Transferir como PDF, PPTX








![Hash
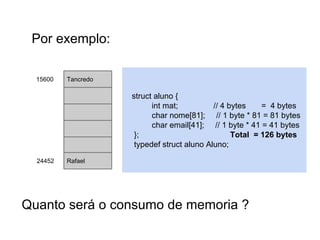
Por exemplo:
15600
Tancredo
struct aluno {
int mat;
char nome[81];
char email[41];
};
typedef struct aluno Aluno;
24452
Rafael
Quanto será o consumo de memoria ?](https://image.slidesharecdn.com/tabeladeespalhamentohash1-140124041017-phpapp01/85/Hash-e-Btree-10-320.jpg)
![Hash
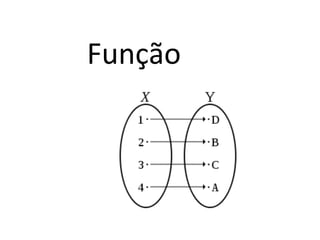
Por exemplo:
15600
Tancredo
struct aluno {
int mat;
// 4 bytes
= 4 bytes
char nome[81]; // 1 byte * 81 = 81 bytes
char email[41]; // 1 byte * 41 = 41 bytes
};
Total = 126 bytes
typedef struct aluno Aluno;
24452
Rafael
Quanto será o consumo de memoria ?](https://image.slidesharecdn.com/tabeladeespalhamentohash1-140124041017-phpapp01/85/Hash-e-Btree-11-320.jpg)
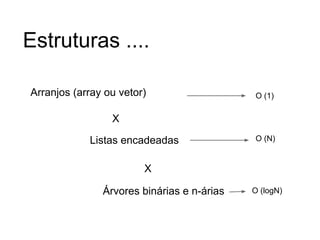














![Endereçamento fechado
Chained-Hash-Search(T,k)
procure um elemento com chave k na lista T[h(k)] e
devolva seu ponteiro
Chained-Hash-Insert(T,x)
insira x na cabeça da lista T[h(key[x])]
Chained-Hash-Delete(T,x)
remova x da lista T[h(key[x])]](https://image.slidesharecdn.com/tabeladeespalhamentohash1-140124041017-phpapp01/85/Hash-e-Btree-32-320.jpg)
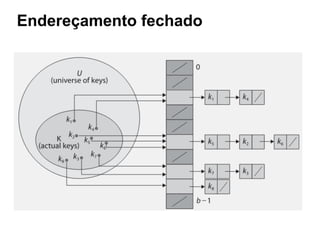
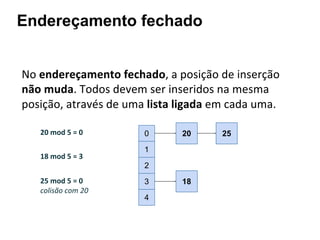
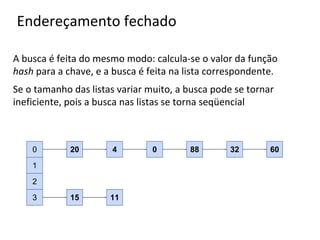
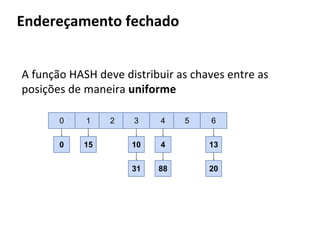











