Baixar para ler offline






















![“A AWS permite que nosso time se concentre no core do
problema que estamos resolvendo”
O QEdu é uma empresa de tecnologia
investida pela Fundação Lemann que tem
o propósito de transformar a educação
pública no Brasil por meio de tecnologia,
dados e análises
Atualmente servimos nossos clientes por
meio de uma plataforma web para
visualização de dados
INSERIR LOGO
Com AWS sabemos que
podemos sonhar
grande e que teremos
todo o apoio para escalar
nosso sonho de garantir o
aprendizado
adequado para todos
os alunos do Brasil”
[César Wedemann, CEO]](https://image.slidesharecdn.com/bsb-buildingdatalakesandanalyticsptbr-190923143446/85/AWS-Initiate-Construindo-Data-Lakes-e-Analytics-com-AWS-40-320.jpg)


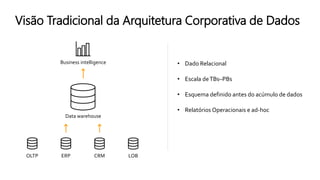
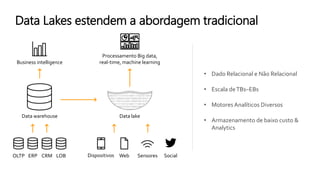
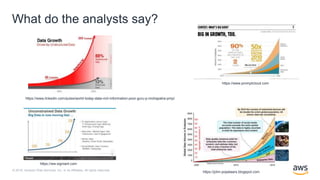
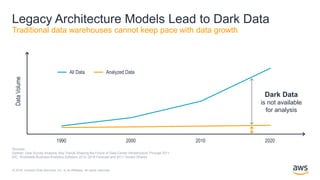
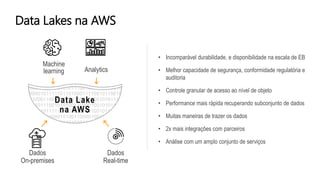
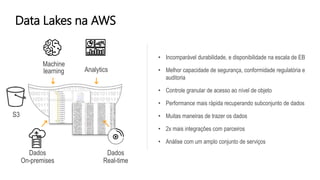
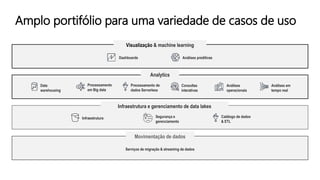
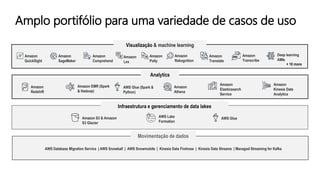
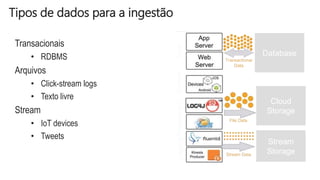
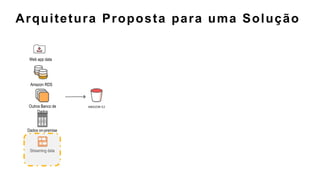
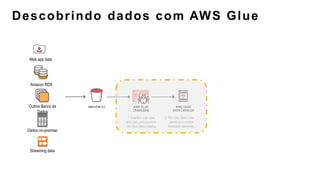
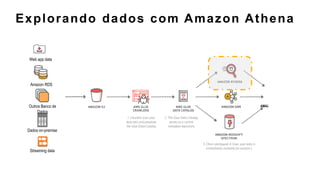
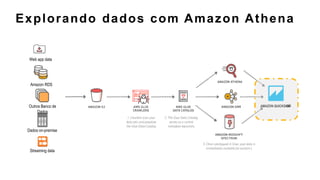
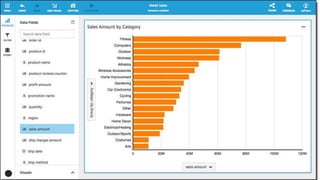
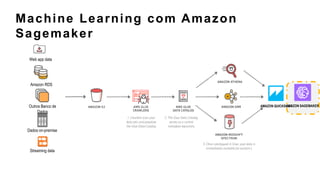
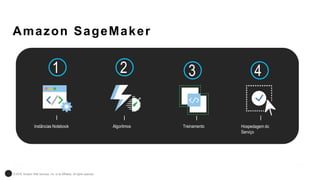
O documento discute a construção de data lakes para o governo usando a AWS. Ele descreve como data lakes estendem a abordagem tradicional de arquitetura de dados corporativos para lidar com o crescimento e diversidade de dados. Também apresenta casos de uso de vários serviços da AWS como Amazon S3, Amazon Athena, Amazon QuickSight e Amazon SageMaker para armazenar, explorar, visualizar e analisar dados em data lakes governamentais.
































![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DTC21] André Marques - Jornada do Engenheiro de Dados](https://cdn.slidesharecdn.com/ss_thumbnails/jornadadoengenheirodedados-210317153718-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Data Lake + Arquitetura Lambda] na prática](https://cdn.slidesharecdn.com/ss_thumbnails/dl-al-191211232344-thumbnail.jpg?width=640&height=640&fit=bounds)























