Baixado 52 vezes









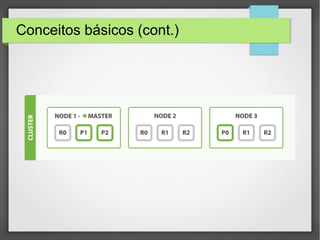



























Este documento apresenta os principais conceitos do Elasticsearch, incluindo sua arquitetura orientada a documentos, indexação, buscas, failover e escalabilidade. Demonstra também a instalação, interação via API e indexação de documentos no Elasticsearch.











![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)