Path to the future #5 - Melhores práticas de data warehouse no Amazon Redshift
Este documento fornece diretrizes sobre melhores práticas para armazenamento e análise de dados no Amazon Redshift, incluindo arquitetura, ingestão de dados, recursos, dicas de migração e otimização.
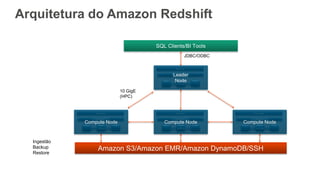
Arquitetura do Redshfit
Ingestão
•COPY
• Primary keys e
arquivos de Manifesto
• Higienização de Dados
• Novas features para
ingestão
• Restore para Tabelas
• Auto
Compressão/Compres
são por sort key
Features
• Novas Funções
• UDFs
• Interleaved sort keys
Dicas de Migração
Otimização de Ambientes
• Cargas de trabalho
• WLM
• Console
O que esperar desta Sessão
3.
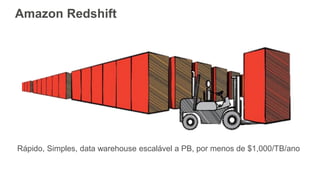
Rápido, Simples, datawarehouse escalável a PB, por menos de $1,000/TB/ano
Amazon Redshift
4.
Amazon Redshift entregaPerformance
“[Amazon] Redshift is twenty times faster than Hive.” (5x–20x reduction in query times) link
“Queries that used to take hours came back in seconds. Our analysts are orders of magnitude
more productive.” (20x–40x reduction in query times) link
“…[Amazon Redshift] performance has blown away everyone here (we generally see 50–
100x speedup over Hive).” link
“Team played with [Amazon] Redshift today and concluded it is ****** awesome. Un-indexed
complex queries returning in < 10s.”
“Did I mention it's ridiculously fast? We'll be using it immediately to provide our analysts
an alternative to Hadoop.”
“We saw… 2x improvement in query times.”
Channel “We regularly process multibillion row datasets and we do that in a matter of hours.” link
Uso de váriosarquivos para maximizar a carga
Comando COPY
Cada ”slice” carrega um arquivo
por vez
Um arquivo único significa
apenas um ”slice” carregando
dados
Ao invés de 100 MB/sec,
você obtém somente 6.25
MB/sec
9.
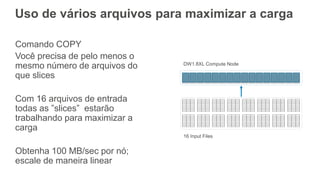
Uso de váriosarquivos para maximizar a carga
Comando COPY
Você precisa de pelo menos o
mesmo número de arquivos do
que slices
Com 16 arquivos de entrada
todas as ”slices” estarão
trabalhando para maximizar a
carga
Obtenha 100 MB/sec por nó;
escale de maneira linear
10.
”Primary keys” earquivos de manifesto
Amazon Redshift não força a limitação da primary key
• Se carregar várias vezes o mesmo dado o Redshift não vai acusar
erro;
• Se declarar primary keys para DML, o otimizador vai entender que
os registros são únicos;
Use arquivos de manifesto para controlar exatamente o que é
carregado e o que fazer em caso de falta de arquivos
• Defina um manifesto JSON no Amazon S3;
• Assegura que o cluster carregue exatamente o que quer;
11.
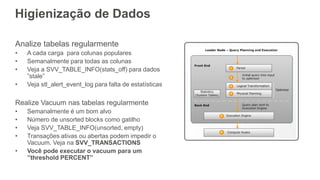
Higienização de Dados
Analizetabelas regularmente
• A cada carga para colunas populares
• Semanalmente para todas as colunas
• Veja a SVV_TABLE_INFO(stats_off) para dados
”stale”
• Veja stl_alert_event_log para falta de estatísticas
Realize Vacuum nas tabelas regularmente
• Semanalmente é um bom alvo
• Número de unsorted blocks como gatilho
• Veja SVV_TABLE_INFO(unsorted, empty)
• Transações ativas ou abertas podem impedir o
Vacuum. Veja na SVV_TRANSACTIONS
• Você pode executar o vacuum para um
”threshold PERCENT”
12.
