Baixado 23 vezes
















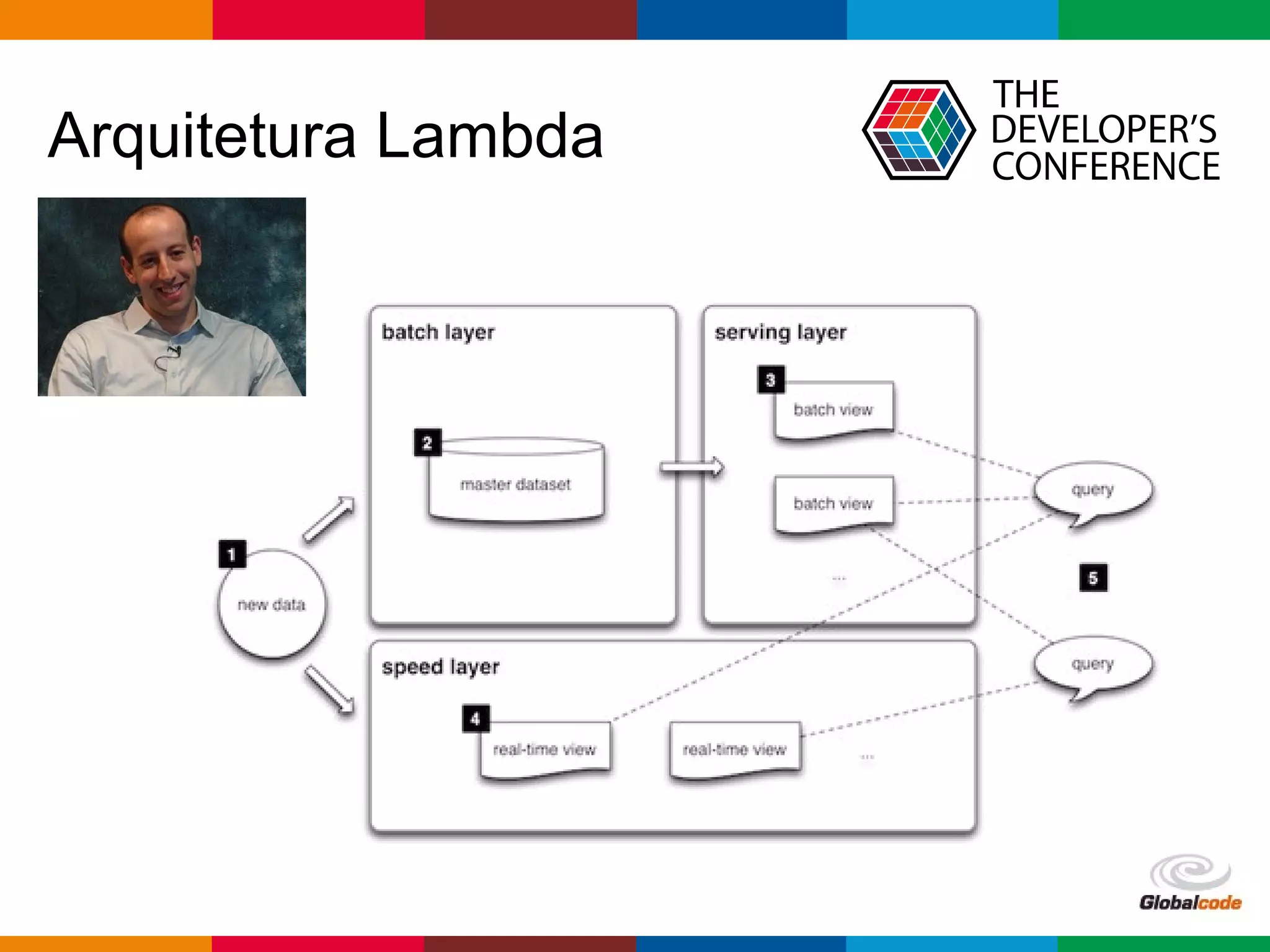

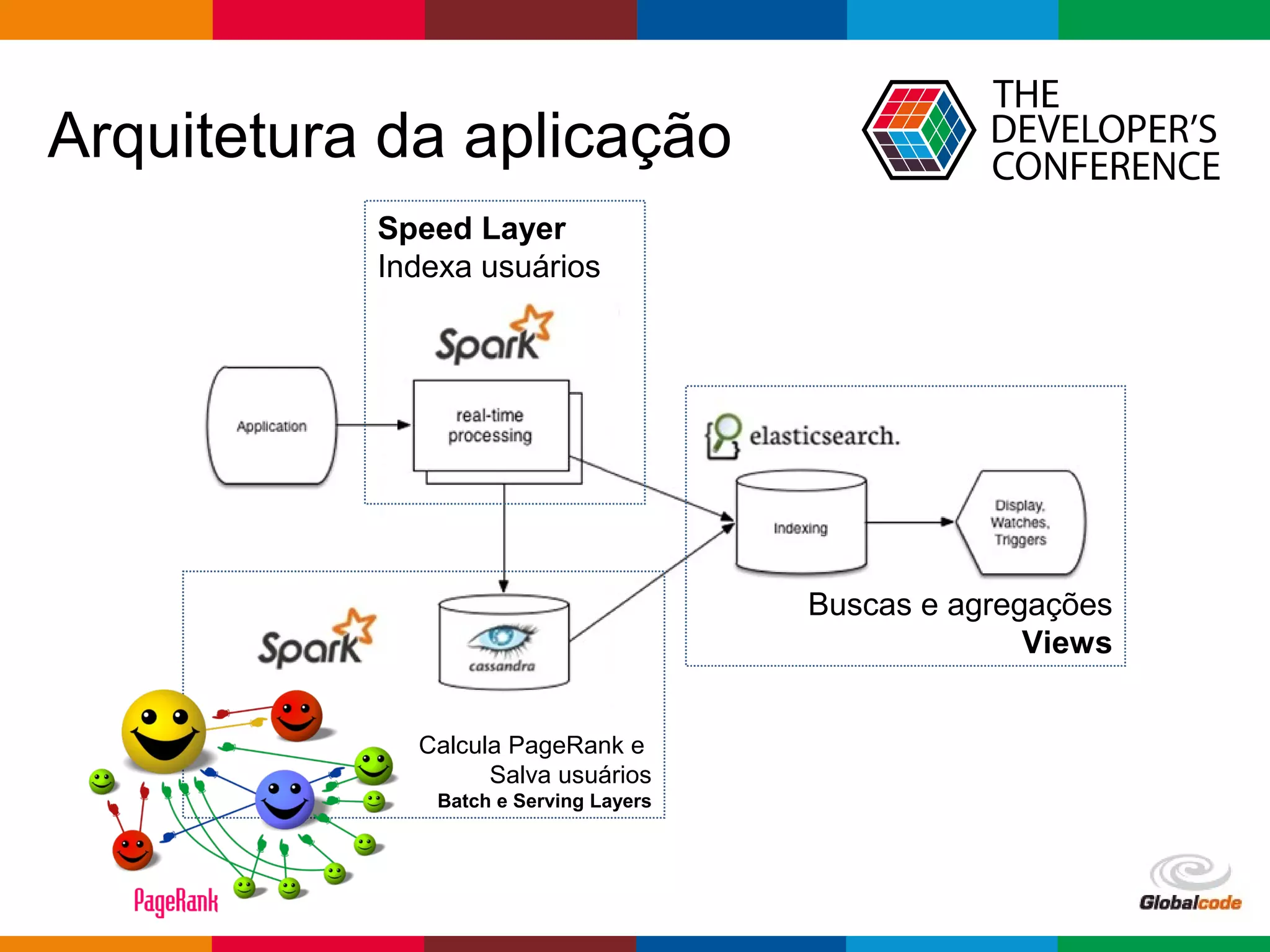




