Baixado 26 vezes












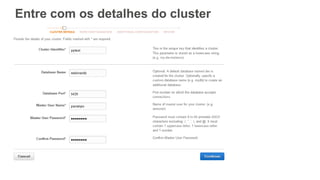



![Single Column
• Table is sorted by 1 column
Date Region Country
2-JUN-2015 Oceania New Zealand
2-JUN-2015 Asia Singapore
2-JUN-2015 Africa Zaire
2-JUN-2015 Asia Hong Kong
3-JUN-2015 Europe Germany
3-JUN-2015 Asia Korea
[ SORTKEY ( date ) ]
• Melhor para:
• Queries que usam a primeira coluna (i.e. date) como filtro
primário
• Pode acelerar joins e group bys
• Mais rápida para o VACUUM](https://image.slidesharecdn.com/datawarehousenanuvemdaaws-redshift-20160531-v2-160531221225/85/Webinar-Data-warehouse-na-nuvem-da-AWS-32-320.jpg)
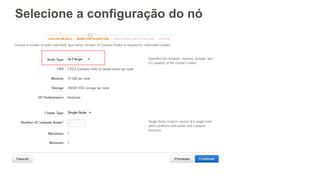
![Compound
• Tabela é ordenada pela primeira coluna, depois pela
segunda coluna e assim por diante.
Date Region Country
2-JUN-2015 Africa Zaire
2-JUN-2015 Asia Korea
2-JUN-2015 Asia Singapore
2-JUN-2015 Europe Germany
3-JUN-2015 Asia Hong Kong
[ SORTKEY COMPOUND ( date, region, country) ]
• Melhor para:
• Queries que usam a primeira coluna como filtro primário, e depois
outras colunas
• Pode acelerar joins e group bys
• Mais lenta para o VACUUM](https://image.slidesharecdn.com/datawarehousenanuvemdaaws-redshift-20160531-v2-160531221225/85/Webinar-Data-warehouse-na-nuvem-da-AWS-33-320.jpg)
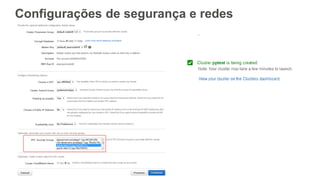
![Interleaved
• Peso igual para cada coluna
Date Region Country
2-JUN-2015 Africa Zaire
3-JUN-2015 Asia Singapore
2-JUN-2015 Asia Korea
2-JUN-2015 Europe Germany
3-JUN-2015 Asia Hong Kong
2-JUN-2015 Asia Korea
[ SORTKEY INTERLEAVED ( date, region, country) ]
• Melhor para:
• Queries que usam diferentes colunas como filtro
• Queries ficam mais rápidas quanto mais colunas são utilizadas
como filtro
• Mais lenta para o VACUUM](https://image.slidesharecdn.com/datawarehousenanuvemdaaws-redshift-20160531-v2-160531221225/85/Webinar-Data-warehouse-na-nuvem-da-AWS-34-320.jpg)

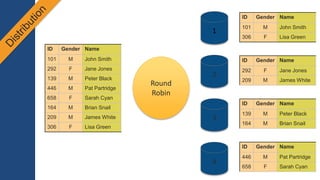
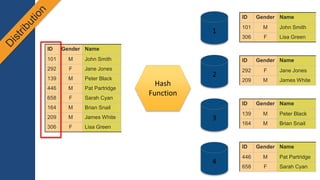
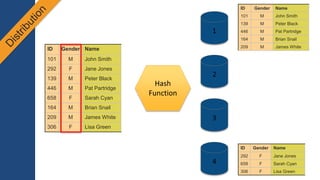


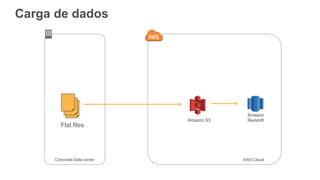
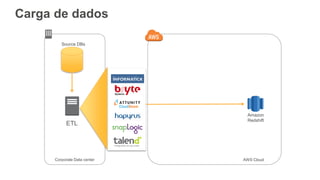
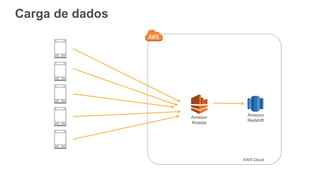
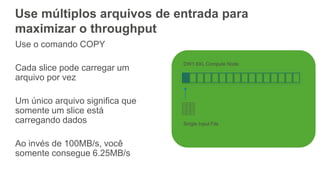
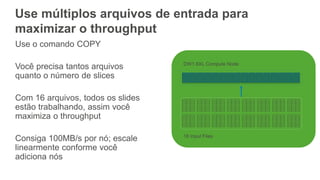

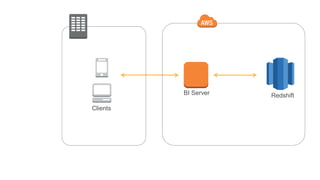
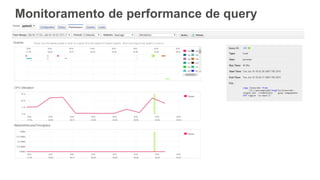
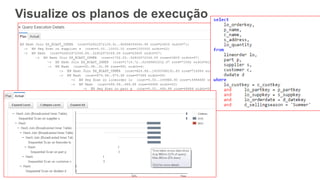


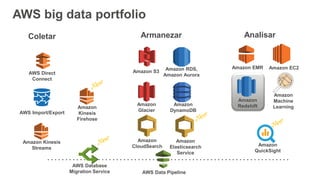
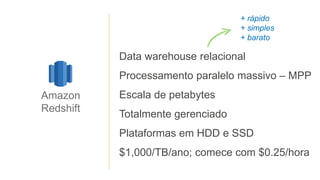
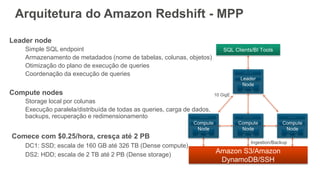
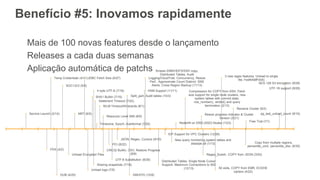
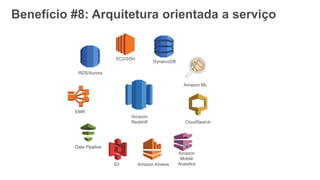
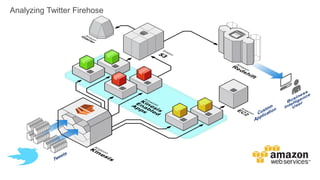
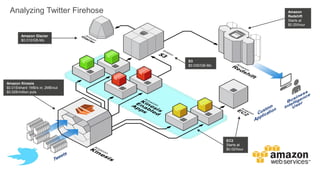
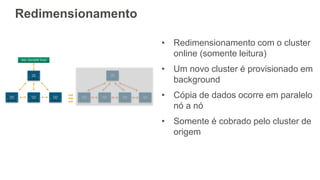
1) O documento apresenta os principais benefícios do Amazon Redshift como um data warehouse na nuvem gerenciado totalmente pela AWS, incluindo ser rápido, barato e seguro. 2) Apresenta casos de uso comuns do Redshift como análise de grandes volumes de dados de redes sociais e mostra como ele pode ser uma opção de custo efetiva. 3) Fornece orientações sobre como começar com o Redshift, incluindo provisionamento, modelagem e carga de dados para obter o máximo de desempenho.























































































