1) O documento discute o uso de redes neurais supervisionadas e árvores de decisão para analisar os dados de uma concessionária de automóveis.
2) Os dados incluem informações sobre clientes e suas respostas a ofertas de garantia estendida.
3) As técnicas de aprendizagem de máquina são aplicadas usando o software Weka para identificar padrões nos dados e prever as respostas dos clientes.



![Introdução
Aprendizagem supervisionada e aquela que utiliza dados com a classe especificada a instancia ,
contem um atributo classe que especifica a qual classe ela pertence. Existem diversos métodos de
mineração que trabalham com este tipo de aprendizado.
A rede neural supervisionada chamada Perceptron multicamadas MLP- multilayer percetron [1]
utiliza métodos derivados do gradiente no ajustes de seus pesos por retro propagação (Back-Propagation).
Esta rede consiste de uma camada de entrada, uma ou mais camadas escondidas e uma ou mais camadas
de saída. Um sinal de entrada é propagado, de camada em camada, da entrada para a saída, esta saída
propaga-se em caminho reverso da saída para entrada alterando os pes os, para uma nova validação.
Estágios da aprendizagem por retro propagação do erro:
– Passo para frente: Estímulo aplicado à entrada é propagado para frente até produzir resposta da rede.
– Passo para trás: O sinal de erro da saída é propagado da saída para a entrada para ajuste dos pesos
sinápticos.
O algoritmo (Back-Propagation [2]) é baseado no método gradiente descendente, que computa
as derivadas parciais de uma função de erro, com relação ao vetor peso W de um vetor de entradas X. O
treinamento da rede é dividido em duas fases principais: avante (forward) e retorno (backward). A
primeira etapa (forward) consiste na propagação dos estímulos apresentados da entrada para a saída.
Esses estímulos fluem por toda a rede oculta, camada por camada até gerarem a saída. A partir do
resultado desejado (target), calcula-se o erro na camada de saída. A segunda etapa (backward) ocorre em
sentido contrário, onde o erro calculado é retropropagado pelas camadas antecessoras, atualizando os
pesos das conexões, produzindo novas saídas .
A MLP [1], apresenta varias características importantes dentre elas destacamos as seguintes :
Cada unidade de processamento tem função de ativação logística (forma sigmoidal) que é não-linear,
suave, diferençável e continua em todo o intervalo dados considerado.
Existência de pelo menos uma camada escondida que possibilita aprendizagem de tarefas
complexas por extração progressiva de características relevantes dos padrões de entrada. A existência de
mais camadas deve ser criteriosa escolhida visto que pode resulta em convergência mínima locais sem
saída consistente com resultados utilizáveis.
O grau de conectividade é alto.
Parâmetros a serem considerados em uma Rede Neural Artificial RNA [2].
Uma Rede Neural Artificial [2] do tipo Múltiplas Camadas com algoritmo de Retro propagação
(Back-Propagation [3]), necessita de vários parâmetros devem ser considerados: número de camadas de
neurônios, número de neurônios em cada camada, taxa de aprendizagem. Uma Rede Neural deve conter
no mínimo duas camadas de neurônios uma camada que se destina à entrada dos dados e outra que se
destina à saída dos resultados. Este tipo de rede apresenta uma utilidade muito limitada.
O aumento do número de camadas de neurônios melhora o desempenho das redes neurais. Sua
capacidade de aprendizado aumenta o que se traduz na melhoria da precisão com que ela delimita as
regiões de decisão (GORNI, 1993) [1]. Existe a necessidade de pelo menos uma camada oculta na Rede
Neural, mas não há determinação de qual numero ideal de camadas ocultas necessárias para o sistema.
Entretanto, a taxa de aprendizagem deve ser uma variável importante nas considerações do tempo de
aprendizagem desejado.
Na camada de entrada deve existir um número de neurônios igual ao número de variáveis a
serem fornecidos à rede. Eventualmente, uma variável de entrada pode ser subdividida para vários
neurônios, segundo um esquema binário, o que pode melhorar o desempenho.
