1. O documento apresenta os conceitos e um exemplo de aplicação do Perceptron e MLP (Multilayer Perceptron). É descrito o funcionamento do Perceptron em uma seção e do MLP em outra seção, com definições, vantagens e desvantagens.
2. O documento inclui listas de figuras, tabelas, abreviações e símbolos para auxiliar na compreensão dos conceitos apresentados.
3. São fornecidos códigos em R para implementação do Perceptron e MLP nos Apêndices do documento.






















![24 Capítulo 1. Perceptron
Algorithm 1 Perceptron em Pseudocódigo
1: function treinaPerceptron(dados, pesos)
2: n ← 0
3: erro ← 1
4: epocas ← 0
5: tam ← dimensaoV etorPesos
6: nRowsD ← quantidadeTotalDeLinhasDaMatrizDados
7: while (erro == 0) do
8: epocas ← epocas + 1
9: erroQ ← 0
10: mediaE ← 0
11: for i ← 1 to nrows do do
12: v ← 0
13: for j ← 1 to tam do do
14: v ← v + dados[i, j] ∗ pesos[j]
15: end for
16: y ← funcaoSinal(v)
17: erro ← desejado − y
18: erroQ ← erroQ + (erro ∗ erro)
19: if (desejado = y) then
20: erro ← 1
21: for j ← 1 to tam do do
22: pesos[j] ← pesos[j] + (n ∗ (desejado − y) ∗ dados[i, j])
23: end for
24: end if
25: end for
26: mediaE ← erroQ/nRowsD
27: end while
28: return pesos
29: end function
30: function testaPerceptron(exemplo, pesos)
31: v ← 0
32: for i ← 1 to tamanhoDoExemplo do do
33: v ← v + (exemplo[i] ∗ pesos[i])
34: end for
35: y ← funcaoSinal(v)
36: return y
37: end function](https://image.slidesharecdn.com/resumorna-180615181514/85/Perceptron-e-Multilayer-Perceptron-26-320.jpg)
![1.3. Algoritmo 25
cat("nEXEMPLO = ", i)
v <− 0
for(j in 1:tamP){
v <− v + dados[i,j]∗pesos[j]
}
y <− sign(v)
erro <− dados[i,4] − y
erroQ <− erroQ + (erro) ∗ (erro)
cat("n Erro Quadrático = ", erroQ)
if (dados[i ,4] != y){
erro <− 1
for(j in 1:length(pesos)){
pesos[j ] <− pesos[j] + (n∗(dados[i,4]−y)∗
dados[i,j ])
}
}
}
mediaErro <− mediaErro/nrow(dados)
cat("nnMédia do Erro Quadrático = ", mediaErro)
}
cat("nnFinalizado com ",epocas," épocasnn")
return(pesos)
}
# TESTE
perceptron2 <− function(exemplo,pesos){
cat("nn=====================================")
cat("nTESTE!")
v <− 0
for(i in 1:length(exemplo)){
v <− v + exemplo[i]∗pesos[i]
}
y <− sign(v)
cat("nn")
return(y)
}
Listing 1.2 – TreinaTestaPerceptron.R
setwd("caminho da sua pasta")](https://image.slidesharecdn.com/resumorna-180615181514/85/Perceptron-e-Multilayer-Perceptron-27-320.jpg)
![26 Capítulo 1. Perceptron
source(’Perceptron.R’)
# Conjunto de dados artificial
x1 <− c (4,2,5,3,1.5,2.5,4,5,1.5,3,5,4)
x2 <− c (5,4.5,4.5,4,3,3,3,3,1.5,2,1.5,1)
bias <− c (1,1,1,1,1,1,1,1,1,1,1,1)
classe <− c(1,−1,1,1,−1,−1,1,1,−1,−1,1,−1)
dados <− data.frame(x1,x2,bias,classe)
dados
# i = linha
# j = coluna
dados[1,4]
dados[2,4]
dados[3,4]
