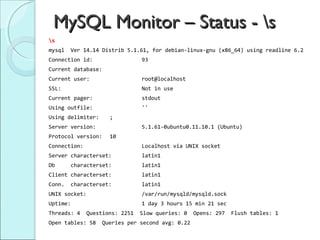
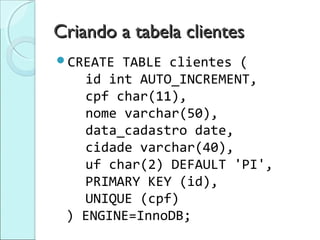
Este documento discute SQL e o uso de bancos de dados relacionais. Ele fornece uma introdução aos principais conceitos de SQL como DDL, DML, consultas, funções agregadas e operadores relacionais. Também apresenta exemplos de como criar e manipular tabelas, banco de dados e consultas em SQL.





![Criação de banco de dados
CREATE DATABASE nome_bd
[[DEFAULT] CHARACTER SET charset_name]
[[DEFAULT] COLLATE collation_name]
Character set – conjunto de símbolos e codificações.
Collation – conjunto de regras para comparação de
caracteres em um conjunto de caracteres.
Exemplos:
◦ CREATE DATABASE locadora;
◦ CREATE DATABASE locadora CHARSET utf8;
◦ CREATE DATABASE locadora DEFAULT CHARACTER
SET utf8 COLLATE utf8_general_ci;](https://image.slidesharecdn.com/bd-sql1-130408115954-phpapp02/85/Bd-sql-1-7-320.jpg)



![Criação de tabelas
CREATE TABLE nome-tabela
(nome-coluna tipo-de-dados [not null],
[nome-coluna tipo-de-dados [not null] … ],
[CONSTRAINT nome-restrição]
UNIQUE nome-coluna
| PRIMARY KEY(nome-coluna {, nome-coluna})
| FOREIGN KEY (nome-coluna {, nome-coluna})
REFERENCES nome-tabela
[ON DELETE CASCADE |
SET NULL | NO ACTION ],
[ON UPDATE CASCADE],
| CHECK (predicado)
)](https://image.slidesharecdn.com/bd-sql1-130408115954-phpapp02/85/Bd-sql-1-11-320.jpg)





![Remoção de tabelas
DROP TABLE nome-tabela [CASCADE |
RESTRICT]
Remove as tuplas da tabela e sua
definição do catálogo
◦ CASCADE remove as restrições do tipo
foreign key tabelas que referenciam a tabela
removida](https://image.slidesharecdn.com/bd-sql1-130408115954-phpapp02/85/Bd-sql-1-17-320.jpg)



![Alteração de tabelas
ALTER TABLE nome-tabela
[ADD nome-coluna tipo de dados]
[DROP nome-coluna ]
[ADD CONSTRAINT nome-restrição]
[DROP CONSTRAINT nome-restrição]
[DROP PRIMARY KEY]
[ repetir ADD ou DROP em qualquer ordem]](https://image.slidesharecdn.com/bd-sql1-130408115954-phpapp02/85/Bd-sql-1-22-320.jpg)
![Consultas
SELECT [ALL | DISTINCT] {* | expr [[AS] c_alias]
{, expr [[AS] c_alias] … }}
FROM nome-tabela [[AS] qualificador]
{, nome-tabela [[AS] qualificador] …}
WHERE predicado
ALL
◦ Retorna todas as tuplas, inclusive repetidas (default)
DISTINCT
◦ Retorna apenas tuplas não repetidas
*
◦ Retorna todos os atributos da(s) tabela(s)
expr
◦ Representa um atributo ou
◦ Expressão matemática envolvendo atributos das tabelas
salario*1.40](https://image.slidesharecdn.com/bd-sql1-130408115954-phpapp02/85/Bd-sql-1-23-320.jpg)
![Consultas
FROM
◦ Representa o produto cartesiano das tabelas
referenciadas
WHERE
◦ Corresponde ao predicado de seleção da álgebra
relacional
ORDER BY coluna-resultado [ASC | DESC]
{, coluna-resultado [ASC | DESC] …}](https://image.slidesharecdn.com/bd-sql1-130408115954-phpapp02/85/Bd-sql-1-24-320.jpg)








































