Novas Features –Ingestão
Opção de Backup no CREATE TABLE
• Para uso em Staging e carga de dados
• Tabela será excluída em um restore
Extensão de ”Sorted” Automatic COPY/INSERT
• Tabela é 100% ordenada e possui apenas uma sortkey (ex. date ou timtestamp)
• Você adiciona linhas na tabela toda (sempre após as existentes, distribuídas por
sortkey)
Alter Table Append
• Adiciona linhas em uma tabela movendo dados de uma tabela source existente
• Dados em uma tabela de origem são movimentados combinando com os dados na
destino.
• Não pode rodar ALTER TABLE APPEND dentro de um bloco de transações (BEGIN
... END)
13.
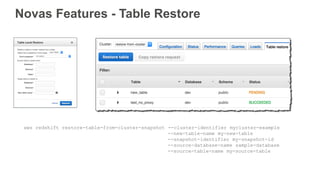
Novas Features -Table Restore
aws redshift restore-table-from-cluster-snapshot --cluster-identifier mycluster-example
--new-table-name my-new-table
--snapshot-identifier my-snapshot-id
--source-database-name sample-database
--source-table-name my-source-table
14.
Compressão automática (quasesempre positiva)
Melhor performance e diminui custo
Amostra de dados quando executado um comando COPY em tabela
vazia
• Amostra de até 100,000 rows e escolhe o melhor Encoding
Processo de ETL regular utilizando tabelas de staging ou temporárias:
Desligue a compressão automática
• Use análise de compressão para determinar o encoding correto
• Prepare seus DML (baked) com os encodings corretos
15.
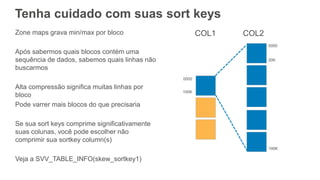
Tenha cuidado comsuas sort keys
Zone maps grava min/max por bloco
Após sabermos quais blocos contém uma
sequência de dados, sabemos quais linhas não
buscarmos
Alta compressão significa muitas linhas por
bloco
Pode varrer mais blocos do que precisaria
Se sua sort keys comprime significativamente
suas colunas, você pode escolher não
comprimir sua sortkey column(s)
Veja a SVV_TABLE_INFO(skew_sortkey1)
COL1 COL2
16.
Mantenha as colunastão estreitas quanto
possível
• Buffers são alocados baseado na
declaração da largura das colunas;
• Colunas mais largas sem necessidade
desperdiçam memória;
• Menos linhas cabem na memória mais
probabilidade de gravação em disco
• Veja a
SVV_TABLE_INFO(max_varchar)
Novas funções SQL
Nósadicionamos funções SQL regularmente para aumentar a capacidade de
execução de queries no Amazon Redshift
Adicionadas 25+ funções:
• LISTAGG
• [APPROXIMATE] COUNT
• DROP IF EXISTS, CREATE IF NOT EXISTS
• REGEXP_SUBSTR, _COUNT, _INSTR, _REPLACE
• PERCENTILE_CONT, _DISC, MEDIAN
• PERCENT_RANK, RATIO_TO_REPORT
Continuaremos realizado mas também queremos habilitar que escreva as suas
19.
Funções definidas pelousuário (UDFs)
Pode escrever UDFs usando Python 2.7
• Sintaxe idêntica a do PostgreSQL UDF
• Chamadas de sistema e rede UDFs não são permitidas
Vem com Pandas, NumPy, e SciPy pre-instalados
• Você pode importar sua biblioteca para funções mais
complexas
20.
Exemplo de UDF
CREATEFUNCTION f_hostname (VARCHAR url)
RETURNS varchar
IMMUTABLE AS $$
import urlparse
return urlparse.urlparse(url).hostname
$$ LANGUAGE plpythonu;
1-click deployment tolaunch, on
multiple regions around the world
Pay-as-you-go pricing with no long
term contracts required
Advanced Analytics Business IntelligenceData Integration
Chaves de ordenaçãocompostas ( Compound sort keys )
Registros são armazenados
em blocos no Amazon
Redshift
Nesta ilustração assumimos
que 4 registros preenchem
um bloco
Registros para um dado
cust_id ficam em um bloco
Contudo, registros para um
dado prod_id ficam
espalhados em vários
blocos
1
1
1
1
2
3
4
1
4
4
4
2
3
4
4
1
3
3
3
2
3
4
3
1
2
2
2
2
3
4
2
1
1 [1,1] [1,2] [1,3] [1,4]
2 [2,1] [2,2] [2,3] [2,4]
3 [3,1] [3,2] [3,3] [3,4]
4 [4,1] [4,2] [4,3] [4,4]
1 2 3 4
prod_id
cust_id
cust_id prod_id other columns blocks
Select sum(amt)
From big_tab
Where cust_id = (1234);
Select sum(amt)
From big_tab
Where prod_id = (5678);
25.
