Baixado 1.390 vezes






















![36
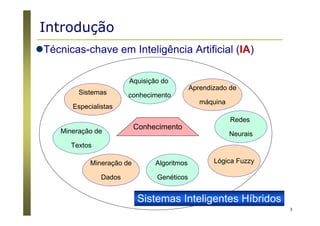
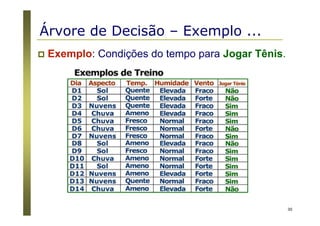
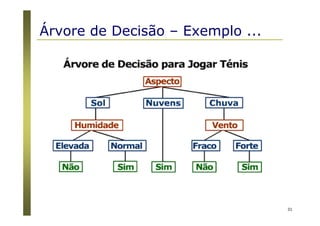
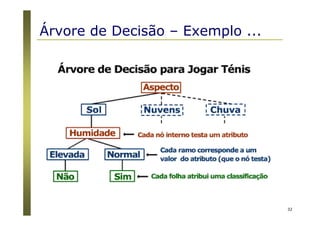
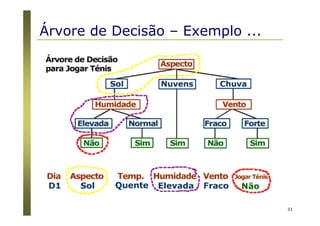
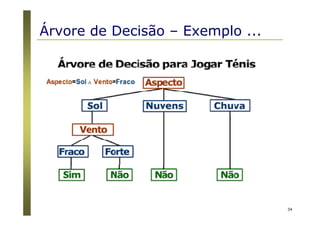
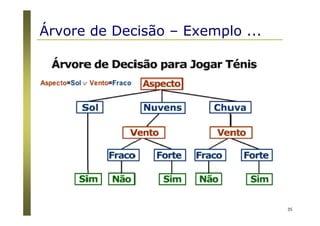
Algoritmos para árvores de decisão
Algoritmo Básico (algoritmo guloso)
A árvore é construída recursivamente no sentido top-down
(divisão para conquista).
No início, todas as amostras estão na raiz.
Os atributos são nominais (se numéricos, eles são discretizados).
Amostras são particionadas recursivamente com base nos
atributos selecionados.
Atributos “testes” são selecionados com base em heurísticas ou
medidas estatísticas (ex., ganho de informação) [ID3 / C4.5]
Condições de parada do particionamento
Todas as amostras de um nó pertencem a mesma classe.
Não existem mais atributos para particionamento.
Não existem mais amostras no conjunto de treinamento.](https://image.slidesharecdn.com/aprendizadomaquina-170408162539/85/Introducao-a-Aprendizagem-de-Maquina-36-320.jpg)



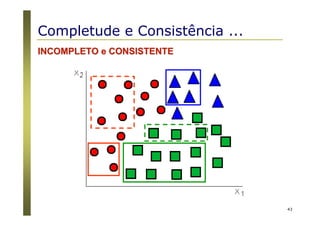
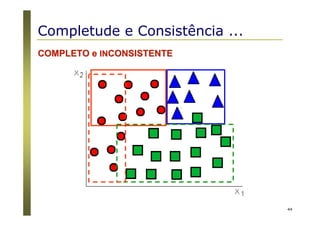
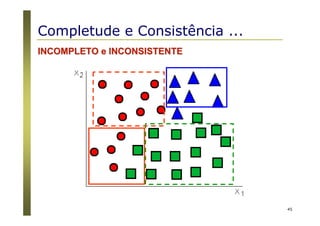
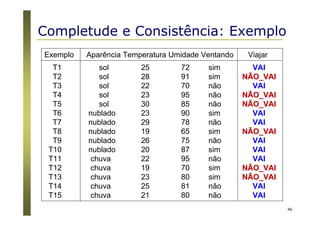
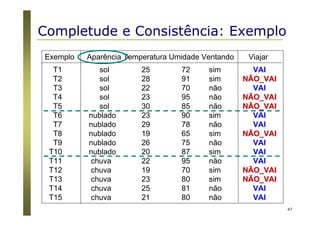
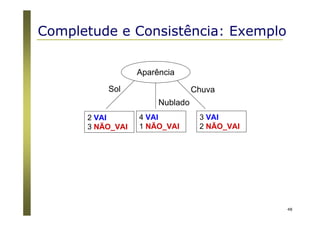
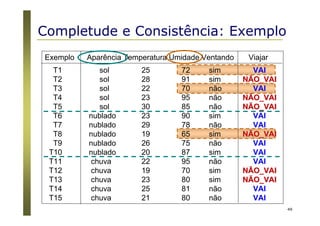
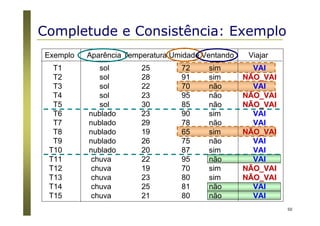
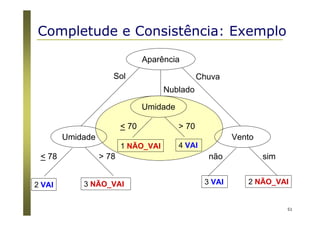
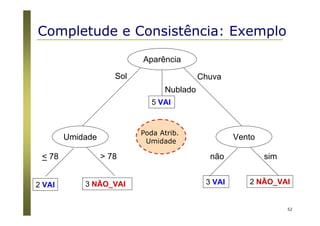





