


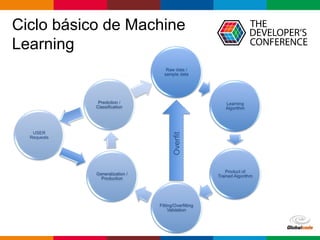
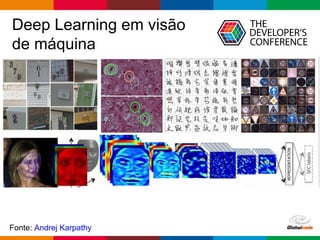

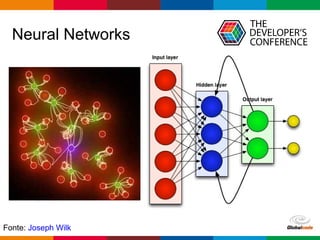

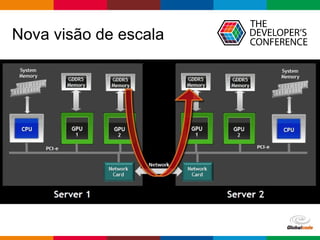


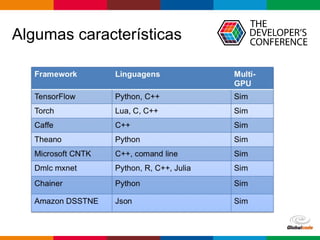
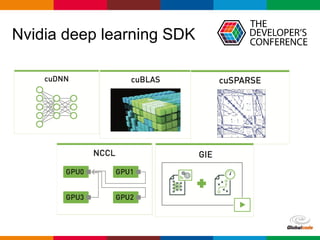




O documento discute conceitos de deep learning, incluindo ciclos de machine learning, visão computacional, processamento de linguagem natural, redes neurais e frameworks. Também aborda opções para escalar deep learning em nuvem ou localmente e as diferenças entre cientistas de dados e arquitetos de sistemas.







































