Baixado 350 vezes



















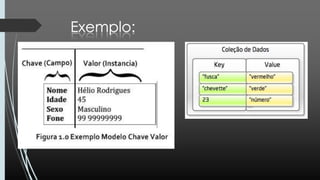





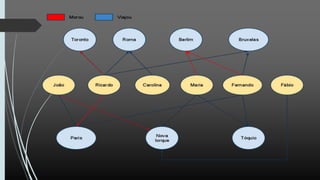







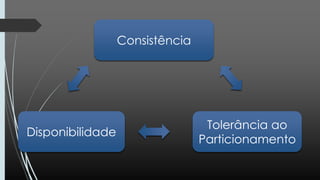




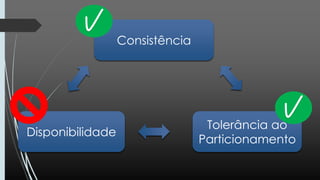

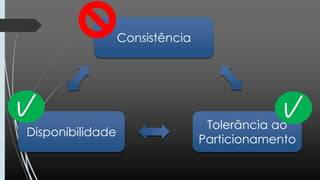





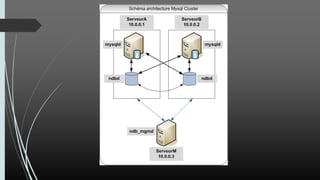





O documento discute NoSQL, comparando propriedades ACID e BASE e o teorema CAP. Apresenta vários modelos NoSQL como chave-valor, orientado a colunas, documentos e grafos. Explica como sistemas NoSQL priorizam disponibilidade sobre consistência de acordo com o teorema CAP.









![[PowerBI] Primeiros Passos](https://cdn.slidesharecdn.com/ss_thumbnails/powerbidesktopprimeirospassos-170729002609-thumbnail.jpg?width=640&height=640&fit=bounds)






















































































