Baixado 11 vezes



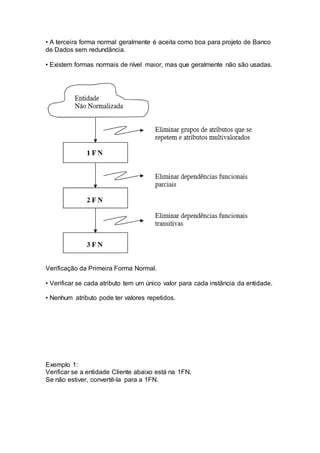
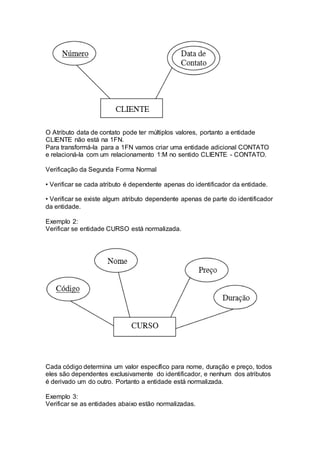
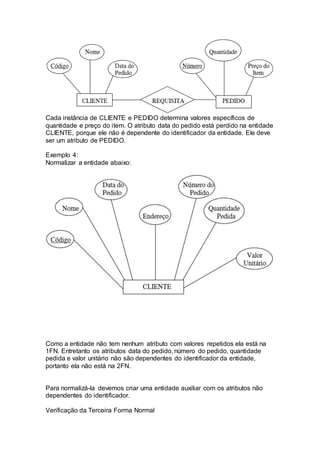



Normalização é um processo aplicado a tabelas de banco de dados para evitar redundâncias e inconsistências. Ele envolve seguir regras para colocar as tabelas na Primeira, Segunda e Terceira Forma Normal. Isso garantirá um banco de dados mais íntegro sem dados duplicados ou derivados. O documento explica essas formas normais e dá exemplos de como normalizar tabelas.






























![[Certificacao ] normalizacao de dados e as formas normais](https://cdn.slidesharecdn.com/ss_thumbnails/certificacao-normalizacaodedadoseasformasnormais-141126111503-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
