dados[4,4]
nrow(dados)
ncol(dados)
# Pesos iniciais gerados aleatoriamente
pesos <− runif(3,−1,1)
pesos <− t(pesos)
length(pesos)
novos.pesos <− perceptron2.treino(dados,pesos)
# Plot dos dados
cores <− dados$classe
cores[cores==−1] <− 2
plot(x1,x2,col=cores,pch=ifelse(dados$classe>0,"+","−"),cex=2,lwd=2)
# Hiperplano
intercept <− − novos.pesos[3] / novos.pesos[2]
slope <− − novos.pesos[1] / novos.pesos[2]
abline(intercept ,slope,col="green")
# Classifica novos dados
perceptron2(c(2,2,1) ,novos.pesos)
perceptron2(c(4,4,1) ,novos.pesos)](https://image.slidesharecdn.com/resumorna-180615181514/85/Perceptron-e-Multilayer-Perceptron-28-320.jpg)
![1.3. Algoritmo 27
Na Listing 1.2 o Algoritmo termina o treinamento após 12 épocas. Com essas
mesmas listagens de códigos fontes é possível fazer o treinamento e teste, de forma
adaptada, do banco de dados Iris, conforme apresenta a Listing 1.3
Listing 1.3 – PerceptronIris.R
setwd("caminho da sua pasta")
source(’Perceptron.R’)
# Definindo o uso do banco de dados iris
data( iris )
# dimensão (linhas x colunas)
dim(iris)
# nomes das colunas
names(iris)
# sumário das classes
summary(iris$Species)
# Vê como os atributos separam os dados
pairs( iris [,1:4], col=iris$Species)
# Pega Sepal Width e Petal Width
x <− cbind(iris$Sepal.Width,iris$Petal.Width)
x
# Rouula Setosa como positivo e o resto como negativo
y <− ifelse( iris$Species == "setosa", +1, −1)
y
# Bias
bias <− rep(1,nrow(x))
bias
x <− cbind(x,bias)
x
# Classes](https://image.slidesharecdn.com/resumorna-180615181514/85/Perceptron-e-Multilayer-Perceptron-29-320.jpg)
![28 Capítulo 1. Perceptron
x <− cbind(x,y)
x
# Pesos iniciais gerados aleatoriamente
pesos <− runif(3,−1,1)
pesos
pesos <− t(pesos)
pesos
# Treina o perceptron
pesos. iris <− perceptron2.treino(x,pesos)
# Plota os dados
plot(x,cex=0.2)
points(subset(x,y==1),col="black",pch="+",cex=2)
points(subset(x,y==−1),col="red",pch="−",cex=2)
# Hiperplano
intercept <− − pesos.iris[3] / pesos. iris [2]
slope <− − pesos.iris[1] / pesos. iris [2]
abline(intercept ,slope,col="green")
# Classifica novos dados
perceptron2(c (2.5,0.3,1) ,pesos. iris )
perceptron2(c (2.5,0.5,1) ,pesos. iris )
A função de ativação utilizada no Exemplo demonstrado em 1.2 pode ser substi-
tuída por outras, conforme o problema a ser resolvido. Apenas a título de curiosidade,
reimplemente os códigos aqui apresentados para resolver os problemas das portas lógicas
AND, OR, NAND, NOR e NOT. Faça também a resolução manual para conferir os
resultados, os pesos podem começar com 0.0 (ou 0.5) e a taxa de aprendizagem como 1 ou
0.5. Boa Sorte.](https://image.slidesharecdn.com/resumorna-180615181514/85/Perceptron-e-Multilayer-Perceptron-30-320.jpg)


