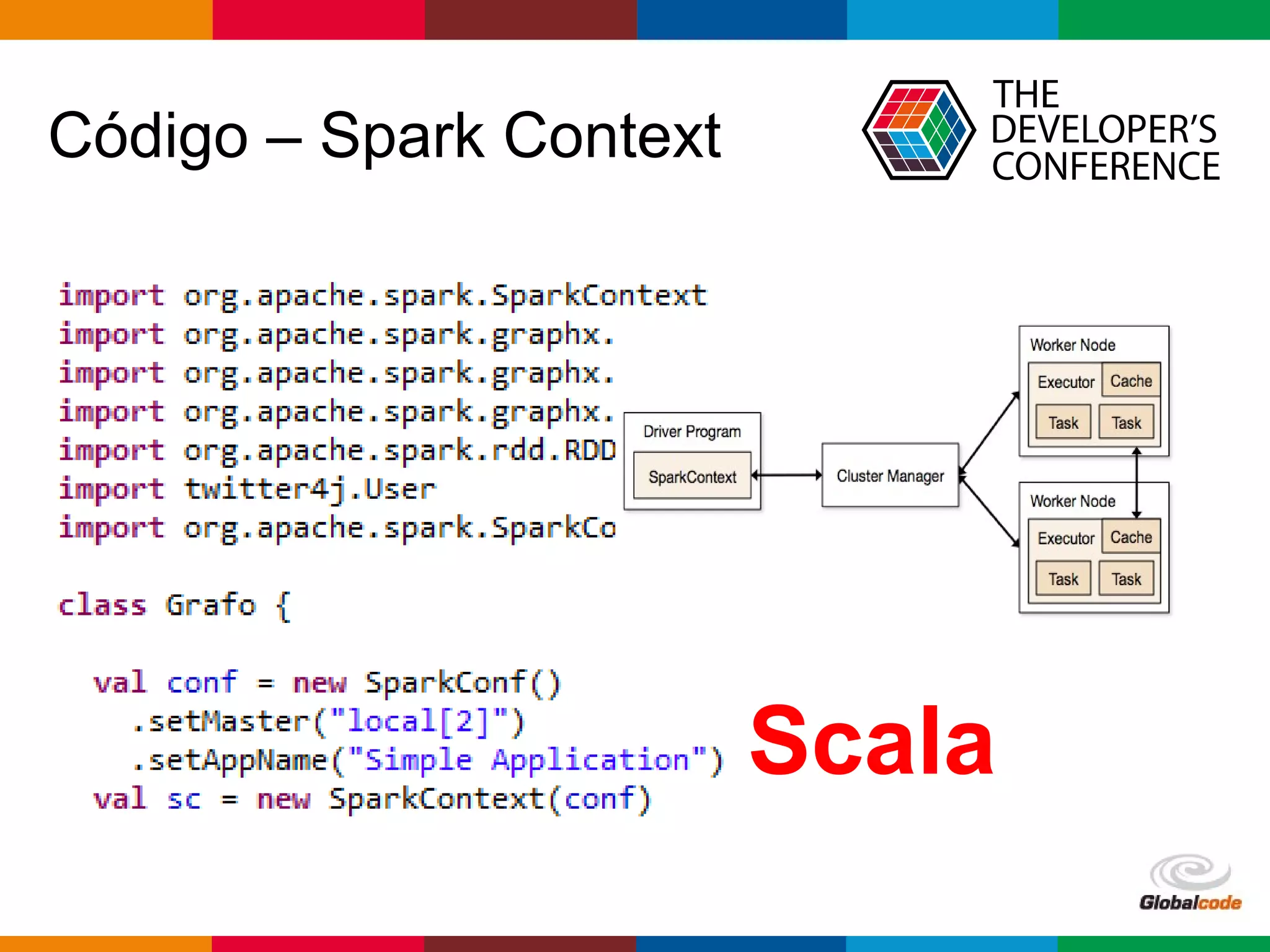



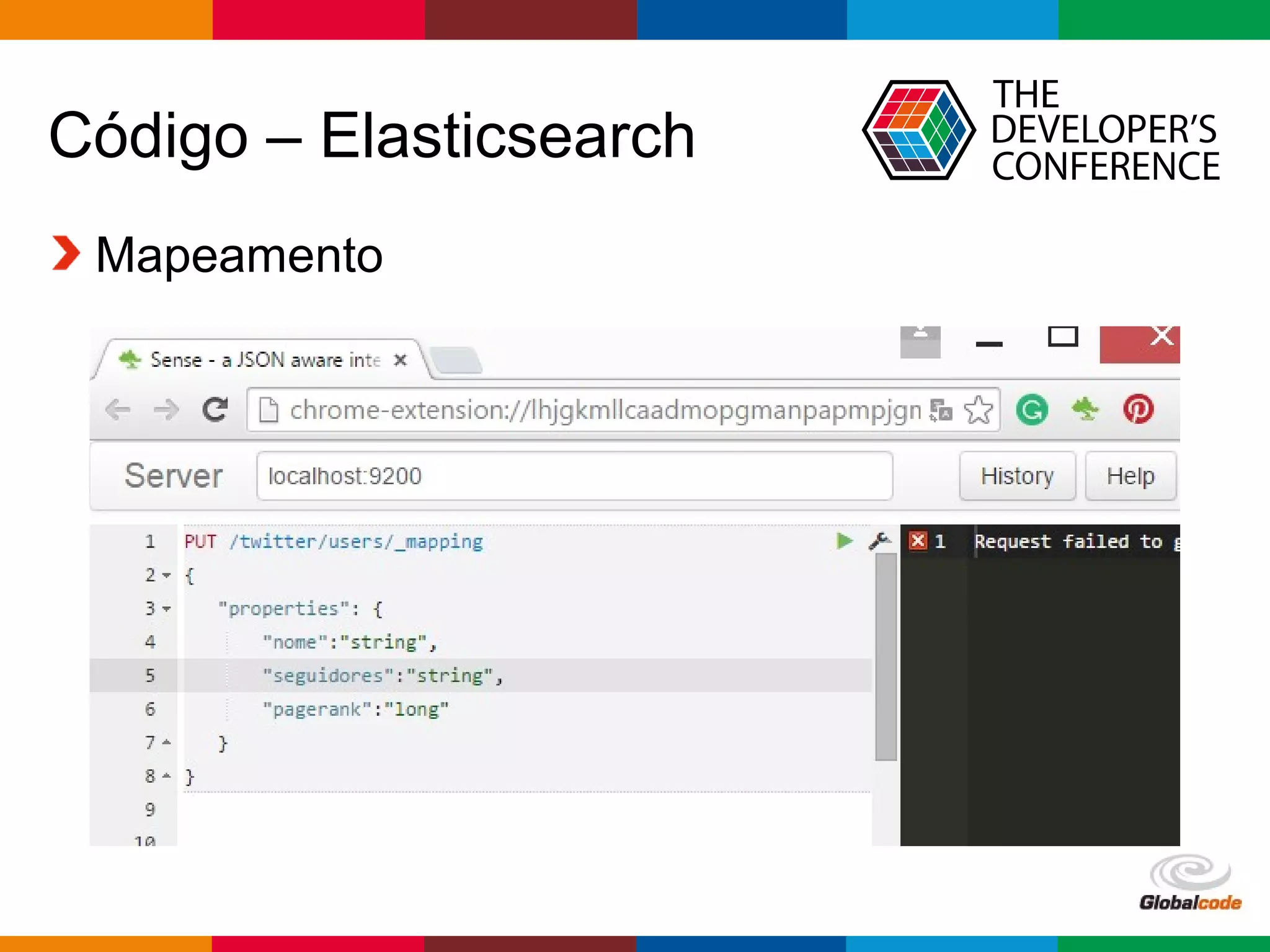
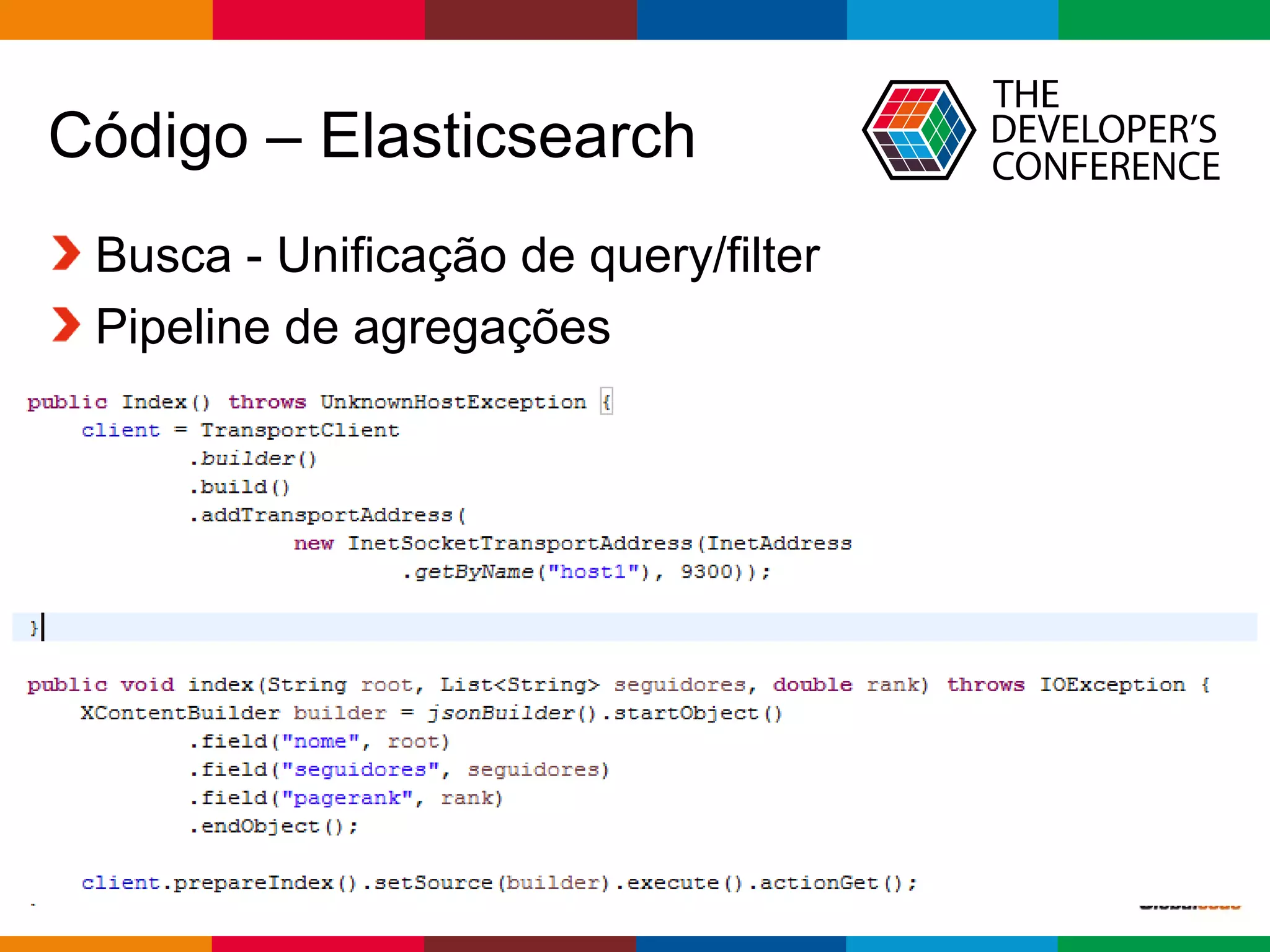

