Transferir como PDF, PPTX






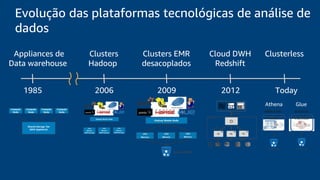
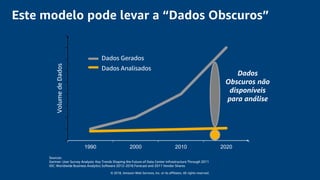


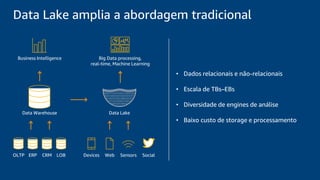

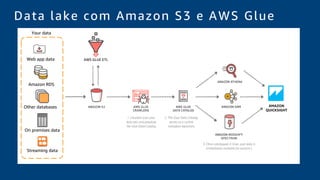

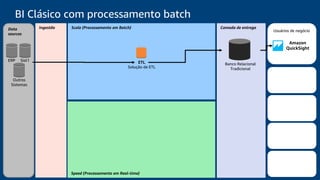
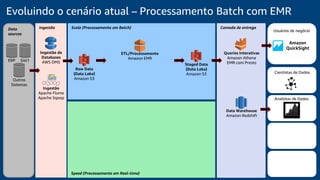
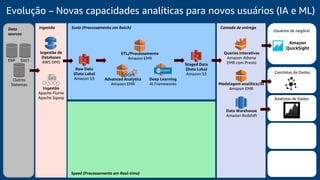
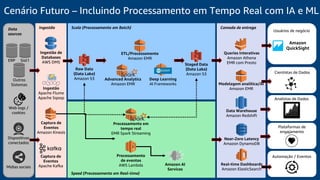



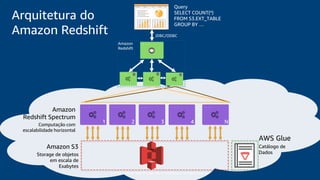
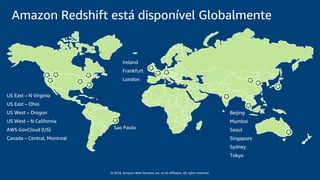
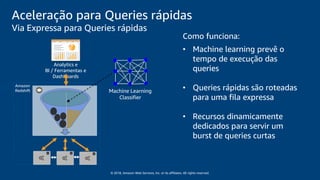





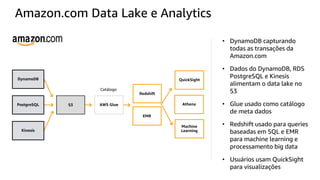
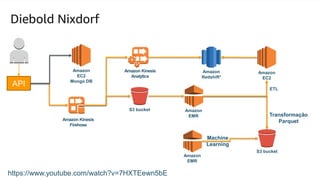



O documento discute a construção de um data warehouse moderno com o Amazon Redshift. Apresenta a evolução dos modelos de data warehouse tradicionais para os modernos, como funciona o Amazon Redshift e casos de clientes como a Amazon.com.















