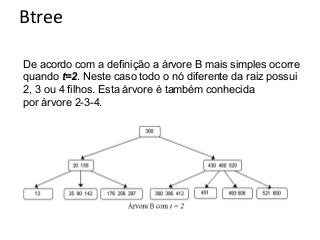
![Btree: Estrutura
Os elementos dentro de um nó estão ordenados.
O ponteiro situado entre dois elementos a e b aponta para a
sub-árvore que contém todos os elementos entre a e b.
a
<a
b
[a,b]
c
[b,c]
>c](https://image.slidesharecdn.com/tabeladeespalhamentohash1-140124041017-phpapp01/85/Hash-e-Btree-48-320.jpg)
![Btree: Definições (1)
1. Seja T uma árvore-B com raiz (root[T]). Ela possuirá então
as seguintes propriedades: 1. Todo o no X tem os seguintes
campos:
a. n[x], o numero de chaves atualmente guardadas no nodo x,
b. As n[x] chaves, guardadas em ordem crescente, tal que
key1[x] <= key2[x] <= … <= keyn[x]
c. leaf [x], Um valor booleano, TRUE se x e uma folha e FALSE
se x e um nodo interno
MO637 – Complexidade de Algoritmos I Arvores
B
Baseado no livro do Cormem](https://image.slidesharecdn.com/tabeladeespalhamentohash1-140124041017-phpapp01/85/Hash-e-Btree-49-320.jpg)
![Btree: Definições (2)
2. Cada no interno x tambem contem n[x] + 1 apontadores c1[x],
c2[x],...,cn[x]+1[x] para os filhos. As folhas tem seu apontador
nulo
3. As chaves keyi[x] separam os intervalos de chaves guardadas
em cada sub-arvore: se ki e uma chave guardada numa subarvore com raiz ci[x], entao:
k1 ≤ key1[x] ≤ k2 ≤ key2[x] ≤...≤ keyn[x] ≤ kn+1
4.Todas as folhas da árvore estão no mesmo nível.
Baseado no livro do Cormem](https://image.slidesharecdn.com/tabeladeespalhamentohash1-140124041017-phpapp01/85/Hash-e-Btree-50-320.jpg)


![Btree: Codificação
Considerando que os elementos dentro de um nó x da
B-tree esteja organizado de forma linear, e que:
n[x] = quantidade de chaves no nó x
keyi[x] = valor da chave do nó x na posição i
leaf[x] = retorna verdadeiro caso o nó seja folha
Operações de acesso
Disk-Read = operação de leitura do nó em disco
Disk-Write = operação de leitura do nó em disco](https://image.slidesharecdn.com/tabeladeespalhamentohash1-140124041017-phpapp01/85/Hash-e-Btree-54-320.jpg)




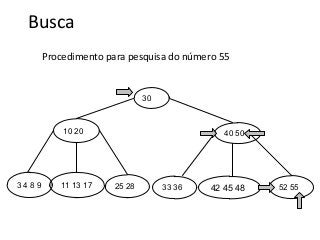

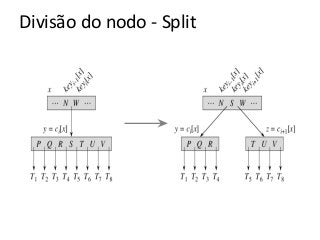

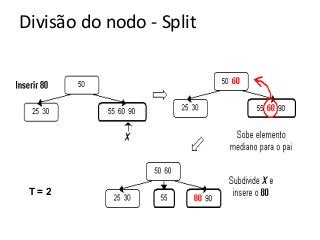
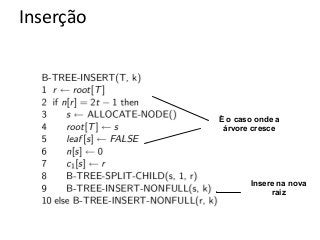

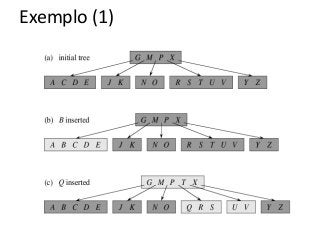
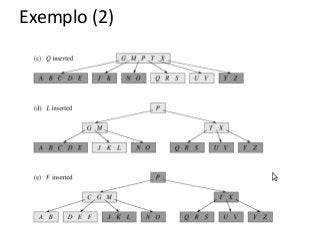

![Atividade
A partir de uma árvore B vazia (t=2):
●Insira os seguintes valores (20,30,50,80, 12, 15)
●Agora remova o 50, 80
A partir de uma árvore B vazia (t=3)
●Insira os valores [40,60,80,90,100,20,105,12]
●Remova os valores [90,12,40,100]](https://image.slidesharecdn.com/tabeladeespalhamentohash1-140124041017-phpapp01/85/Hash-e-Btree-69-320.jpg)



Este documento apresenta um resumo sobre índices em bancos de dados, comparando as estruturas de hash e Btree. Apresenta as definições e propriedades básicas dessas estruturas, como distribuição uniforme de valores, tratamento de colisões, grau mínimo de nós e organização linear de elementos.



































































