


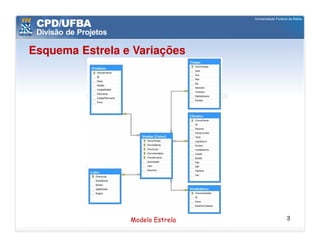

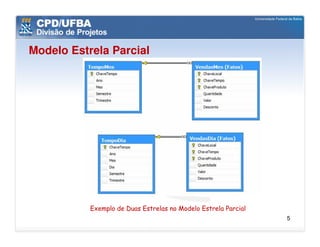
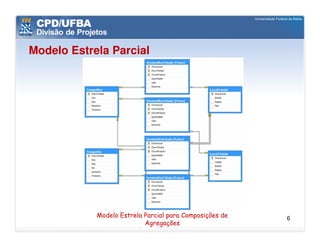

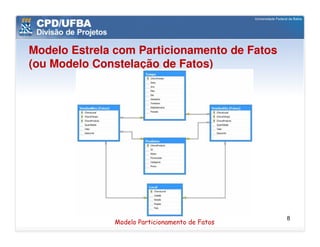

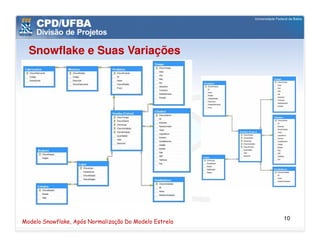
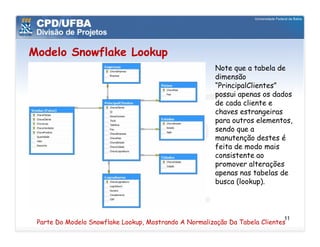
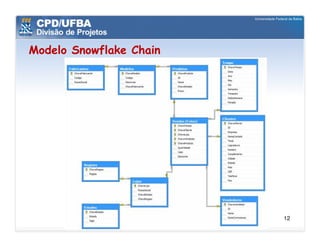

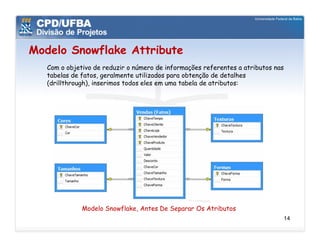





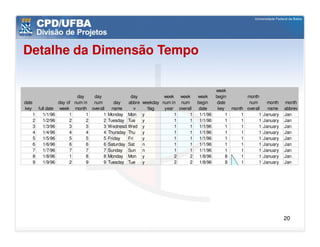



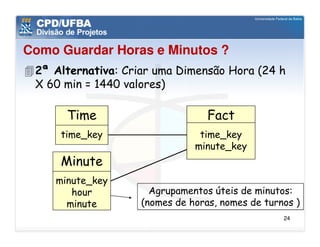



















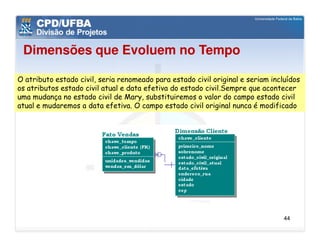
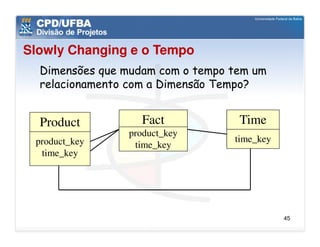


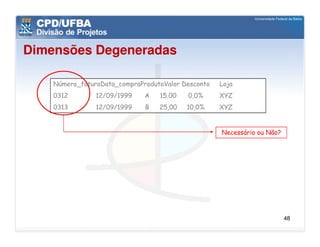










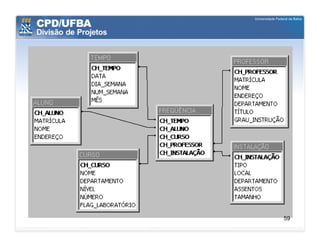


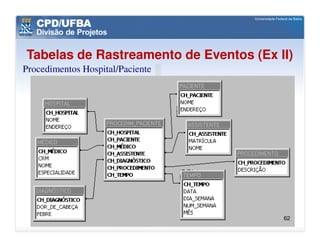
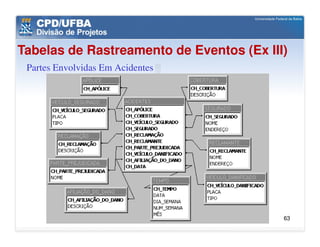
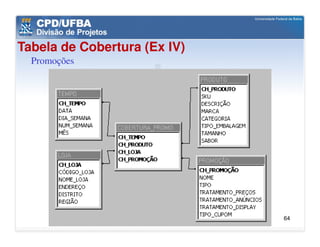



O documento discute vários aspectos avançados de modelagem dimensional, incluindo: (1) esquemas estrela e snowflake e suas variações, (2) dimensão tempo e como modelá-la, (3) dimensões que podem ter múltiplos papéis e (4) dimensões que evoluem no tempo (slowly changing dimensions).














































































