Baixado 52 vezes







![Classificação de SGBD NOSQL
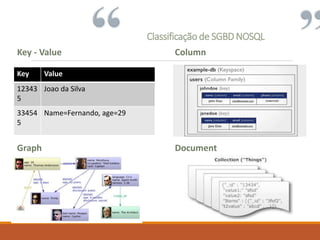
Os documentos são as unidades básicas
de armazenamento e estes não utilizam necessariamente
qualquer tipo de estruturação pré-definida
São baseados em JSON. (JavaScript Object Notation)
Exemplo:
{"user":{
"id": "123",
"name": "Emmanuel",
"addresses":[
{"city":"Paris"},
{"city":"Sao Paulo"}]}
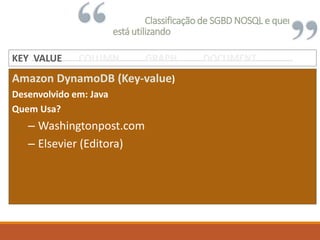
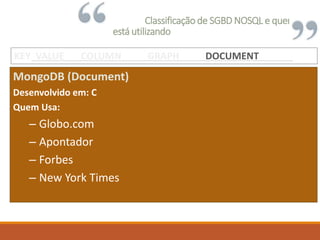
KEY VALUE COLUMN GRAPH DOCUMENTKEY VALUE COLUMN GRAPH DOCUMENTKEY VALUE COLUMN GRAPH DOCUMENTKEY VALUE COLUMN GRAPH DOCUMENT](https://image.slidesharecdn.com/nosqlumabreveintroduo-150210133505-conversion-gate01/85/NOSQL-uma-breve-introducao-8-320.jpg)
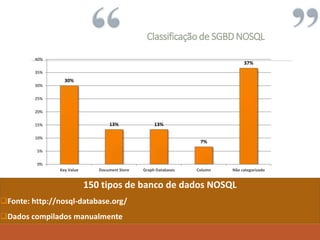







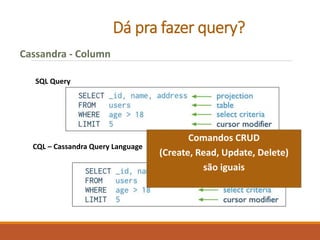
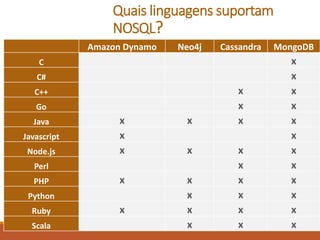

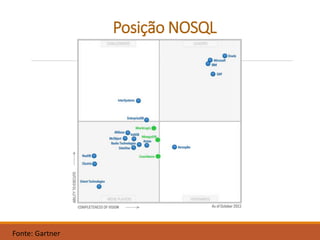
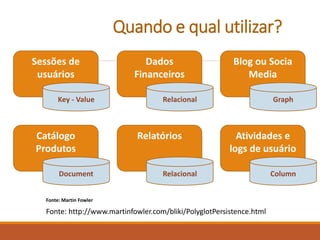



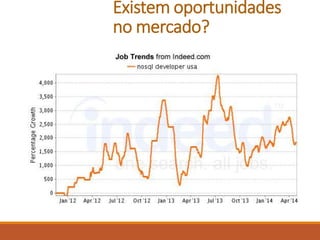
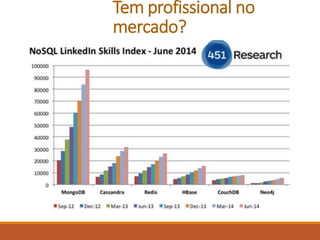




O documento apresenta uma introdução sobre Fernando Cunha e sua experiência profissional. Em seguida, fornece uma classificação dos principais tipos de bancos de dados NoSQL, exemplos e quais empresas os utilizam, abordando questões como suporte a queries e linguagens. Por fim, discute sobre as oportunidades do mercado NoSQL.







































