A camada de saída deve conter um número de neurônios igual ao número de variáveis que se
deseja calcular. No caso de modelos classificatórios, pode-se utilizar um neurônio para cada item de
classificação ou utilizar uma representação mais compacta, pode ser empregado técnicas binárias para
diminuir o número de neurônios. O uso de representação binária na camada de saída aumenta a carga de
trabalho da camada oculta, obrigando a um aumento do número de neurônios dessa camada ou mesmo a
adição de uma camada oculta suplementar para que a Rede Neural mantenha o mesmo nível de
desempenho.
Vários autores sugerem critérios mínimos para a escolha do número de neurônios das camadas
ocultas. Outra questão a ser tratada por ocasião da programação de uma Rede Neural diz respeito aos
valores dos parâmetros da taxa de aprendizagem contida no algoritmo, esta taxa definida por um
coeficiente de aprendizado, deve ser alta no início do treinamento e vá diminuindo à medida que ele
evolui. (GORNI, 1993) [1], método que tem o propósito de proporcionar rapidez na convergência do
treinamento, estabilidade e resistência ao aparecimento de mínimos locais.](https://image.slidesharecdn.com/aredeneuralsupervisionadachamadaperceptronmulticamadas-141103030611-conversion-gate01/85/A-rede-neural-supervisionada-chamada-perceptron-multicamadas-3-320.jpg)
![Definição do problema - Base de Dados
O experimento foi realizado utilizando uma base de dados de uma concessionária HONDA que
contém quatro atributos de dados e três mil instancias.
A concessionária está começando uma campanha promocional, está tentando desenvolver uma
garantia estendida de dois anos para seus clientes passados.
O presente estudo utiliza a base de dados convertida em formato de valores separados em
vírgulas (CSV – Comma Separated Values) e estão no formato ARFF [4], compatível com o programa
minerador de dados Weka [2]. Mesmo a base Honda possuindo quatro atributos e três mil instancias.
Foram utilizados todos os atributos uma vez que todas estas características são relevantes para os testes.
Atributos do conjunto de dados são:
Faixa de renda
Ano / mês primeiro Honda
Ano / mês mais recente Honda
E Se eles responderam à oferta de garantia estendida no passado.
Para análise e quantificação presente na base de dados da concessionária Honda foi utilizado o
processo de mineração de dados, através do software Weka [2].
O Weka [2] é um software desenvolvido na Universidade de Waikato na Nova Zelândia, escrito
em linguagem Java, possui chave de licença pública e código aberto. Os dados po dem ser carregados no
Weka utilizando o formato de Arquivo de Atributo Relação (ARFF) [5]. Nesse arquivo é definida cada
coluna com um tipo de dado, por exemplo, numérico ou caractere, em cada linha é fornecido os dados,
com seus respectivos tipos de dados, delimitados por vírgulas.
Metodologia
Definição da configuração da rede:
Seleção da rede neural apropriada à aplicação, que tipo de rede será utilizado;
Determinação da topologia da rede a ser utilizada - o número de camadas escondidas e o número
de unidades em cada camada;
Determinação dos parâmetros do algoritmo de treinamento e funções de ativação.
Opções de visualização e configuração do WEKA
GUI - traz uma interface GUI. Isto irá permitir uma interação mais aprimorada com opções de
pausa e alteração da Rede Neural Artificial durante o treino.
* Para adicionar um nó à esquerda, clique (este nó será selecionado automaticamente, tem que
ter certeza de que não haja outros nós foram selecionados ).
* Para selecionar um nó com o botão esquerdo sobre ele, enquanto nenhum outro nó for
selecionado ou mantendo pressionada a tecla Control
* Para conectar um nó, primeiro tem o nó (s) de partida selecionado, em seguida, clique em nó
de extremidade ou em um espaço vazio (isto irá criar um novo nó que está conectado com os nós
selecionados). O estado de seleção de nós vai ficar na mesma depois que a conexão. (Nota essas conexões
são dirigidas, também uma conexão entre dois nós não será estabelecida mais de uma vez e certas
conexões que são consideradas inválidas não serão feitas).
* Para remover uma conexão, selecione um dos nó conectados e, em seguida, clique com botão
direito do outro nó (não importa se o nó é o início ou terminar a ligação será removido).
*Para remover um nó de clique direito, enquanto nenhum outro nó são selecionados.
