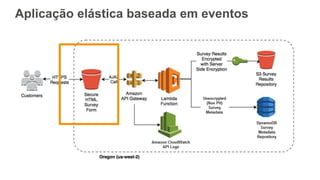
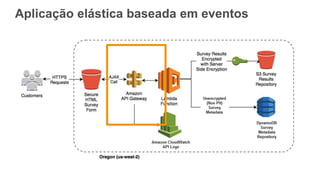
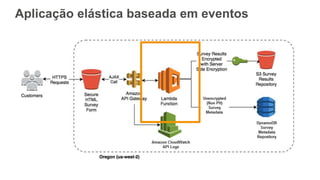
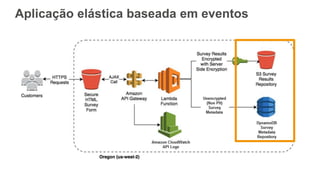



O documento discute como o DynamoDB da AWS pode ser usado para construir aplicações serverless escaláveis com armazenamento não relacional. Ele resume como o DynamoDB oferece desempenho previsível e alta disponibilidade para casos de uso como MLBAM e Duolingo, e como ele pode integrar-se com outros serviços da AWS como Lambda e API Gateway para criar aplicações baseadas em eventos.

























![[Webinar] AWS Storage Day - Português](https://cdn.slidesharecdn.com/ss_thumbnails/storageday-15052018pt-180518151634-thumbnail.jpg?width=640&height=640&fit=bounds)









