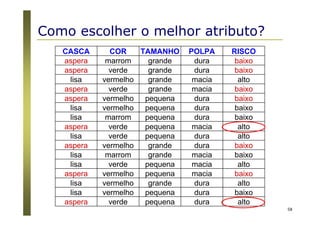




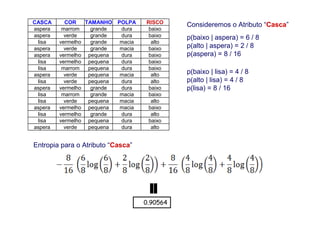
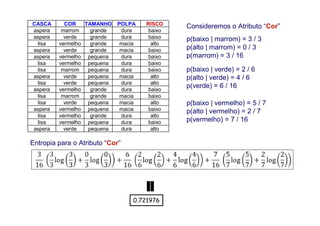
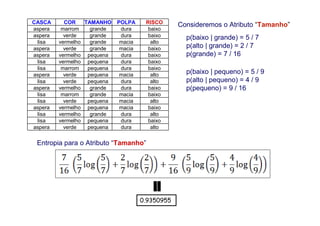
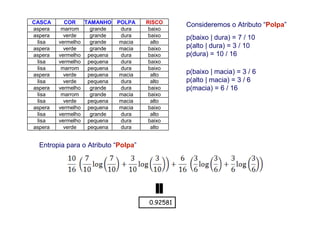

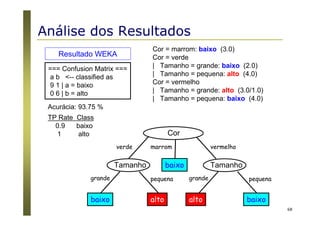

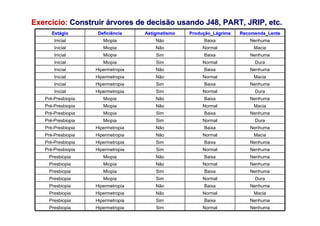

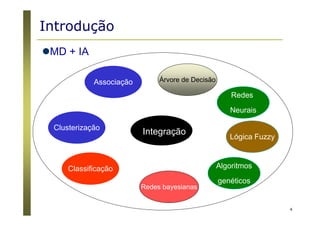
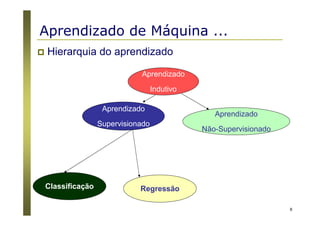
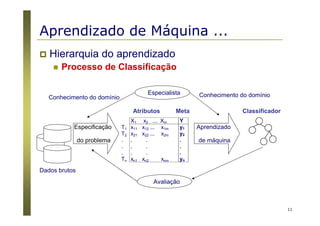
O documento apresenta uma introdução aos conceitos básicos de aprendizagem de máquina, incluindo classificação de dados, árvores de decisão e algoritmos. Aborda tópicos como processos de classificação, características de bons classificadores, métodos de classificação e algoritmos, conceitos de árvores de decisão e algoritmos para geração de árvores.






































![[José Ahirton Lopes] Treinamento - Árvores de Decisão, SVM e Naive Bayes](https://cdn.slidesharecdn.com/ss_thumbnails/treinamentodeveloperssp-180611021639-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DTC21] Raphael Castilho - Começando com Inteligência Artificial e Machine Le...](https://cdn.slidesharecdn.com/ss_thumbnails/iaemachine-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)


























