Baixado 88 vezes












![18AULA :
Campus
Charqueadas
Características dos Pipelines de
instrução
• O tempo gasto no processamento de M
instruções em um pipeline com K estágios e
ciclo de máquina igual a t é dado por:
T = [K + (M – 1)] * t
• Se M >> K (caso comum), T é
aproximadamente M * t](https://image.slidesharecdn.com/aula3-apd-150512003149-lva1-app6891/85/Arquiteturas-Paralelas-e-Distribuidas-Aula-3-Pipeline-18-320.jpg)












![33AULA :
Campus
Charqueadas
Escalonamento de instruções
• Exemplo:
X = Y - W
Z = K + L
• Código gerado:
ld R1, mem[Y]
ld R2, mem[W]
sub R3, R1, R2 è Situação de interlock
sd R3, mem[X] è Situação de interlock
ld R4, mem[K]
ld R5, mem[L]
add R6, R4, R5 è Situação de interlock
sd R6, mem[Z] è Situação de interlock](https://image.slidesharecdn.com/aula3-apd-150512003149-lva1-app6891/85/Arquiteturas-Paralelas-e-Distribuidas-Aula-3-Pipeline-33-320.jpg)
![34AULA :
Campus
Charqueadas
Escalonamento de instruções
• Código executado com nops inseridos pelo interlock:
ld R1, mem[Y]
ld R2, mem[W]
nop
nop
sub R3, R1, R2 è Situação de interlock
nop
nop
sd R3, mem[X] è Situação de interlock
ld R4, mem[K]
ld R5, mem[L]
nop
nop
add R6, R4, R5 è Situação de interlock
nop
nop
sd R6, mem[Z] è Situação de interlock](https://image.slidesharecdn.com/aula3-apd-150512003149-lva1-app6891/85/Arquiteturas-Paralelas-e-Distribuidas-Aula-3-Pipeline-34-320.jpg)
![35AULA :
Campus
Charqueadas
Escalonamento de instruções
• Código otimizado:
ld R1, mem[Y]
ld R2, mem[W]
ld R4, mem[K]
sub R3, R1, R2
ld R5, mem[L]
sd R3, mem[X]
add R6, R4, R5
sd R6, mem[Z]](https://image.slidesharecdn.com/aula3-apd-150512003149-lva1-app6891/85/Arquiteturas-Paralelas-e-Distribuidas-Aula-3-Pipeline-35-320.jpg)
![36AULA :
Campus
Charqueadas
Escalonamento de instruções
• Código executado com nops inseridos pelo interlock:
ld R1, mem[Y]
ld R2, mem[W]
ld R4, mem[K]
nop
sub R3, R1, R2 è Situação de interlock
ld R5, mem[L]
sd R3, mem[X]
nop
add R6, R4, R5 è Situação de interlock
nop
nop
sd R6, mem[Z] è Situação de interlock](https://image.slidesharecdn.com/aula3-apd-150512003149-lva1-app6891/85/Arquiteturas-Paralelas-e-Distribuidas-Aula-3-Pipeline-36-320.jpg)

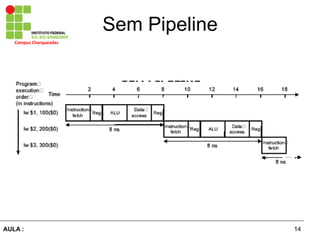
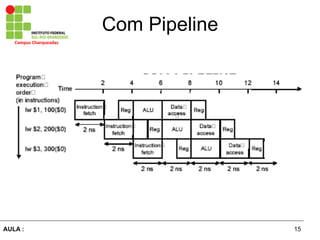
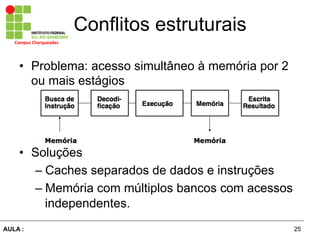
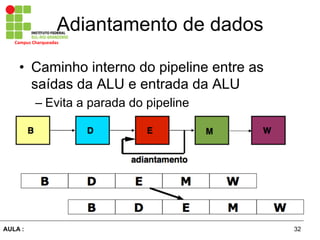
O documento discute o conceito de pipeline no processamento de instruções, onde a execução de cada instrução é dividida em vários estágios executados em paralelo. Isso permite aumentar a taxa de instruções processadas ao mesmo tempo, porém cada instrução leva o mesmo tempo para ser concluída. Dependências entre instruções podem causar atrasos no pipeline e técnicas como adiantamento de dados e escalonamento de instruções são usadas para resolver esses problemas.

















































































