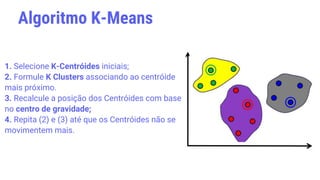
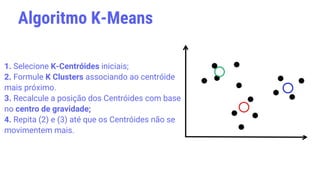
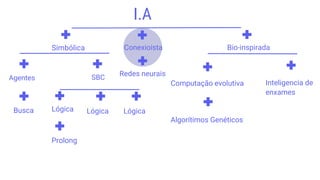
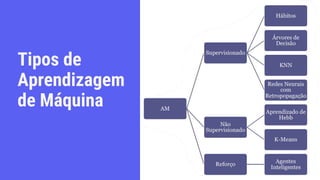
O documento discute os conceitos fundamentais de aprendizagem de máquina, incluindo: (1) definições de aprendizagem de máquina e tipos como aprendizagem supervisionada e não supervisionada, (2) métodos como árvores de decisão, redes neurais e k-means, (3) aplicações em diagnósticos médicos e análise de crédito/risco.





![Aprendizagem de máquina : Definição
Subárea da inteligência artificial (também conhecida
como machinelearning ) que estuda se (e como ) é
possível que maquinas consigam aprender e classificar
entrada de dados, muitas vezes baseados em outras
classificações pré estabelecidas [COPPIN,2010,p.234]
Formalmente falando
Onde x1,x2,….xn são dados de entrada (potencialmente
de diferentes tipos) e y é uma possível classificação.](https://image.slidesharecdn.com/machinelearning-230625013324-3119bb81/85/Machine-learning-pptx-6-320.jpg)

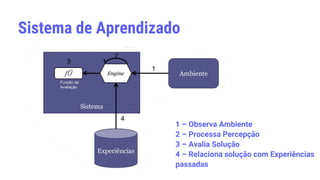
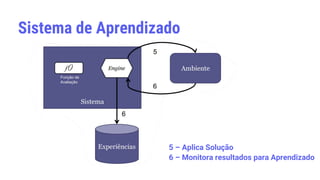
![Método de Aprendizagem Indutiva
• De acordo com [MITCHELL, 1997]: “Um programa aprende a
partir da experiência E em relação a uma classe de tarefas T,
com medida de desempenho P, se seu desempenho em T,
medido por P, melhora com E.”
• Exemplo extraído de [COELHO, 2008]
▫ Tarefa T: analisar se uma paciente responderá positivamente ao
tratamento quimioterápico pré-cirúrgico;
▫ Medida de Desempenho P: número de casos descobertos onde a
quimioterapia não surtiria efeito;
▫ Experiência: base de dados médicas com informações genéticas
das pacientes e dos tumores.](https://image.slidesharecdn.com/machinelearning-230625013324-3119bb81/85/Machine-learning-pptx-8-320.jpg)







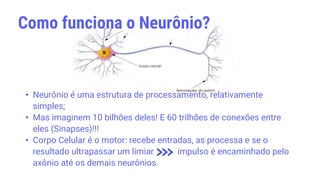
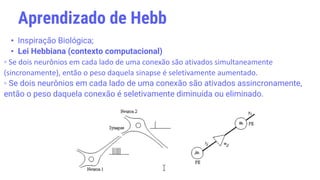
![• “Plasticidade neuronal é o nome dado a essa capacidade que os neurônios
têm de formar novas conexões a cada momento.” Dr. Drauzio Varela.
• Neurônios que se adaptam Aprendizagem!
• “Aprendizagem é um processo no qual os parâmetros livres de uma rede neural
são adaptados através de um processo de estimulação do meio-ambiente no
qual a rede está inserida. O tipo de aprendizagem é determinado pela maneira
que ocorrem as mudanças nos parâmetros.” [HAYKIN, 1999].
Neurônio - Plasticidade
Brotamento Colateral](https://image.slidesharecdn.com/machinelearning-230625013324-3119bb81/85/Machine-learning-pptx-24-320.jpg)