Transferir como PDF, PPTX




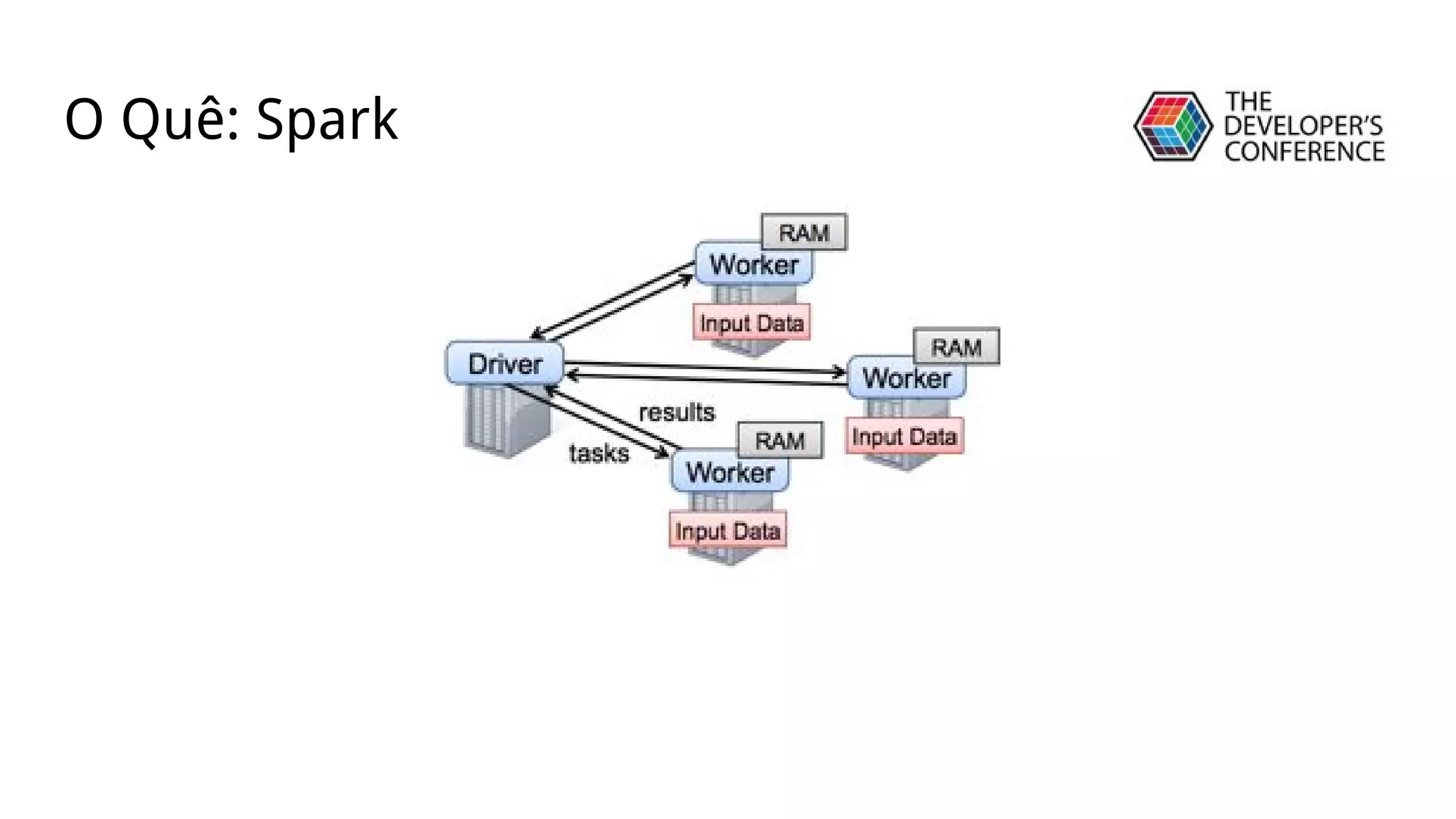
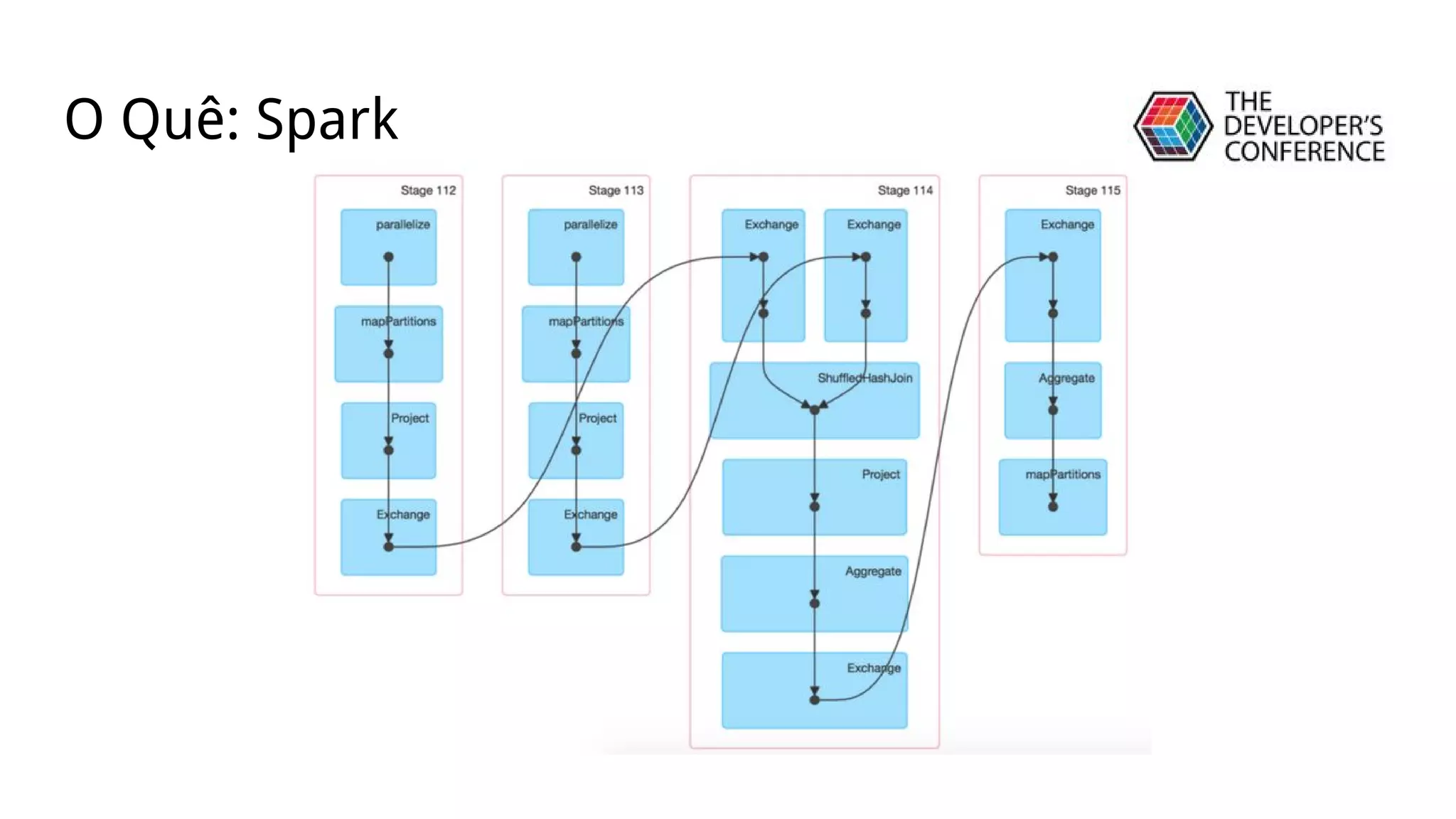

![● Clustering [KMeans, LDA]
● Classificação [SVM, Naïve Bayes, Random Forests]
● Regressão
● Extração de características
● Recomendação, timização de parâmetros, avaliação de
modelos...
