Baixado 202 vezes




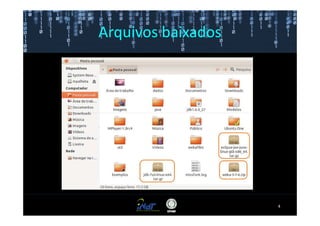

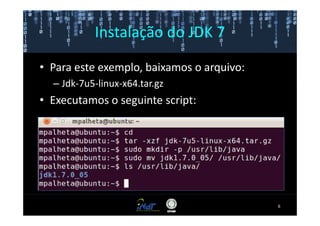


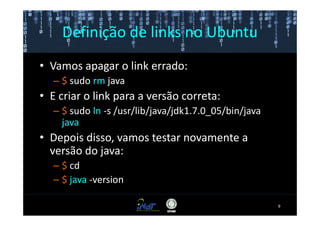
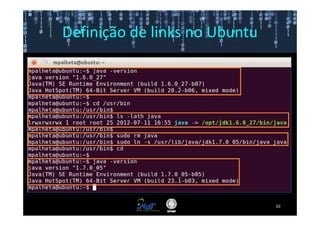
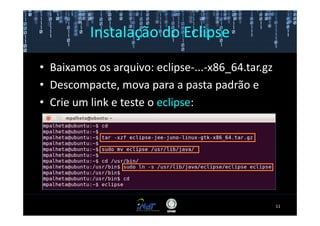
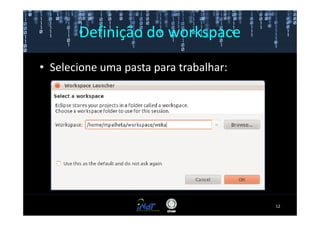
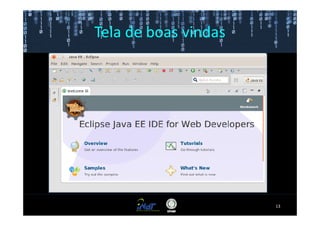


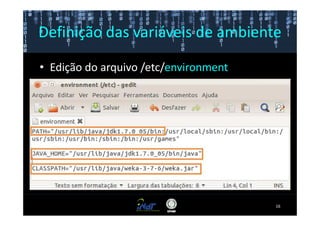
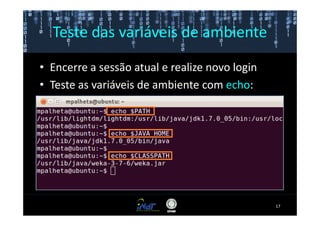



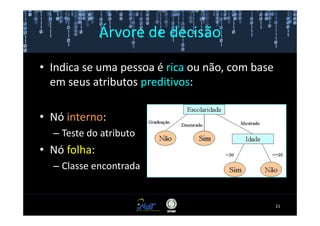

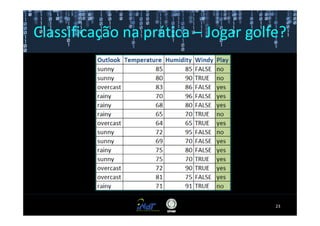


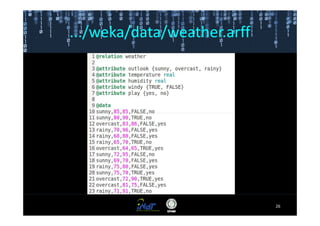

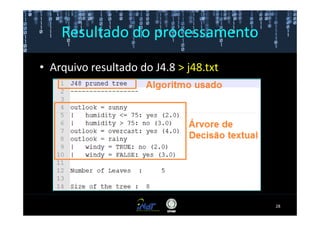
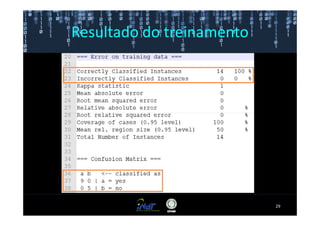
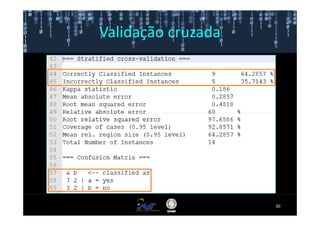






