Baixar para ler offline









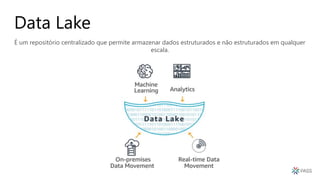



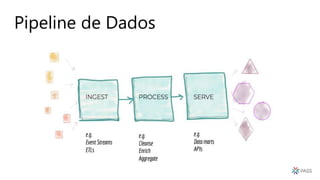

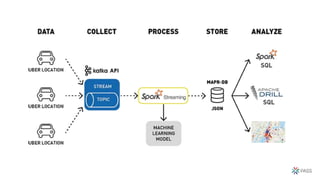
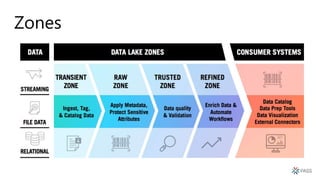
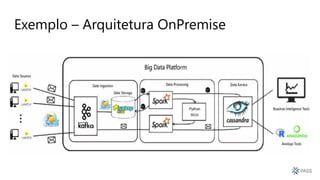
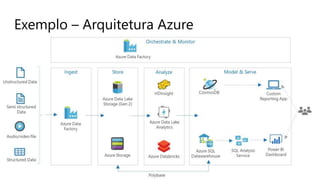
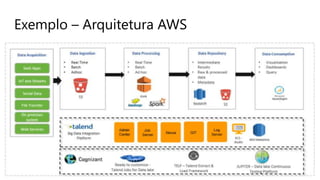


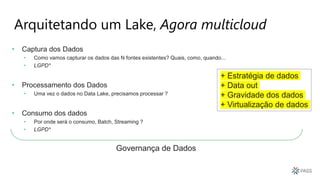

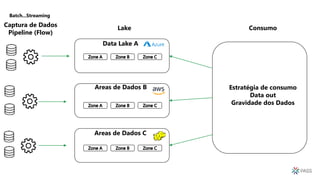
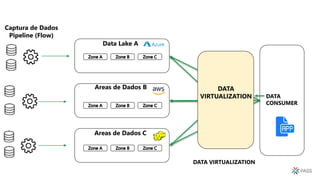
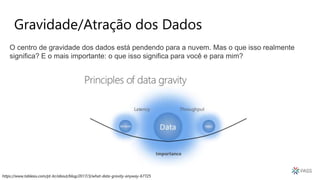
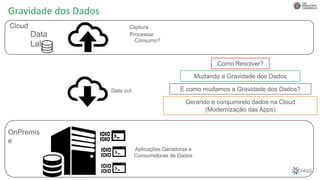


O documento discute a arquitetura de um Data Lake multicloud. Primeiro, explica os conceitos de Data Lake e as diferenças em relação a data warehouse. Em seguida, aborda os desafios na arquitetura de um Data Lake multicloud, incluindo a captura e processamento de dados de múltiplas fontes, o consumo dos dados e a governança. Por fim, apresenta exemplos de arquiteturas em nuvens diferentes e estratégias como virtualização e gravidade dos dados.















































![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)








