Transferir como PDF, PPTX









![Instalação MongoBD no Ubuntu
● Importar chave pública
○ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv
2930ADAE8CAF5059EE73BB4B58712A2291FA4AD5
● Adicionar dependências
○ echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu
trusty/mongodb-org/3.6 multiverse" | sudo tee
/etc/apt/sources.list.d/mongodb-org-3.6.list
● Atualizar pacote de dados
○ sudo apt-get update
● Instale o Mongo
○ sudo apt-get install -y mongodb-org](https://image.slidesharecdn.com/nosqlenewsqlapresentao-180116181405/85/NoSql-e-NewSql-22-320.jpg)

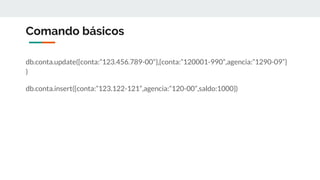

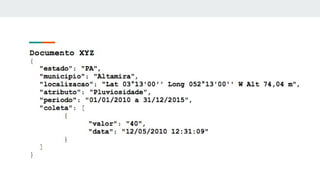
![Dado que o campo “cod” é uma referência única para este produto neste catálogo,
poderíamos transformá-lo em chave e salvar um hash com todas as propriedades
do produto, como mostra o código abaixo:
catalogo_xml.each do |product_xml|
# Uma vez que transformamos o xml do produto em um hash...
product = parser_to_hash(product_xml)
# Para cada identificador cod salvamos todas as
# informações deste produto
redis[:product].set(product[:cod], Marshal::dump(product))
end
end
Exemplo de código](https://image.slidesharecdn.com/nosqlenewsqlapresentao-180116181405/85/NoSql-e-NewSql-30-320.jpg)




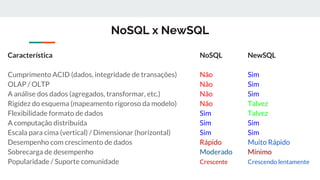


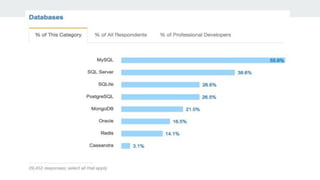
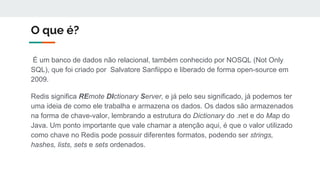
O documento discute as tecnologias NoSQL, NewSQL e Redis. NoSQL são bancos de dados não relacionais que oferecem alta escalabilidade horizontal e flexibilidade de esquema. NewSQL combina as vantagens de desempenho de NoSQL com as garantias ACID de bancos de dados tradicionais. Redis é um banco de dados chave-valor em memória usado para casos que requerem alta performance.



































































