Baixado 43 vezes




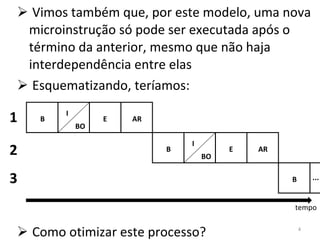



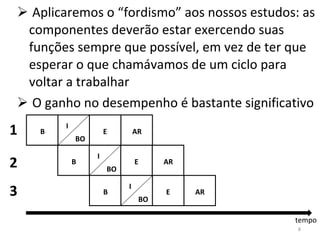



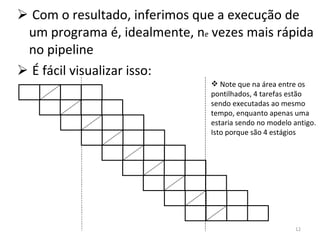

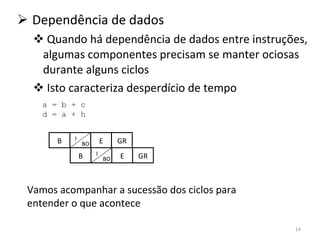

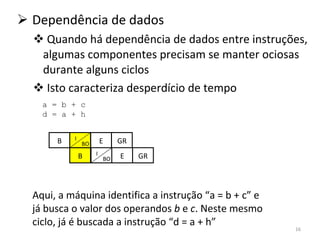
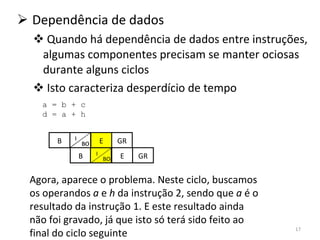
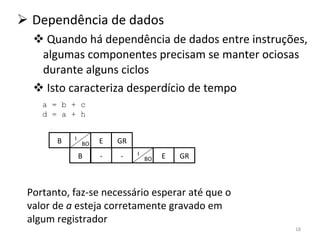


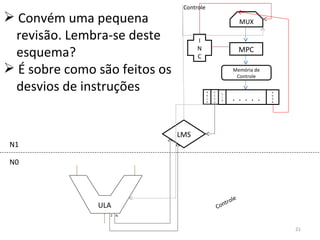









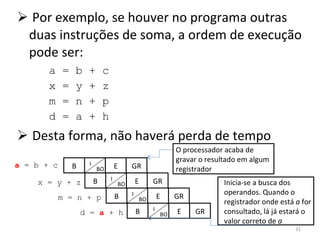
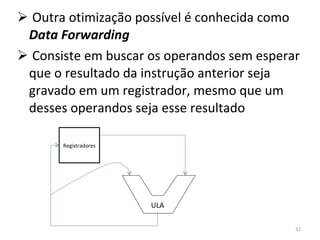

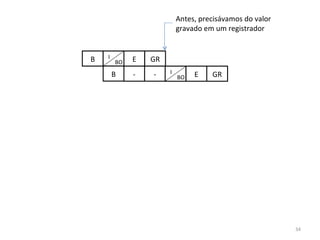
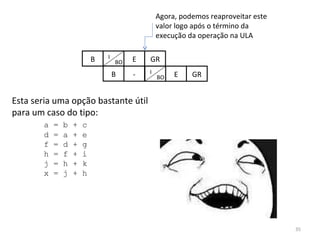


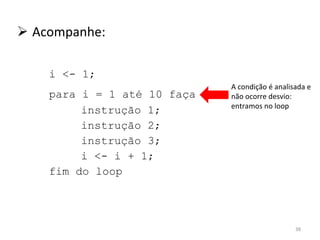
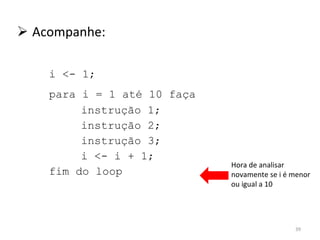
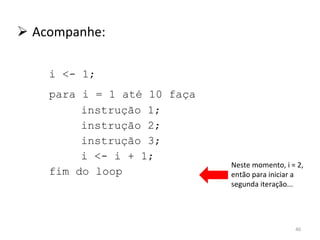
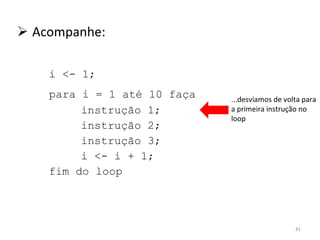




O documento discute como o modelo de pipeline pode melhorar o desempenho de um processador ao executar instruções de forma sobreposta em estágios. No entanto, dependências de dados e controle entre instruções podem causar atrasos. Otimizações como reorder de instruções, data forwarding e previsão de desvios ajudam a reduzir esses atrasos.

































