1 [1,1] [1,2][1,3] [1,4]
2 [2,1] [2,2] [2,3] [2,4]
3 [3,1] [3,2] [3,3] [3,4]
4 [4,1] [4,2] [4,3] [4,4]
1 2 3 4
prod_id
cust_id
Chaves de ordenação intercaladas (Interleaved sort keys)
Registros para um dado
cust_id espalhados em
2 blocos
Registros para um dado
prod_id separados em 2
blocos
Dados são distribuidos
com pesos iguais para
ambos
1
1
2
2
2
1
2
3
3
4
4
4
3
4
3
1
3
4
4
2
1
2
3
3
1
2
2
4
3
4
1
1
cust_id prod_id other columns blocks
26.
Uso
Nova palavra chaveINTERLEAVED para Sortkeys
• Sintaxe anterior continua funcionando
• Pode escolher até 8 colunas para incluir e selecionar por qualquer uma
Não precisa mudar as queries
Só estamos iniciando
• Benefícios significantes; Carga pode ser penalizada
• Veja a SVV_INTERLEAVED_COLUMNS(interleaved_skew) para decidir sobre VACUUM REINDEX
• Um valor maior que 5 indica necessidade de VACUUM REINDEX
[[ COMPOUND | INTERLEAVED ] SORTKEY ( column_name [, ...] ) ]
Responda
Por que vocêfaz isto hoje?
• Muitas vezes, usuários nem sabem
Qual a necessidade de negócio?
• Muitas vezes, não tem relação com o que faz na prática
• Talvez você se beneficie de outro serviço AWS
30.
No Amazon Redshift
Updatessão delete + insert da linha
• Deletes marcam para deleção
Blocos são imutáveis
• Espaço mínimo usado é um bloco por coluna, por slice
Commits são custosos
• 4 GB write na 8XL por nó
• Espelha o dicionário INTEIRO
• Serializado pelo tamanho do cluster
31.
No Amazon Redshift
•Nem todas as agregações são criadas da mesma forma
• Pre-agregação pode ajudar
• Ordenação no grupo importa
• Concorrência deve ser baixa para maior throughput
• Camada de Cache para dashboards é recomendada
• WLM separa RAM para queries. Use múltiplos controles
para melhor performance.
32.
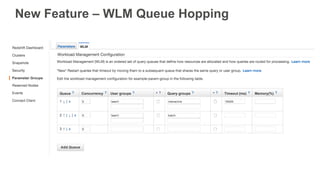
Workload Management (WLM)
Concorrênciae memória podem agora ser alteradas dinamicamente
Você pode ter valores distintos para tempo de leitura e tempo de carga
Use wlm_apex_hourly.sql para monitorar a pressão das filas
Obter meta-dados deresultados
Usando SQL ou JDBC, você pode obter os nomes das
colunas
ResultSet rs = stmt.executeQuery("SELECT * FROM emp");
ResultSetMetaData rsmd = rs.getMetaData();
String name = rsmd.getColumnName(1);
Descarga de Dados Por enquanto não provê metadados
• Use SELECT top 0…
• Ao invés de adicionar0=1 na sua cláusula WHERE
35.
Ferramentas Open-source
https://github.com/awslabs/amazon-redshift-utils
Admin scripts
•Diagnóstico do cluster
Admin views
• Gerenciamento e geração de DDLs.
Column encoding utility
• Permite selecionar o melhor encoding
Analyze and vacuum utility
• Automatiza VACUUM e operações de ANALYZE
Unload and copy utility
• Ajuda a migrar entre Amazon Redshift e outros bancos de dados



![Amazon Redshift entrega Performance
“[Amazon] Redshift is twenty times faster than Hive.” (5x–20x reduction in query times) link
“Queries that used to take hours came back in seconds. Our analysts are orders of magnitude
more productive.” (20x–40x reduction in query times) link
“…[Amazon Redshift] performance has blown away everyone here (we generally see 50–
100x speedup over Hive).” link
“Team played with [Amazon] Redshift today and concluded it is ****** awesome. Un-indexed
complex queries returning in < 10s.”
