Transferir como PDF, PPTX


![Definição
Replicação é a manutenção de cópias idênticas
de dados em locais diferentes.
Segundo [Ikematu 2005], o objetivo de um
mecanismo de replicação de dados é permitir a
manutenção de várias cópias idênticas de um
mesmo dado em vários sistemas gerenciadores
de banco de dados (SGBD).
17](https://image.slidesharecdn.com/replicacao-090814172430-phpapp01/85/Replicacao-de-dados-2-320.jpg)




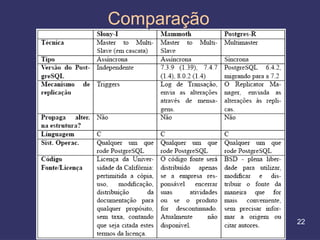
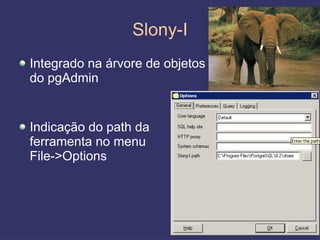
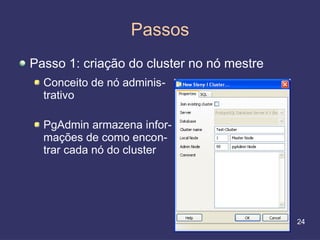
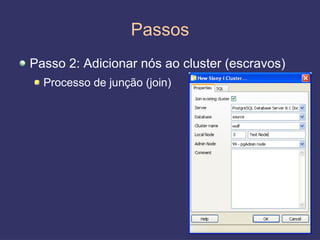
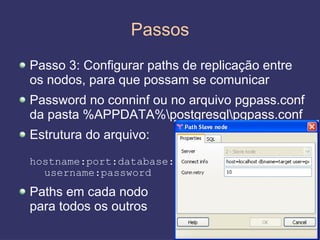
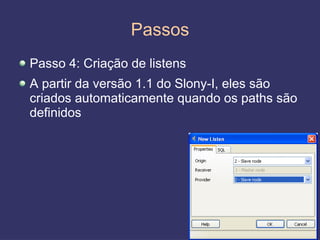
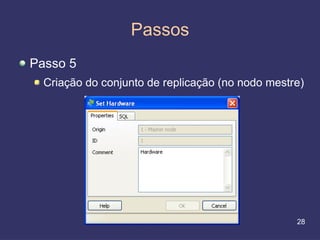
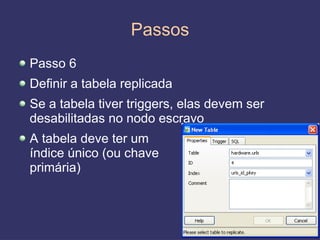
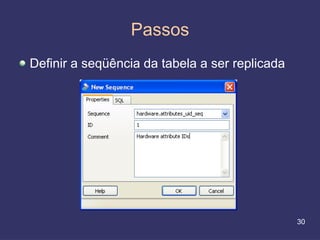
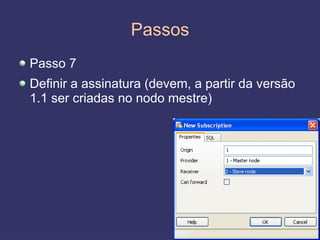


O documento discute replicação de dados, incluindo vantagens e desvantagens, definição, tipos (assíncrona e síncrona), técnicas (master-slave e multimaster) e ferramentas como o Slony. O Slony permite replicação de dados no PostgreSQL de forma integrada ao pgAdmin.










































