Algoritmos](https://image.slidesharecdn.com/tdc-mllib-160720151630/75/TDC2016SP-Trilha-BigData-8-2048.jpg)
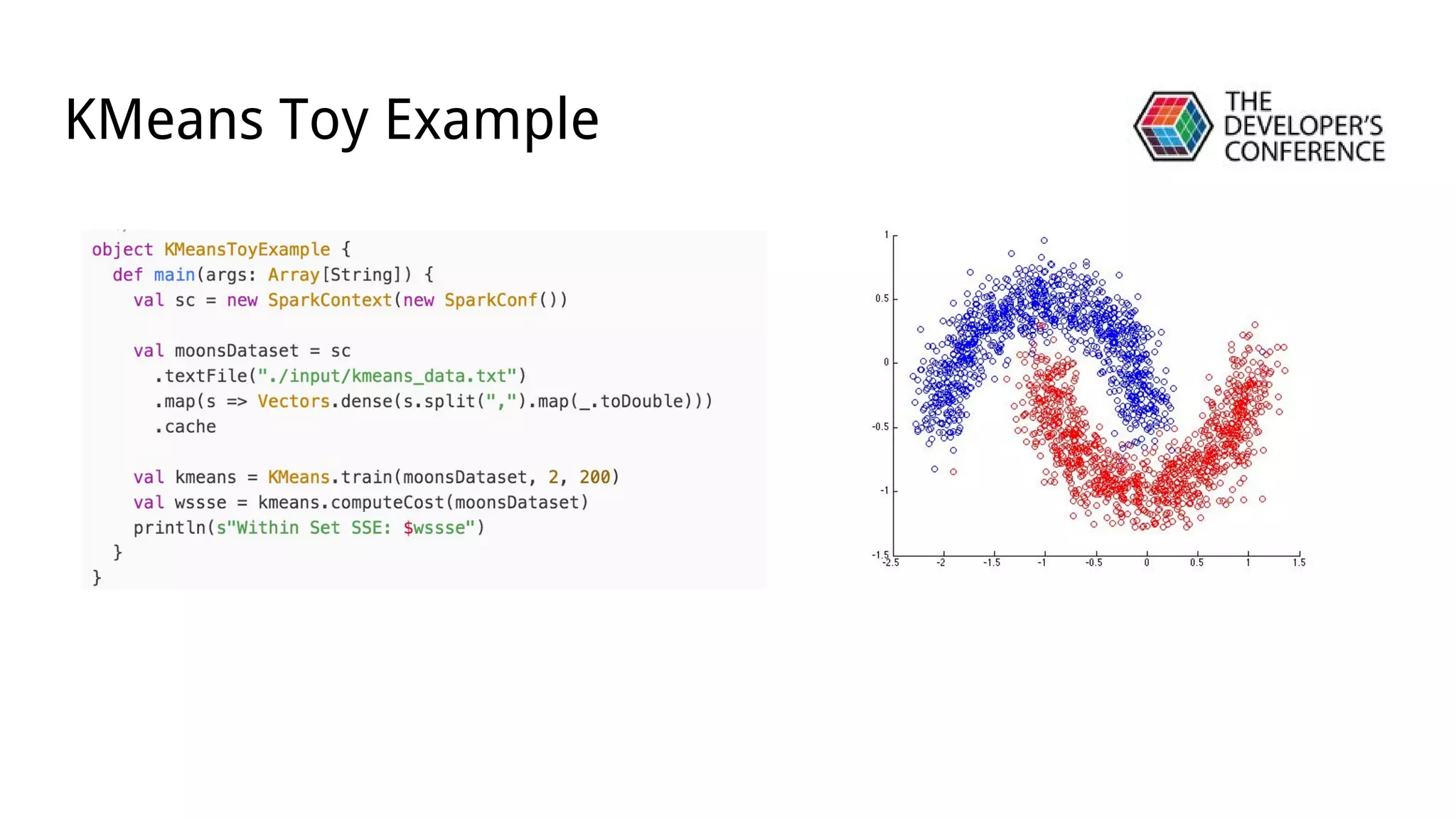