*Para cancelar a seleção de um nó para a esquerda clique nele enquanto mantém pressionado o
controle, ou clique direito no espaço vazio.
*As entradas matérias são fornecidos os rótulos à esquerda.
*Os nós vermelhos são camadas ocultas.
*Os nós de laranja são os nós de saída.
*As etiquetas à direita mostra a classe do nó que a saída representa.
*Alterações à rede neural só podem ser feitas enquanto a rede não está funcionando, isso
também se aplica à taxa de aprendizagem e a outros campos no painel de controle.
* Pode-se aceitar a rede como sendo finalizada a qualquer momento.
* Na modelagem GUI a rede inicia-se automaticamente pausada.
* Há uma indicação de funcionamento de que época a rede está fazendo e o que o erro (bruto)
para a época era (ou para a validação se que está sendo usado). Note-se que este valor de erro se baseia
numa rede que muda quando o valor é calculado.
* Uma vez que a rede montada ele irá parar de novo e vai esperar o comando de aceito ou
continuar com o treinado.
Parâmetros opcionais a ser mudados
Autobuild - Adiciona e conectam-se as camadas ocultas na rede.](https://image.slidesharecdn.com/aredeneuralsupervisionadachamadaperceptronmulticamadas-141103030611-conversion-gate01/85/A-rede-neural-supervisionada-chamada-perceptron-multicamadas-4-320.jpg)
![Debug - Se verdadeiro, classificador pode emitir informações adicionais para o console.
Decaimento - Isto fará com que a taxa de aprendizagem para diminuir. Isto irá dividir a taxa de
aprendizagem começando pelo número época, para determinar que a taxa de aprendizagem atual deveria
ser. Isto pode ajudar a parar a rede de divergentes a partir da saída de destino, bem como melhorar a
performance geral. Note-se que a taxa de aprendizado em decomposição não será mostrado no gui, apenas
a taxa de aprendizagem original. Se a taxa de aprendizagem é alterado no gui, esta é tratada como a taxa
de aprendizado inicial.
hiddenLayers - Isso define as camadas ocultas da rede neural. Esta é uma lista de números
inteiros positivos. 1 para cada camada escondida. Separados por vírgulas. Para não têm camadas ocultas
colocar um único 0 aqui. Isso só será utilizado se AutoBuild está definido. Há também valores curinga 'A'
= (classes Attribs +) / 2, 'i' = attribs, aulas = 'O', = Attribs + aulas de 'T'.
learningRate - O valor dos pesos são atualizados.
impulso - Momentum aplicado aos pesos durante a atualização.
nominalToBinaryFilter - o que irá pré-processar as instâncias com o filtro. Isso poderia ajudar
a melhorar o desempenho se existem atributos nominais nos dados.
normalizeAttributes - Isso vai normalizar os atributos. Isso poderia ajudar a melhorar o
desempenho da rede. Este não é dependente do numérico ser classe. Isso também vai normalizar atributos
nominais, bem como (depois de terem sido executados, através do filtro de binário nominal se que está
em uso) de forma que os valores nominais são entre -1 e 1
normalizeNumericClass - Isso vai normalizar a classe se é numérico. Isso poderia ajudar a
melhorar o desempenho da rede, Normaliza a classe para estar entre -1 e 1 Note-se que este é apenas
internamente, a saída será reduzida para a faixa original.
redefinir - Este vai permitir que a rede de repor com uma taxa inferior a aprendizagem. Se a rede
diverge da resposta esta irá reiniciar automaticamente a rede com uma taxa de aprendizagem mais baixo e
começar a treinar novamente. Esta opção só está disponível se o gui não está definido. Note que se a rede
diverge, mas não tem permissão para redefinir ele irá falhar o processo de treinamen to e retornar uma
mensagem de erro.
semente - semente usada para inicializar os números generator.Random números aleatórios são
usados para definir os pesos iniciais dos nós conexões betweem, e também para embaralhar os dados de
treinamento.
trainingTime - O número de épocas para treinar completamente. Se o conjunto de validação é
diferente de zero, então ele pode terminar mais cedo rede
validationSetSize - A percentagem do tamanho do conjunto de validação (A formação irá
continuar até que se observa que o erro no conjunto de validação foi consistentemente a piorar, ou se o
tempo de formação é atingido)..
