Baixar para ler offline





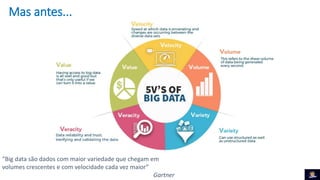

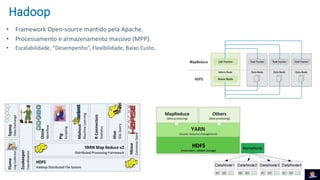





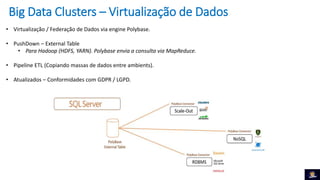
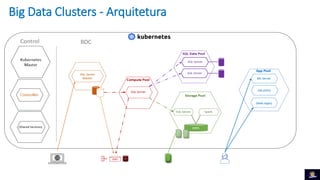
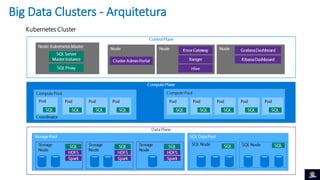
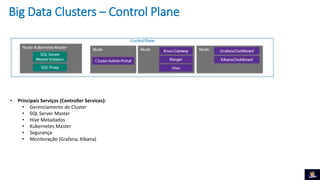

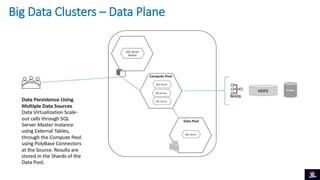
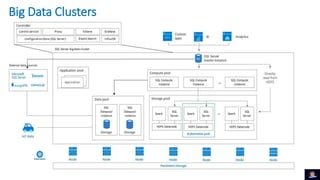
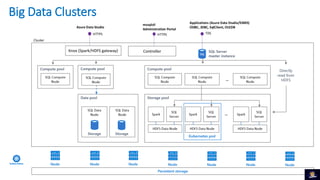
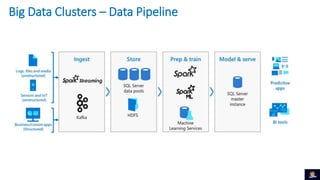
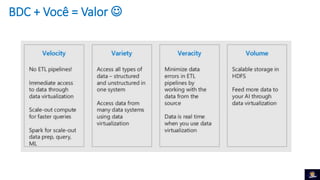



1) O documento discute Big Data Clusters no SQL Server 2019, que integra o Apache Spark e HDFS para fornecer uma plataforma de dados unificada capaz de lidar com dados estruturados e não estruturados. 2) Big Data Clusters fornecem flexibilidade para interagir com várias fontes de dados através de virtualização e federação via Polybase, além de criação de pipelines de dados e escalabilidade gerenciada por Kubernetes. 3) Uma demonstração é apresentada utilizando dados de políticos, eleitores e vota





































![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DTC21] André Marques - Jornada do Engenheiro de Dados](https://cdn.slidesharecdn.com/ss_thumbnails/jornadadoengenheirodedados-210317153718-thumbnail.jpg?width=640&height=640&fit=bounds)












