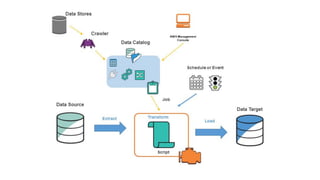
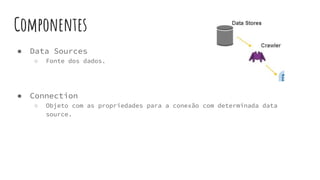
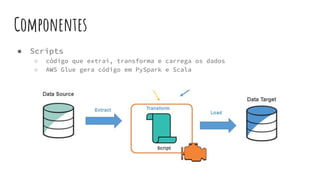
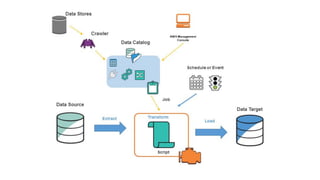
O AWS Glue é um serviço gerenciado de ETL que permite organizar, enriquecer, limpar e movimentar dados entre fontes de dados de forma serverless. Ele infere automaticamente a estrutura dos dados e permite definir jobs para extrair, transformar e carregar dados entre data stores como S3, RDS e DynamoDB.



















![[Webinar] AWS Storage Day - Português](https://cdn.slidesharecdn.com/ss_thumbnails/storageday-15052018pt-180518151634-thumbnail.jpg?width=640&height=640&fit=bounds)



































