Baixado 398 vezes


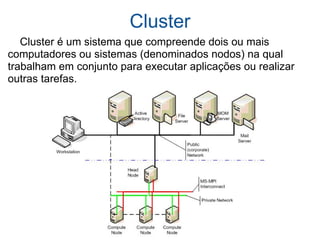



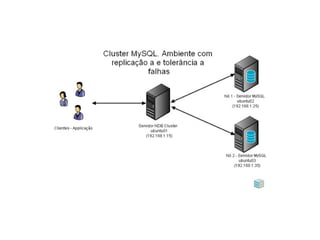


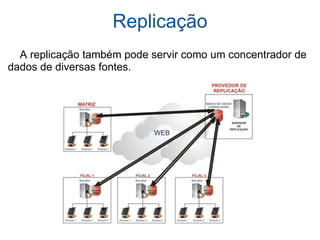





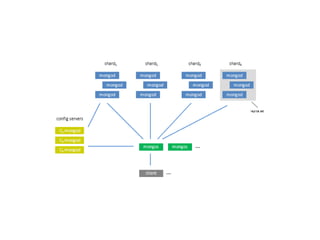







Cluster de banco de dados e replicação. Discute três tipos de clusters de banco de dados (shared all, shared disc, shared nothing) e quatro tipos de replicação (síncrona, assíncrona, multimaster, master/slave). Também descreve ferramentas de replicação como pgpool-II, Slony-I e Postgres-R.























































