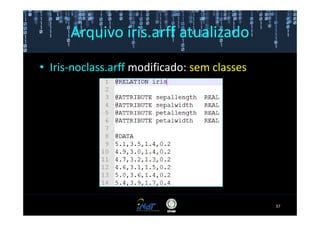

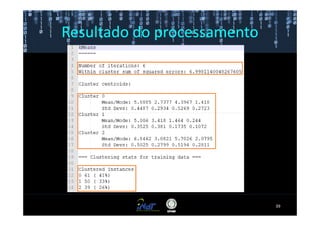





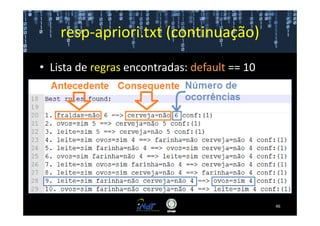




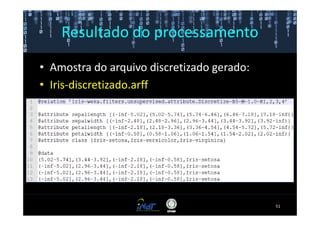


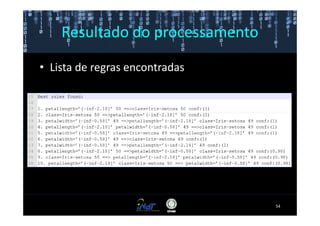

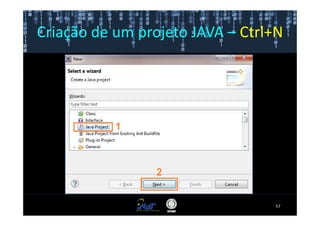
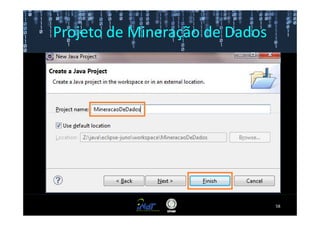
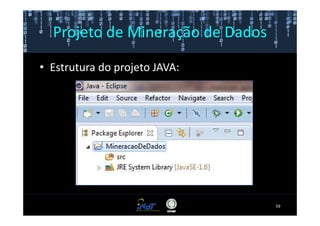
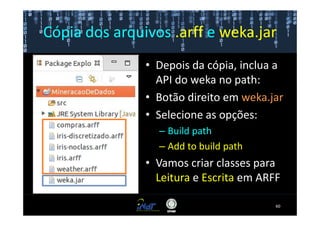
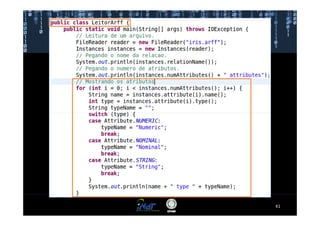
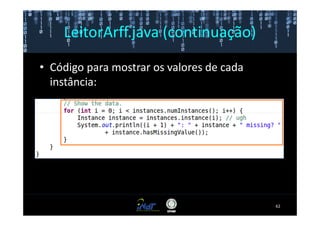
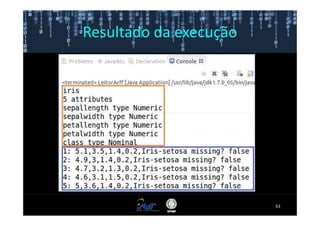




Este documento fornece instruções passo a passo para instalar e configurar o ambiente de desenvolvimento necessário para utilizar a ferramenta WEKA de mineração de dados. Ele descreve como baixar e instalar o Java SDK, WEKA e Eclipse, e configurar as variáveis de ambiente. Também apresenta exemplos de uso de alguns algoritmos do WEKA, como árvore de decisão, K-Means e Apriori.












































