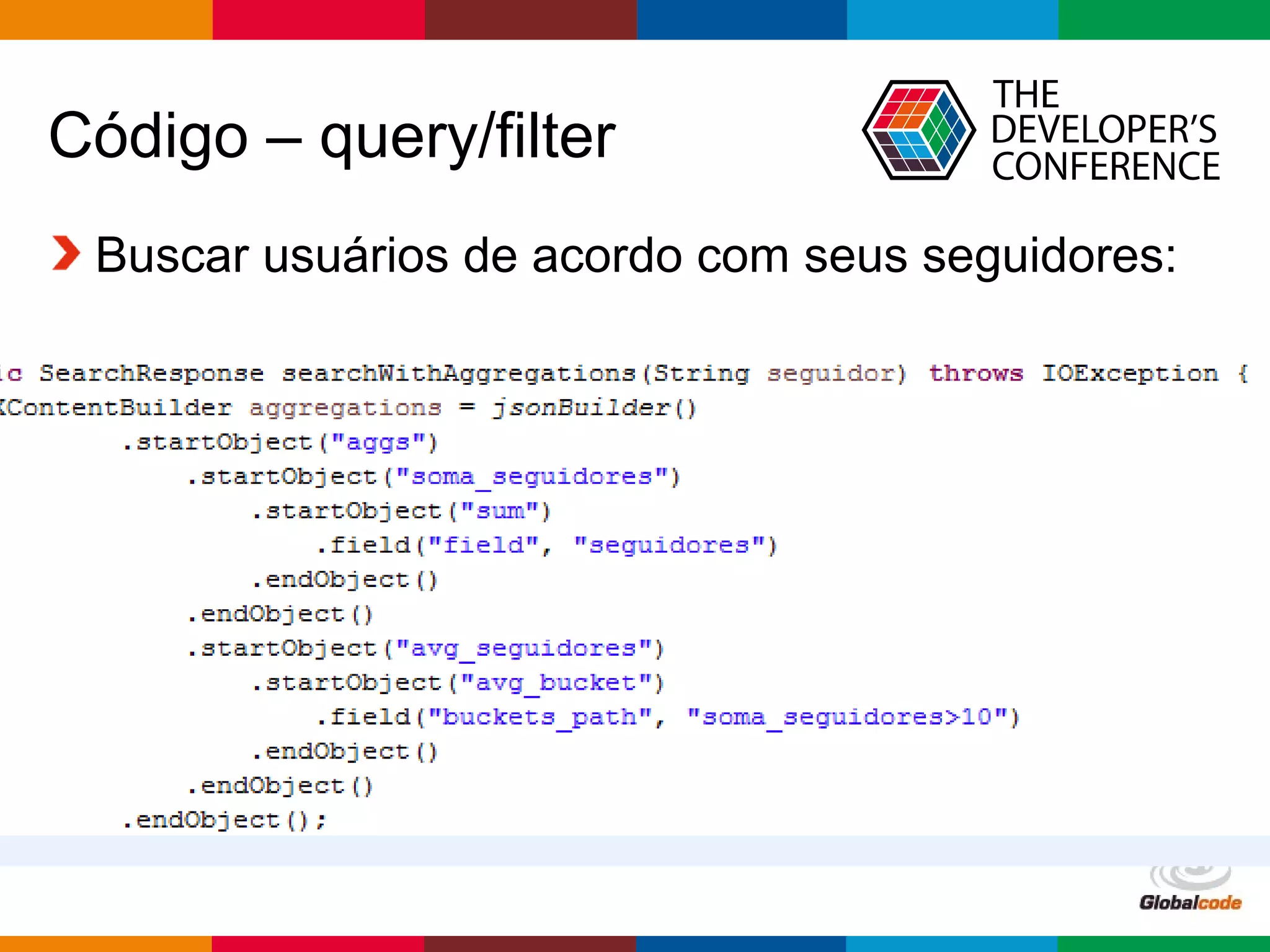

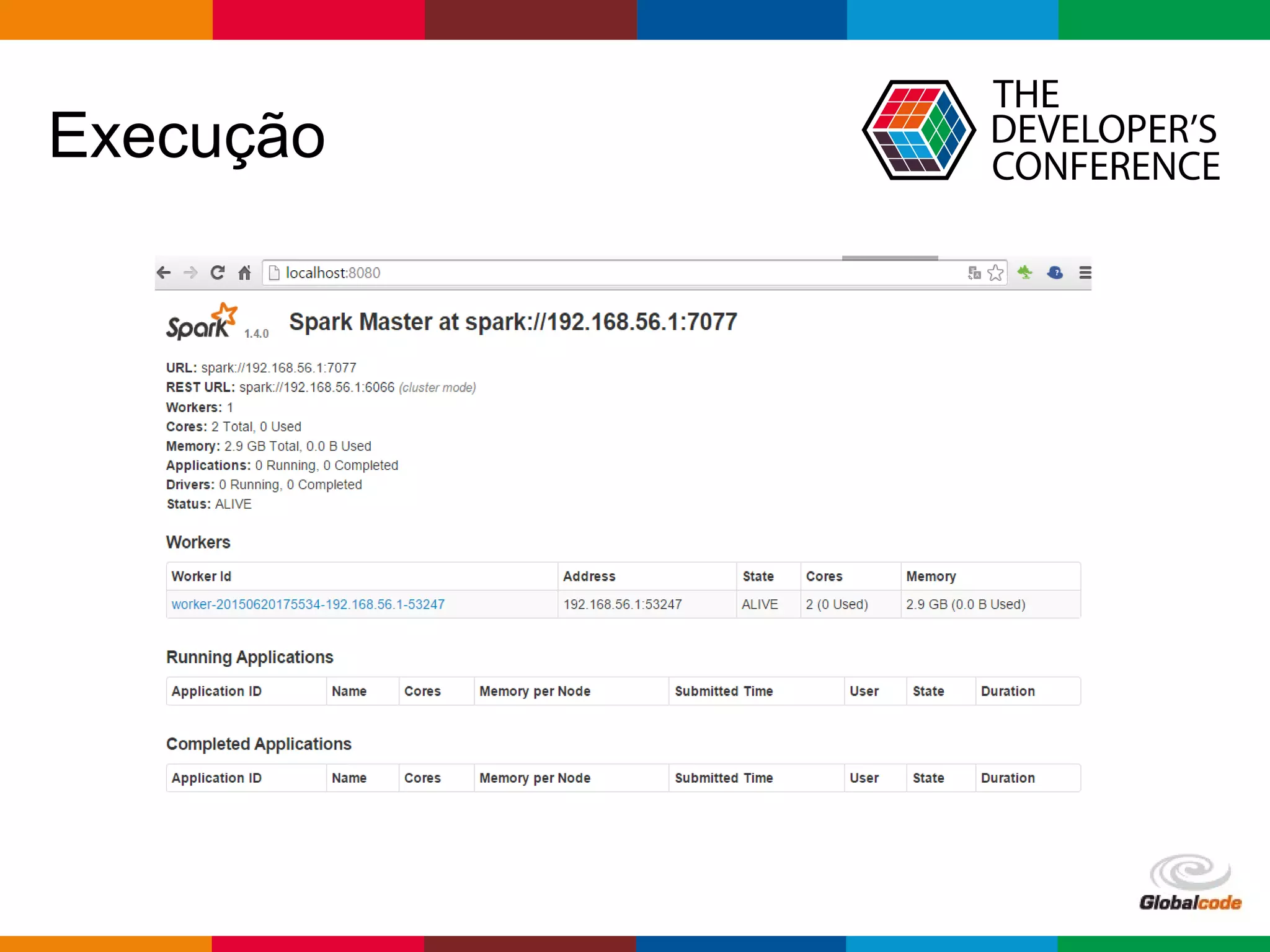







1. A apresentação discute o uso da arquitetura Lambda com GraphX e Elasticsearch 2.0 em uma aplicação de redes sociais. 2. É apresentado o histórico de MapReduce e Hadoop, seguido de uma visão geral do Spark e GraphX e do Elasticsearch 2.0. 3. A arquitetura proposta usa Spark para calcular o PageRank dos usuários a partir de um grafo de seguidores no Twitter e indexar os resultados no Elasticsearch.











































