“Did I mention it's ridiculously fast? We'll be using it immediately to provide our analysts
an alternative to Hadoop.”
“We saw… 2x improvement in query times.”
Channel “We regularly process multibillion row datasets and we do that in a matter of hours.” link](https://image.slidesharecdn.com/pathtothefuture5-melhoresprticasdedatawarehousenoamazonredshift-160927124405/85/Path-to-the-future-5-Melhores-praticas-de-data-warehouse-no-Amazon-Redshift-4-320.jpg)







![Novas funções SQL
Nós adicionamos funções SQL regularmente para aumentar a capacidade de
execução de queries no Amazon Redshift
Adicionadas 25+ funções:
• LISTAGG
• [APPROXIMATE] COUNT
• DROP IF EXISTS, CREATE IF NOT EXISTS
• REGEXP_SUBSTR, _COUNT, _INSTR, _REPLACE
• PERCENTILE_CONT, _DISC, MEDIAN
• PERCENT_RANK, RATIO_TO_REPORT
Continuaremos realizado mas também queremos habilitar que escreva as suas](https://image.slidesharecdn.com/pathtothefuture5-melhoresprticasdedatawarehousenoamazonredshift-160927124405/85/Path-to-the-future-5-Melhores-praticas-de-data-warehouse-no-Amazon-Redshift-18-320.jpg)





![Chaves de ordenação compostas ( Compound sort keys )
Registros são armazenados
em blocos no Amazon
Redshift
Nesta ilustração assumimos
que 4 registros preenchem
um bloco
Registros para um dado
cust_id ficam em um bloco
Contudo, registros para um
dado prod_id ficam
espalhados em vários
blocos
1
1
1
1
2
3
4
1
4
4
4
2
3
4
4
1
3
3
3
2
3
4
3
1
2
2
2
2
3
4
2
1
1 [1,1] [1,2] [1,3] [1,4]
2 [2,1] [2,2] [2,3] [2,4]
3 [3,1] [3,2] [3,3] [3,4]
4 [4,1] [4,2] [4,3] [4,4]
1 2 3 4
prod_id
cust_id
cust_id prod_id other columns blocks
Select sum(amt)
From big_tab
Where cust_id = (1234);
Select sum(amt)
From big_tab
Where prod_id = (5678);](https://image.slidesharecdn.com/pathtothefuture5-melhoresprticasdedatawarehousenoamazonredshift-160927124405/85/Path-to-the-future-5-Melhores-praticas-de-data-warehouse-no-Amazon-Redshift-24-320.jpg)
![1 [1,1] [1,2] [1,3] [1,4]
2 [2,1] [2,2] [2,3] [2,4]
3 [3,1] [3,2] [3,3] [3,4]
4 [4,1] [4,2] [4,3] [4,4]
1 2 3 4
prod_id
cust_id
Chaves de ordenação intercaladas (Interleaved sort keys)
Registros para um dado
cust_id espalhados em
2 blocos
Registros para um dado
prod_id separados em 2
blocos
Dados são distribuidos
com pesos iguais para
ambos
1
1
2
2
2
1
2
3
3
4
4
4
3
4
3
1
3
4
4
2
1
2
3
3
1
2
2
4
3
4
1
1
cust_id prod_id other columns blocks](https://image.slidesharecdn.com/pathtothefuture5-melhoresprticasdedatawarehousenoamazonredshift-160927124405/85/Path-to-the-future-5-Melhores-praticas-de-data-warehouse-no-Amazon-Redshift-25-320.jpg)
![Uso
Nova palavra chave INTERLEAVED para Sortkeys
• Sintaxe anterior continua funcionando
• Pode escolher até 8 colunas para incluir e selecionar por qualquer uma
Não precisa mudar as queries
Só estamos iniciando
• Benefícios significantes; Carga pode ser penalizada
• Veja a SVV_INTERLEAVED_COLUMNS(interleaved_skew) para decidir sobre VACUUM REINDEX
• Um valor maior que 5 indica necessidade de VACUUM REINDEX
[[ COMPOUND | INTERLEAVED ] SORTKEY ( column_name [, ...] ) ]](https://image.slidesharecdn.com/pathtothefuture5-melhoresprticasdedatawarehousenoamazonredshift-160927124405/85/Path-to-the-future-5-Melhores-praticas-de-data-warehouse-no-Amazon-Redshift-26-320.jpg)