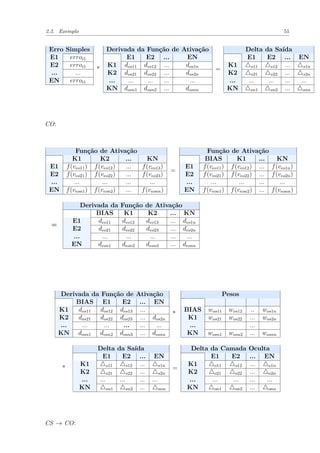




![56 Capítulo 2. MLP
# Conta quantas vezes executou o algoritmo
epocas <− 0
# Treina a RNA enquanto o erroQuadratico for menor que o limiar
while(erroQuadratico > limiar){
erroQuadratico <− 0
# Treina para todos os exemplos
for(i in 1:nrow(dados)){
# Pegando um exemplo de entrada
x.entrada <− dados[i, 1:arq$num.entrada]
# Classe do exemplo
x.saida = dados[i, ncol(dados)]
# Calcula o FEED FORWARD
resultado <− mlp.propagacao(arq, x.entrada)
# Saída do Neurônio
y <− resultado$y.oculta.saida
# 3. Calculando o Erro
# 3.a. Calculando o Erro Simples
erro <− x.saida − y
# 3.c. Calculando o Erro Quadrático
erroQuadratico = erroQuadratico + (erro ∗ erro)
# 4. Cálculo da Camada de Saída
# 4.a. e 4.b
delta.saida <− erro ∗ arq$derivada.funcao.ativacao(y)
# 5. Cálculo da Camada Oculta
# 5.a. e 5.b
pesos.saida <− arq$saida[,1:arq$num.oculta]
delta.oculta <− as.numeric(arq$derivada.funcao.ativacao(
resultado$y.entrada.oculta)) ∗ (delta.saida %∗% pesos.](https://image.slidesharecdn.com/resumorna-180615181514/85/Perceptron-e-Multilayer-Perceptron-58-320.jpg)


![2.3. Algoritmo 59
Figura 11 – Arquitetura sugerida MLP-IRIS
Dados[,1:4] <− scale(Dados[,1:4])
Dados
Dados <− Dados[sample(nrow(Dados)),]
Dados
treino <− createDataPartition(Dados$Species, p=.8, list = FALSE, times = 1)
treino
ncol(treino)
nrow(treino)
irisTreino <− Dados[treino,]
irisTreino
ncol( irisTreino )
nrow(irisTreino)
irisTeste <− Dados[−treino,]
irisTeste
ncol( irisTeste )
nrow(irisTeste)](https://image.slidesharecdn.com/resumorna-180615181514/85/Perceptron-e-Multilayer-Perceptron-61-320.jpg)
![60 Capítulo 2. MLP
Arquitetura <− Arquitetura(4,3,3,fa,dfa)
Arquitetura
treina <− BackPropagation(Arquitetura, irisTreino, 0.5, 1e−2)
treina
testa <− BackPropagation(Arquitetura, irisTeste, 0.5, 1e−2)
testa
Listing 2.5 – TestaMLP.R
#Lê o dataset iris
dados = iris
#Normaliza os dados
dados[,1:4]=scale(dados [,1:4])
#Randomiza os dados
dados=dados[sample(nrow(dados)),]
#Cria os k−folds com k = 10
num.folds = 10
folds <− createFolds(dados$Species, k = num.folds)
Arquitetura <− Arquitetura(4,3,3,fa,dfa)
Arquitetura
#Classifica os k folds
for(i in 1:num.folds){
treino = dados[unlist(folds [ setdiff (c(1:10) , i)]) ,]
teste = dados[folds[[ i ]],]
mlp.algoritmo = BackPropagation(Arquitetura, treino, 0.5, 1e−2)
cat(paste("Treinou MLP Fold",i,"n",sep=" "))
teste . reais = c(teste. reais , teste [, ncol(teste)])
}](https://image.slidesharecdn.com/resumorna-180615181514/85/Perceptron-e-Multilayer-Perceptron-62-320.jpg)



















![Inteligência Artificial Parte 6 [IA]](https://cdn.slidesharecdn.com/ss_thumbnails/cursoiamecatronica-parte11-redesneurais-141017065951-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)















