Se isso for definido para zero, nenhum conjunto de validação serão utilizados e, em vez da rede vai
treinar para o número especificado de épocas.
validationThreshold - Usado para terminar valor testes.O validação aqui dita quantas vezes
seguidas o erro conjunto de validação pode ficar pior antes do treino é encerrado.
Técnica de Aprendizado
Toda técnica de mineração passa por um processo chamado de treinamento , e nesta fase que
ocorre a apresentação dos dados processados para o algoritmo de mineração, cujo objetivo e identificar as
características ou padrões úteis para o processo de descoberta de conhecimento.
Apos o aprendizado ter sido realizado, e aplicada uma avaliação, onde podemos verificar
medidas estatísticas dos resultados alcançados. A utilização de dados inéditos fornecera medidas realistas
sobre o desempenho do algoritmo, o conjunto deve ser dividido em dados de treinamento e de teste.
Às vezes, e necessário dividir o conjunto de dados em 3 diferentes conjuntos: treinamento,
validação e teste. O conjunto de validação e utilizado para ajustar valores dos parâmetros de alguns
algoritmos e ao mesmo tempo uma boa generalização. Quando o conjunto de dados e divididos em dois,
geralmente a divisão e de 70% do conjunto para o conjunto de treinamento e 30% para o conjunto de
testes. Já, quando o conjunto será divido em 3 (três), usa-se a proporção 70% para treinamento, 20% para
validação e 10% para testes.
Árvore de Decisão
Para a realização da mineração de dados foi utilizado o filtro Discretize para a normalização dos
dados de entrada em um intervalo numérico. Após o filtro, foram selecionad os o algoritmo árvore de
decisão (J48) [6] e a Rede Neural Artificial (RNA) [2] MLP Multi-Layer Perceptron (MLP) [1].
O algoritmo J48 [6] constrói um modelo de árvore de decisão baseado num conjunto de dados de
treinamento, sendo que esse modelo é utilizado para classificar as instâncias de um conjunto de teste.](https://image.slidesharecdn.com/aredeneuralsupervisionadachamadaperceptronmulticamadas-141103030611-conversion-gate01/85/A-rede-neural-supervisionada-chamada-perceptron-multicamadas-5-320.jpg)
![O algoritmo MLP Multi-Layer Perceptron [1] [4] possui aprendizado supervisionado e tem o
objetivo calcular o erro para a camada de saída e propagar este no sentido saída -entrada
(backpropagation), ajustando os pesos de todas as camadas, através da retro propagação do erro.
Conjunto de dados WEKA
O conjunto de dados que usaremos para nosso exemplo de classificação estará focado em uma
concessionária fictícia da Honda. A concessionária está iniciando uma campanha promocional na qual
está tentando vender uma garantia estendida de dois anos para seus clientes passados. A concessionária já
fez isso antes e reuniu 4.500 pontos de dados de vendas antigas de garantias estendidas . Os atributos no
conjunto de dados são:
Colchete de renda
Ano/mês de compra da primeira Honda
Ano/mês de compra da Honda mais recente
Se eles responderam à oferta de garantia estendida no passado
Classificação da arvore de decisão
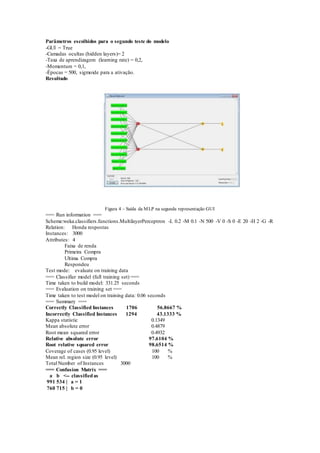
Figura 1. Classificação de dados da concessionária HONDA no WEKA
Para gerar a arvore de decisão do modelo foi utilizado o algoritmo J48
Figura 2. Classificação do resultado dos dados da concessionária HONDA no WEKA](https://image.slidesharecdn.com/aredeneuralsupervisionadachamadaperceptronmulticamadas-141103030611-conversion-gate01/85/A-rede-neural-supervisionada-chamada-perceptron-multicamadas-6-320.jpg)