Transferir como PDF, PPTX





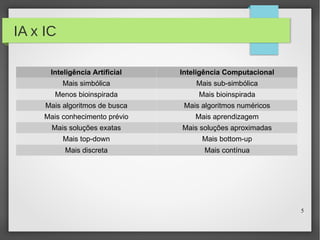






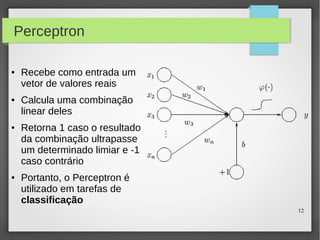

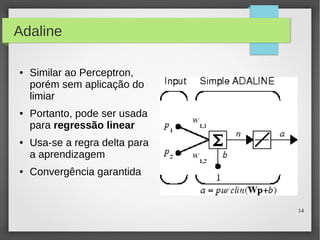
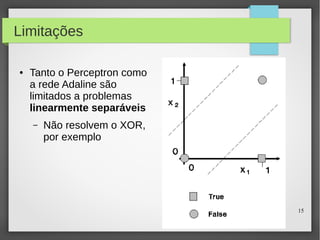
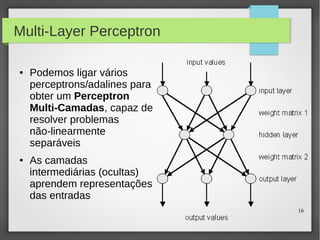
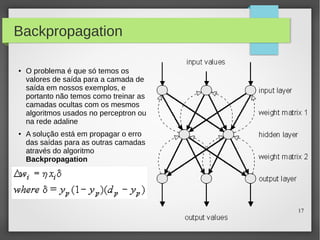
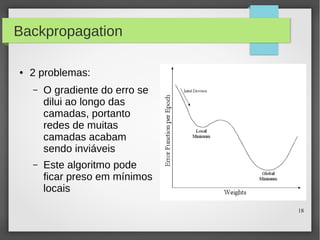
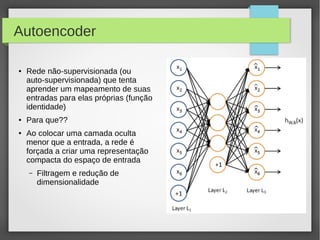





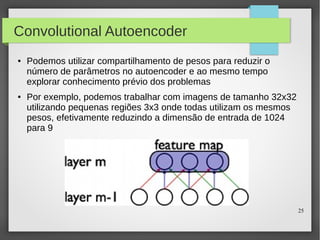
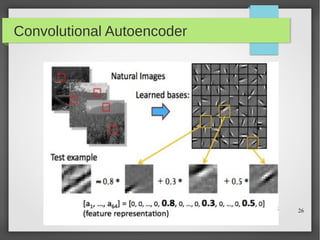

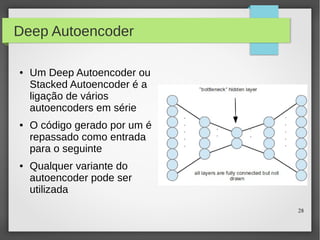


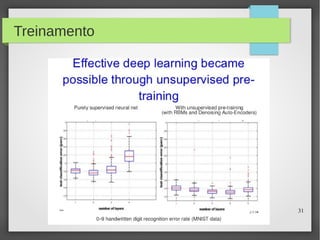


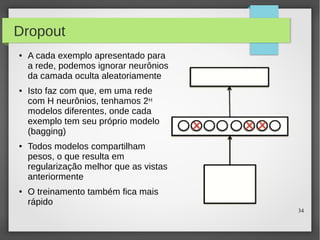





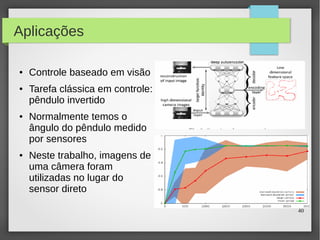
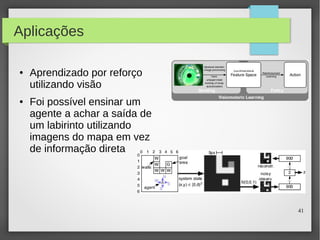



Este documento apresenta o roteiro para o exame de qualificação de doutorado de Rafael Coimbra Pinto sobre redes neurais. O documento discute a diferença entre inteligência artificial e inteligência computacional, apresenta vários tipos de redes neurais como perceptrons, autoencoders profundos e convolucionais, e discute aplicações como reconhecimento de imagens, fala e gestos.









































![[Jose Ahirton lopes] Do Big ao Better Data](https://cdn.slidesharecdn.com/ss_thumbnails/ahirtonlopesdobigaobetterdata-190410143141-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Jose Ahirton Lopes] Deep Learning - Uma Abordagem Visual](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesdeeplearning-umaabordagemvisual-181209205137-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Jose Ahirton Lopes] Deep Learning - Uma Abordagem Visual](https://cdn.slidesharecdn.com/ss_thumbnails/joseahirtonlopesdeeplearning-umaabordagemvisual-181204182142-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Ahirton Lopes e Rafael Arevalo] Deep Learning - Uma Abordagem Visual](https://cdn.slidesharecdn.com/ss_thumbnails/ahirtonlopeserafaelarevalodeeplearning-umaabordagemvisual-190215183628-thumbnail.jpg?width=640&height=640&fit=bounds)









