Transferir como PDF, PPTX


























![The Perceptron [Rosenblatt, Psychol. Rev. 1958]:
um classificador linear](https://image.slidesharecdn.com/fas-dl-cnn2016-160901131714/85/Aprendizado-Profundo-CNNs-31-320.jpg)



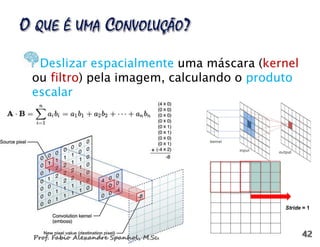
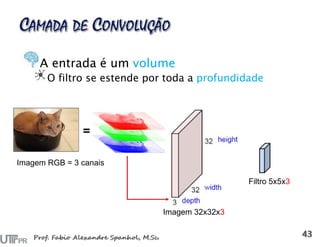
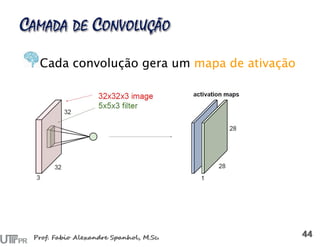


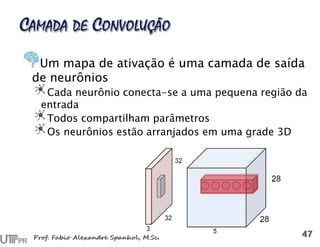
![Reconstrução da imagem a partir das
características extraídas
Understanding deep image representations by inverting them
[Mahendran and Vedaldi CVPR 2015]](https://image.slidesharecdn.com/fas-dl-cnn2016-160901131714/85/Aprendizado-Profundo-CNNs-52-320.jpg)
![LeNet [LeCun et al. 1998]
Gradient-based learning applied to document recognition [LeCun, Bottou, Bengio,
Haffner 1998]](https://image.slidesharecdn.com/fas-dl-cnn2016-160901131714/85/Aprendizado-Profundo-CNNs-53-320.jpg)


![Framework semelhante ao de [LeCun98], mas:
Modelo maior (7 hidden layers, 650 mil neurônios, 60
milhões de parâmetros)
Mais dados (106 vs. 103 imagens)
Mais poder computacional: Uso de GPU (50x speedup vs CPU)
• Trainada em duas GPUs por ~1 semana
A. Krizhevsky, I. Sutskever, and G. Hinton,
ImageNet Classification with Deep Convolutional Neural Networks, NIPS 2012](https://image.slidesharecdn.com/fas-dl-cnn2016-160901131714/85/Aprendizado-Profundo-CNNs-56-320.jpg)



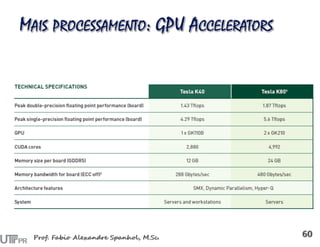
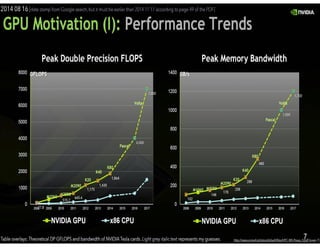
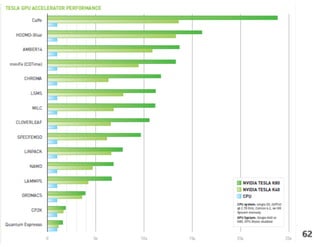
![Detecção de regiões (objetos contidos em retângulos)
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
[Ren et al. NIPS 2015]](https://image.slidesharecdn.com/fas-dl-cnn2016-160901131714/85/Aprendizado-Profundo-CNNs-63-320.jpg)
![Rotulagem de pixels Segmentação semântica
DeepEdge: A Multi-Scale Bifurcated Deep Network for Top-Down Contour Detection
[Bertasius et al. CVPR 2015]](https://image.slidesharecdn.com/fas-dl-cnn2016-160901131714/85/Aprendizado-Profundo-CNNs-64-320.jpg)
![Rotulagem de pixels Segmentação semântica
Fully Convolutional Networks for Semantic Segmentation [Long et al. CVPR 2015]](https://image.slidesharecdn.com/fas-dl-cnn2016-160901131714/85/Aprendizado-Profundo-CNNs-65-320.jpg)
![Criação de pinturas através de um exemplo e esboço
Semantic Style Transfer and Turning Two-Bit Doodles into Fine Artworks
[Champandard 2016]](https://image.slidesharecdn.com/fas-dl-cnn2016-160901131714/85/Aprendizado-Profundo-CNNs-66-320.jpg)
![Para regressão
DeepPose: Human Pose Estimation via Deep Neural
Networks [Toshev and Szegedy CVPR 2014]](https://image.slidesharecdn.com/fas-dl-cnn2016-160901131714/85/Aprendizado-Profundo-CNNs-67-320.jpg)
![Como métrica de similaridade para matching
FaceNet [Schroff et al. 2015]
Match ground and aerial images
[Lin et al. CVPR 2015]](https://image.slidesharecdn.com/fas-dl-cnn2016-160901131714/85/Aprendizado-Profundo-CNNs-68-320.jpg)
![Para geração automática de legendas de
imagens(image caption generator)
Show and Tell: A Neural Image Caption Generator [Vinyals et al. 2015]](https://image.slidesharecdn.com/fas-dl-cnn2016-160901131714/85/Aprendizado-Profundo-CNNs-69-320.jpg)
![Visual Question Answering
Deep Learning for Visual Question Answering [Singh 2015]](https://image.slidesharecdn.com/fas-dl-cnn2016-160901131714/85/Aprendizado-Profundo-CNNs-70-320.jpg)





O documento discute a evolução do aprendizado de máquina, incluindo abordagens como aprendizado supervisionado, não supervisionado e por reforço, enfatizando a importância de características significativas na modelagem de dados. Inclui uma análise de redes neurais, com foco em redes neurais convolucionais (CNNs) e suas aplicações, além de mencionar pesquisadores proeminentes na área. Por fim, apresenta ferramentas e recursos que facilitam o uso de aprendizado profundo e big data.

































![[Jose Ahirton lopes] Do Big ao Better Data](https://cdn.slidesharecdn.com/ss_thumbnails/ahirtonlopesdobigaobetterdata-190410143141-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Jose Ahirton Lopes] Deep Learning - Uma Abordagem Visual](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesdeeplearning-umaabordagemvisual-181209205137-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Jose Ahirton Lopes] Deep Learning - Uma Abordagem Visual](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesdeeplearning-umaabordagemvisual-181204182142-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Ahirton Lopes e Rafael Arevalo] Deep Learning - Uma Abordagem Visual](https://cdn.slidesharecdn.com/ss_thumbnails/ahirtonlopeserafaelarevalodeeplearning-umaabordagemvisual-190215183628-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Jose Ahirton Lopes] Inteligencia Artificial - Uma Abordagem Visual](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopes-meetupinteligenciaartificial-umaabordagemvisual-200215025106-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Jose Ahirton Lopes] Inteligencia Artificial - Uma Abordagem Visual](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesinteligenciaartificial-umaabordagemvisual-200103185454-thumbnail.jpg?width=640&height=640&fit=bounds)




