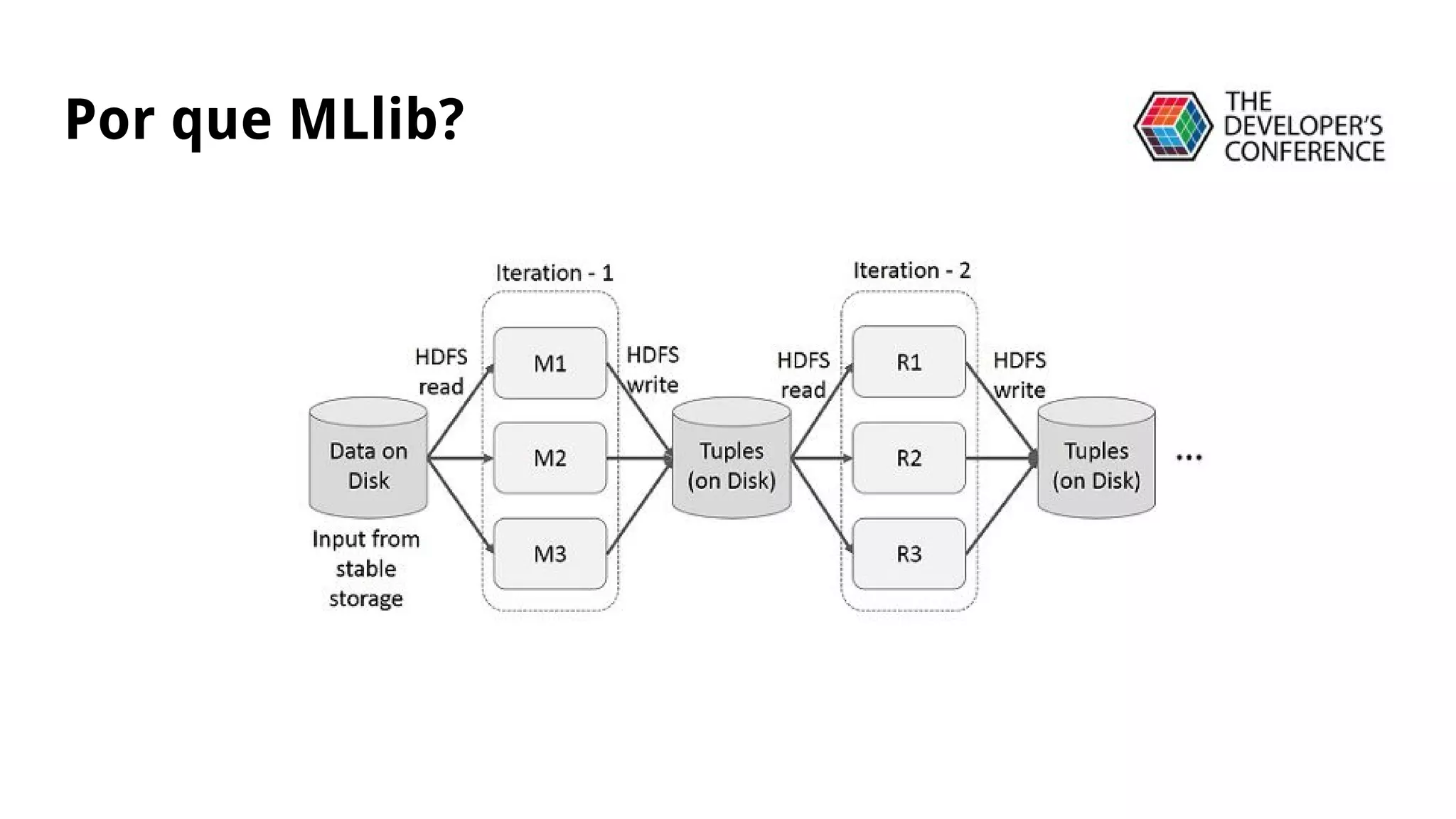
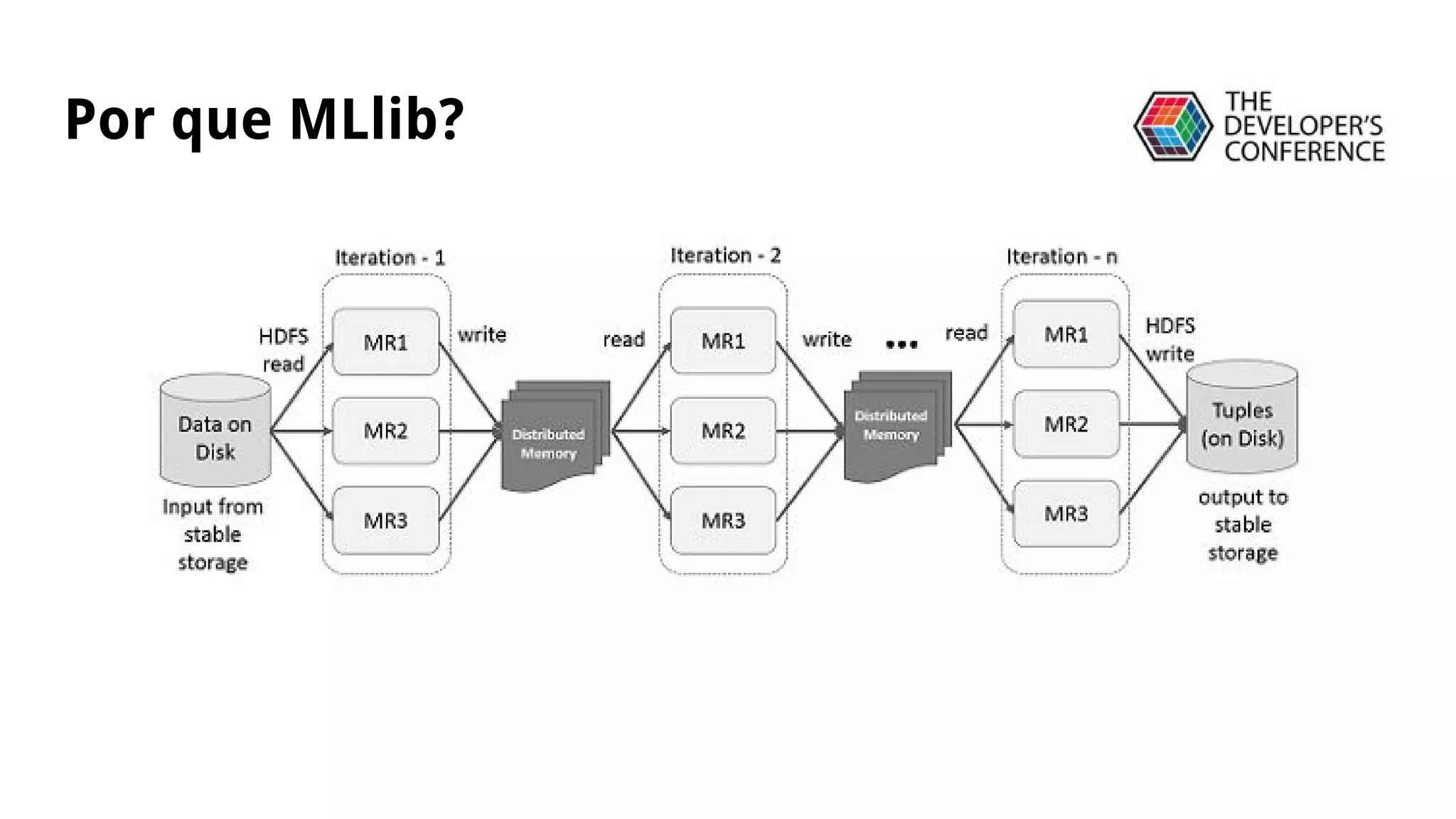
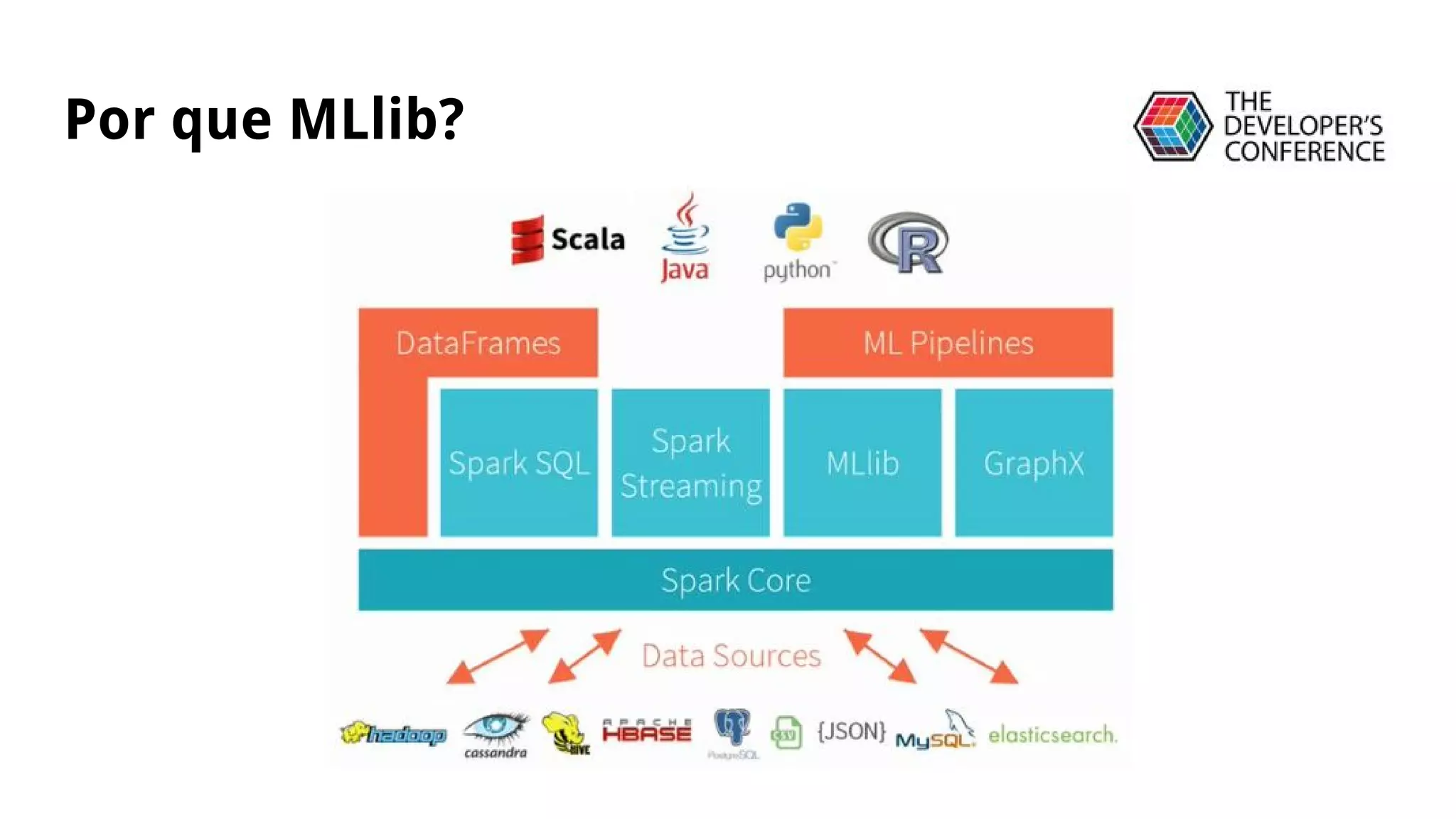




A apresentação discute a migração de modelos de classificação do Scikit-Learn para o MLlib do Apache Spark, incluindo uma demonstração de KMeans em um conjunto de dados pequeno, o uso de DataFrames e pipelines para classificação de spam em produção, e as vantagens do MLlib em relação ao Scikit-Learn para análise em larga escala.

























































