Baixado 45 vezes



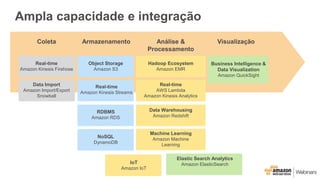


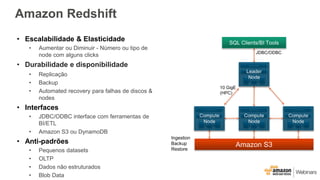
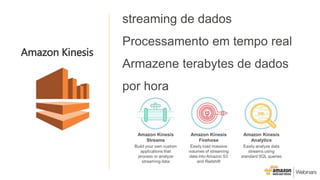

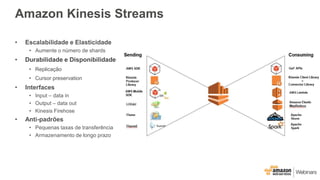


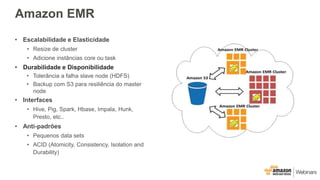




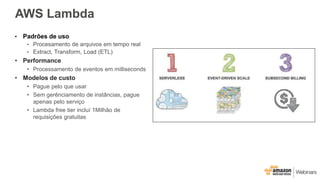









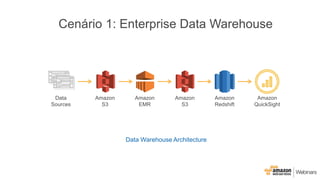
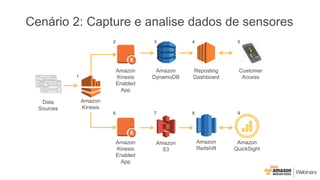
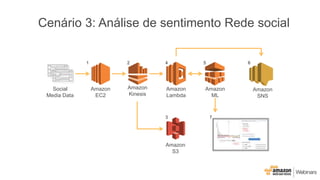


Este documento apresenta as principais opções de análise de big data na AWS, incluindo Amazon Redshift, Amazon EMR, Amazon DynamoDB, Amazon Machine Learning e Amazon Elasticsearch Service. Ele também discute padrões de uso, desempenho, custos, escalabilidade e interfaces para cada serviço, além de fornecer três exemplos de cenários de big data.
















































































